 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrimination and Class Imbalance Aware Online Naive Bayes
Nov 09, 2022



Fairness-aware mining of massive data streams is a growing and challenging concern in the contemporary domain of machine learning. Many stream learning algorithms are used to replace humans at critical decision-making points e.g., hiring staff, assessing credit risk, etc. This calls for handling massive incoming information with minimum response delay while ensuring fair and high quality decisions. Recent discrimination-aware learning methods are optimized based on overall accuracy. However, the overall accuracy is biased in favor of the majority class; therefore, state-of-the-art methods mainly diminish discrimination by partially or completely ignoring the minority class. In this context, we propose a novel adaptation of Na\"ive Bayes to mitigate discrimination embedded in the streams while maintaining high predictive performance for both the majority and minority classes. Our proposed algorithm is simple, fast, and attains multi-objective optimization goals. To handle class imbalance and concept drifts, a dynamic instance weighting module is proposed, which gives more importance to recent instances and less importance to obsolete instances based on their membership in minority or majority class. We conducted experiments on a range of streaming and static datasets and deduced that our proposed methodology outperforms existing state-of-the-art fairness-aware methods in terms of both discrimination score and balanced accuracy.
AdaCC: Cumulative Cost-Sensitive Boosting for Imbalanced Classification
Sep 17, 2022


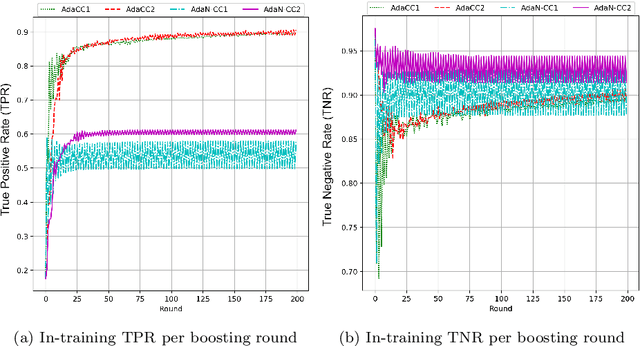
Class imbalance poses a major challenge for machine learning as most supervised learning models might exhibit bias towards the majority class and under-perform in the minority class. Cost-sensitive learning tackles this problem by treating the classes differently, formulated typically via a user-defined fixed misclassification cost matrix provided as input to the learner. Such parameter tuning is a challenging task that requires domain knowledge and moreover, wrong adjustments might lead to overall predictive performance deterioration. In this work, we propose a novel cost-sensitive boosting approach for imbalanced data that dynamically adjusts the misclassification costs over the boosting rounds in response to model's performance instead of using a fixed misclassification cost matrix. Our method, called AdaCC, is parameter-free as it relies on the cumulative behavior of the boosting model in order to adjust the misclassification costs for the next boosting round and comes with theoretical guarantees regarding the training error. Experiments on 27 real-world datasets from different domains with high class imbalance demonstrate the superiority of our method over 12 state-of-the-art cost-sensitive boosting approaches exhibiting consistent improvements in different measures, for instance, in the range of [0.3%-28.56%] for AUC, [3.4%-21.4%] for balanced accuracy, [4.8%-45%] for gmean and [7.4%-85.5%] for recall.
Parity-based Cumulative Fairness-aware Boosting
Jan 04, 2022
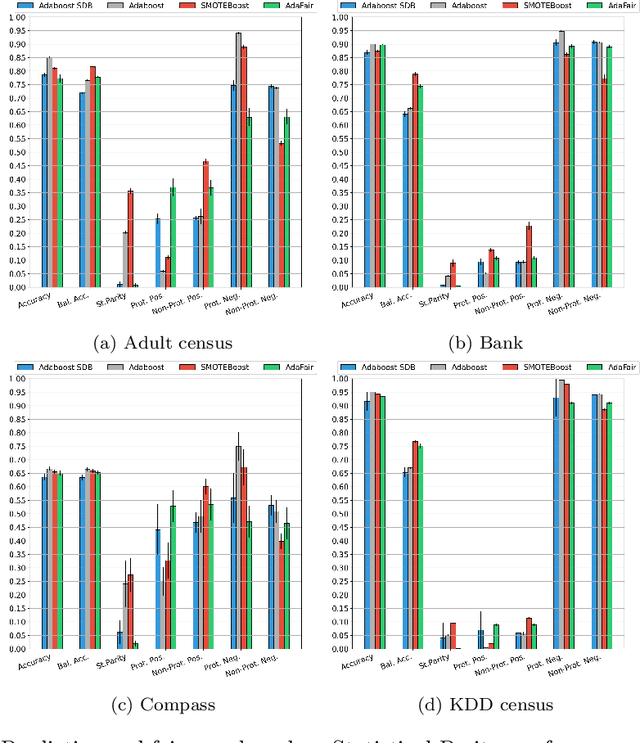
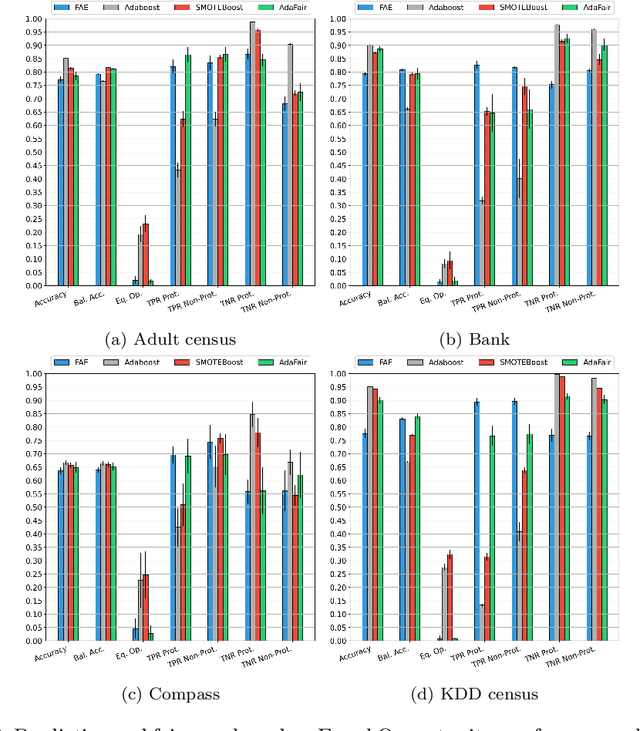
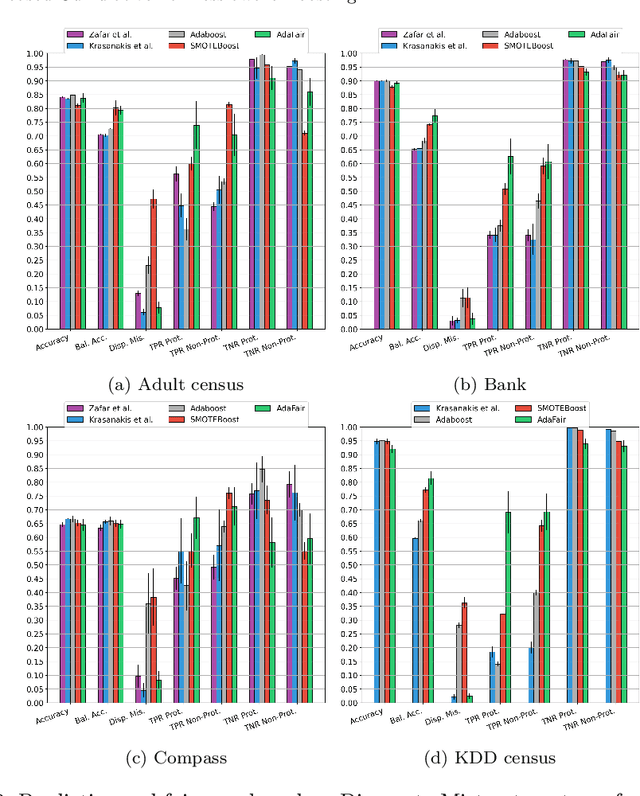
Data-driven AI systems can lead to discrimination on the basis of protected attributes like gender or race. One reason for this behavior is the encoded societal biases in the training data (e.g., females are underrepresented), which is aggravated in the presence of unbalanced class distributions (e.g., "granted" is the minority class). State-of-the-art fairness-aware machine learning approaches focus on preserving the \emph{overall} classification accuracy while improving fairness. In the presence of class-imbalance, such methods may further aggravate the problem of discrimination by denying an already underrepresented group (e.g., \textit{females}) the fundamental rights of equal social privileges (e.g., equal credit opportunity). To this end, we propose AdaFair, a fairness-aware boosting ensemble that changes the data distribution at each round, taking into account not only the class errors but also the fairness-related performance of the model defined cumulatively based on the partial ensemble. Except for the in-training boosting of the group discriminated over each round, AdaFair directly tackles imbalance during the post-training phase by optimizing the number of ensemble learners for balanced error performance (BER). AdaFair can facilitate different parity-based fairness notions and mitigate effectively discriminatory outcomes. Our experiments show that our approach can achieve parity in terms of statistical parity, equal opportunity, and disparate mistreatment while maintaining good predictive performance for all classes.
A survey on datasets for fairness-aware machine learning
Oct 01, 2021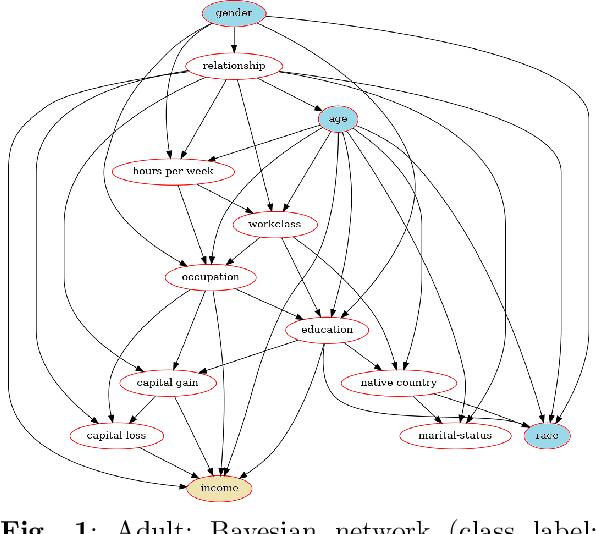
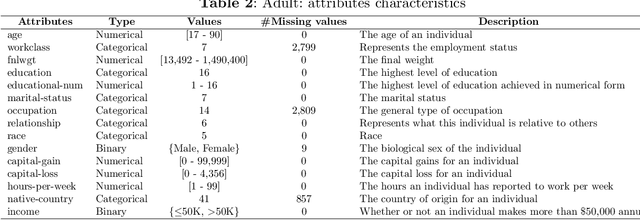
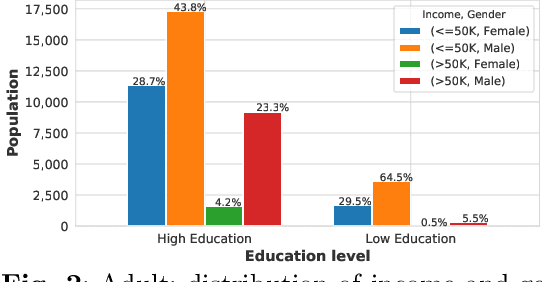
As decision-making increasingly relies on machine learning and (big) data, the issue of fairness in data-driven AI systems is receiving increasing attention from both research and industry. A large variety of fairness-aware machine learning solutions have been proposed which propose fairness-related interventions in the data, learning algorithms and/or model outputs. However, a vital part of proposing new approaches is evaluating them empirically on benchmark datasets that represent realistic and diverse settings. Therefore, in this paper, we overview real-world datasets used for fairness-aware machine learning. We focus on tabular data as the most common data representation for fairness-aware machine learning. We start our analysis by identifying relationships among the different attributes, particularly w.r.t. protected attributes and class attributes, using a Bayesian network. For a deeper understanding of bias and fairness in the datasets, we investigate the interesting relationships using exploratory analysis.
Online Fairness-Aware Learning with Imbalanced Data Streams
Aug 13, 2021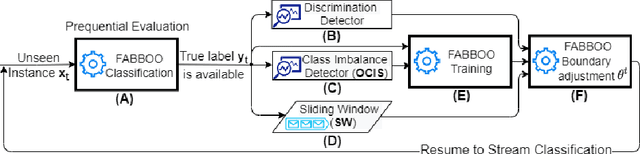

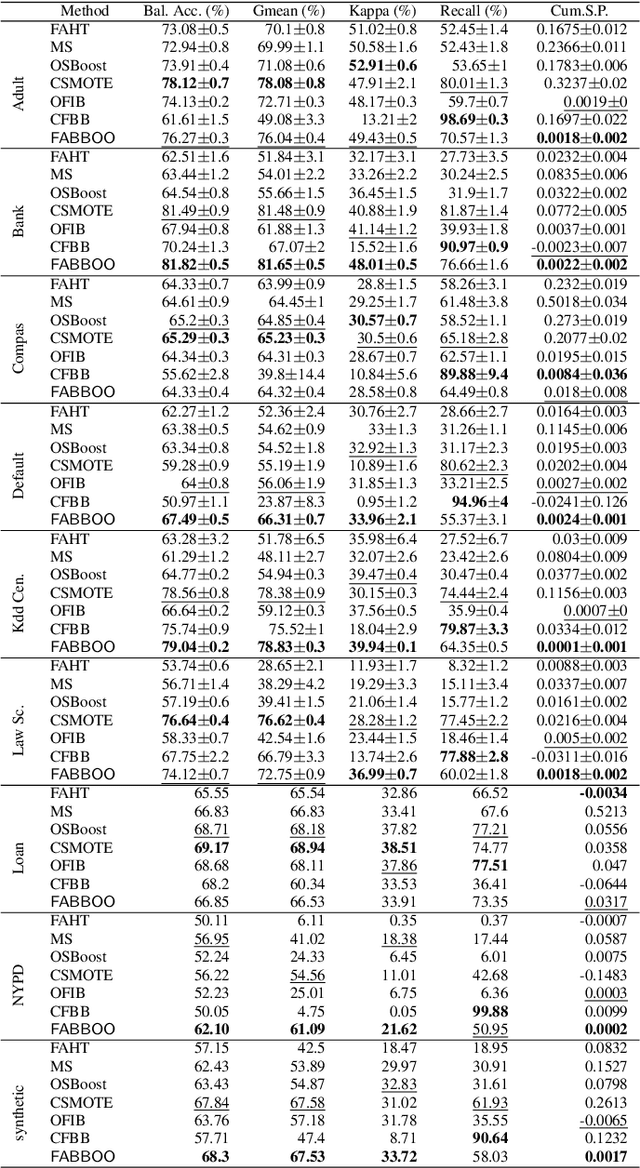
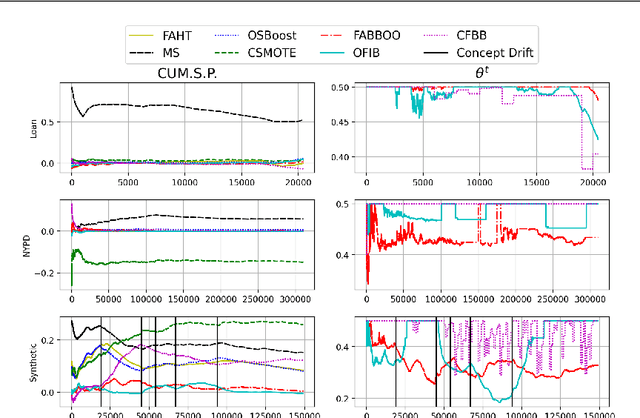
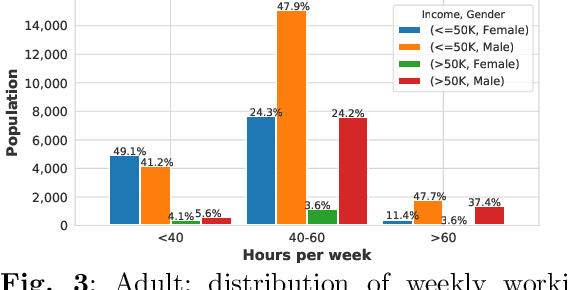
Data-driven learning algorithms are employed in many online applications, in which data become available over time, like network monitoring, stock price prediction, job applications, etc. The underlying data distribution might evolve over time calling for model adaptation as new instances arrive and old instances become obsolete. In such dynamic environments, the so-called data streams, fairness-aware learning cannot be considered as a one-off requirement, but rather it should comprise a continual requirement over the stream. Recent fairness-aware stream classifiers ignore the problem of class imbalance, which manifests in many real-life applications, and mitigate discrimination mainly because they "reject" minority instances at large due to their inability to effectively learn all classes. In this work, we propose \ours, an online fairness-aware approach that maintains a valid and fair classifier over the stream. \ours~is an online boosting approach that changes the training distribution in an online fashion by monitoring stream's class imbalance and tweaks its decision boundary to mitigate discriminatory outcomes over the stream. Experiments on 8 real-world and 1 synthetic datasets from different domains with varying class imbalance demonstrate the superiority of our method over state-of-the-art fairness-aware stream approaches with a range (relative) increase [11.2\%-14.2\%] in balanced accuracy, [22.6\%-31.8\%] in gmean, [42.5\%-49.6\%] in recall, [14.3\%-25.7\%] in kappa and [89.4\%-96.6\%] in statistical parity (fairness).
Multi-Fair Pareto Boosting
May 04, 2021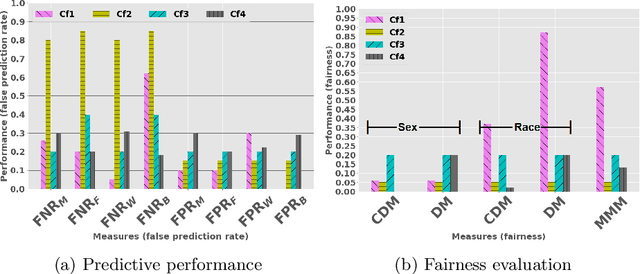

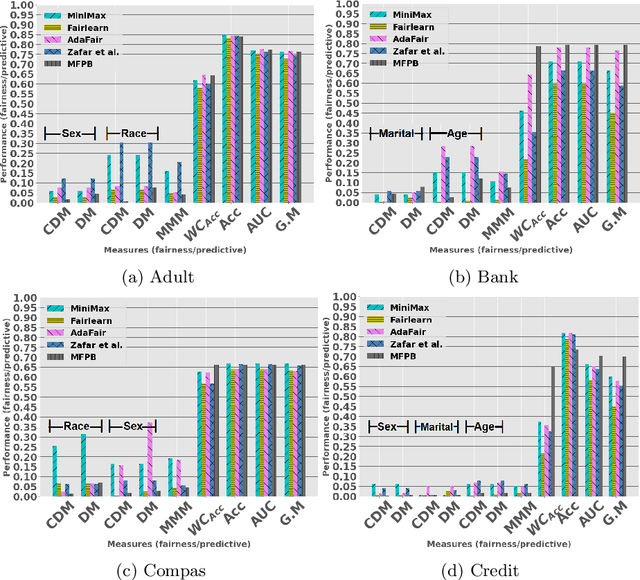

Fairness-aware machine learning for multiple protected at-tributes (referred to as multi-fairness hereafter) is receiving increasing attention as traditional single-protected attribute approaches cannot en-sure fairness w.r.t. other protected attributes. Existing methods, how-ever, still ignore the fact that datasets in this domain are often imbalanced, leading to unfair decisions towards the minority class. Thus, solutions are needed that achieve multi-fairness,accurate predictive performance in overall, and balanced performance across the different classes.To this end, we introduce a new fairness notion,Multi-Max Mistreatment(MMM), which measures unfairness while considering both (multi-attribute) protected group and class membership of instances. To learn an MMM-fair classifier, we propose a multi-objective problem formulation. We solve the problem using a boosting approach that in-training,incorporates multi-fairness treatment in the distribution update and post-training, finds multiple Pareto-optimal solutions; then uses pseudo-weight based decision making to select optimal solution(s) among accurate, balanced, and multi-attribute fair solutions
LSTM Based Sentiment Analysis for Cryptocurrency Prediction
Apr 03, 2021

Recent studies in big data analytics and natural language processing develop automatic techniques in analyzing sentiment in the social media information. In addition, the growing user base of social media and the high volume of posts also provide valuable sentiment information to predict the price fluctuation of the cryptocurrency. This research is directed to predicting the volatile price movement of cryptocurrency by analyzing the sentiment in social media and finding the correlation between them. While previous work has been developed to analyze sentiment in English social media posts, we propose a method to identify the sentiment of the Chinese social media posts from the most popular Chinese social media platform Sina-Weibo. We develop the pipeline to capture Weibo posts, describe the creation of the crypto-specific sentiment dictionary, and propose a long short-term memory (LSTM) based recurrent neural network along with the historical cryptocurrency price movement to predict the price trend for future time frames. The conducted experiments demonstrate the proposed approach outperforms the state of the art auto regressive based model by 18.5% in precision and 15.4% in recall.
A Data-driven Human Responsibility Management System
Dec 06, 2020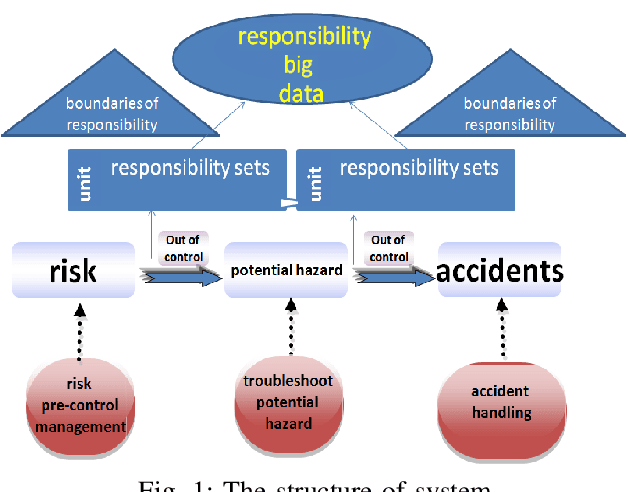

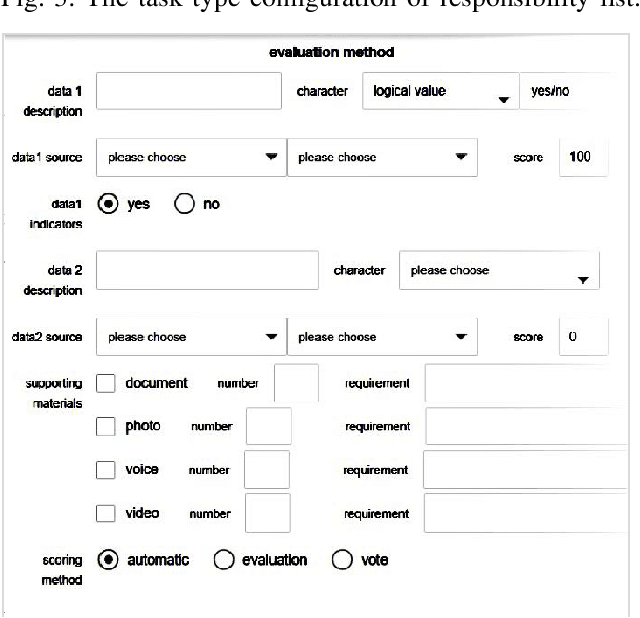
An ideal safe workplace is described as a place where staffs fulfill responsibilities in a well-organized order, potential hazardous events are being monitored in real-time, as well as the number of accidents and relevant damages are minimized. However, occupational-related death and injury are still increasing and have been highly attended in the last decades due to the lack of comprehensive safety management. A smart safety management system is therefore urgently needed, in which the staffs are instructed to fulfill responsibilities as well as automating risk evaluations and alerting staffs and departments when needed. In this paper, a smart system for safety management in the workplace based on responsibility big data analysis and the internet of things (IoT) are proposed. The real world implementation and assessment demonstrate that the proposed systems have superior accountability performance and improve the responsibility fulfillment through real-time supervision and self-reminder.
Using Machine Learning to Automate Mammogram Images Analysis
Dec 06, 2020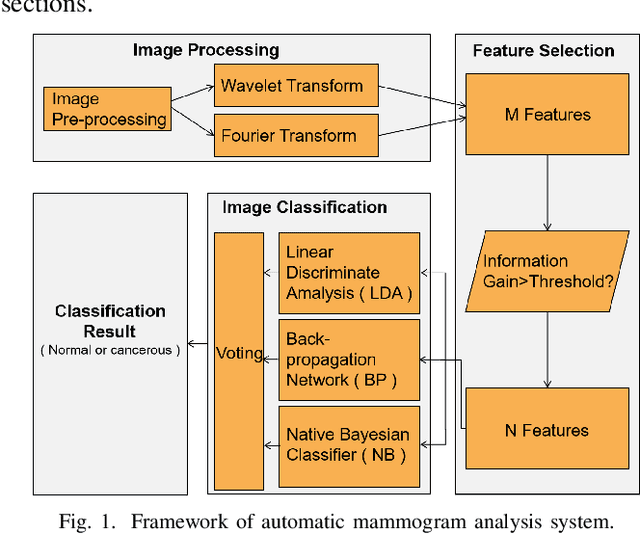
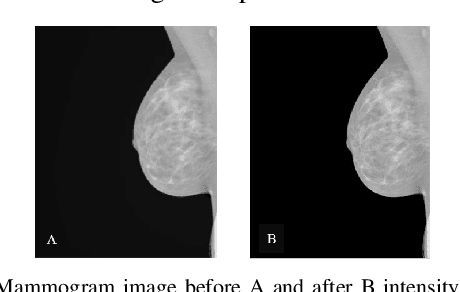
Breast cancer is the second leading cause of cancer-related death after lung cancer in women. Early detection of breast cancer in X-ray mammography is believed to have effectively reduced the mortality rate. However, a relatively high false positive rate and a low specificity in mammography technology still exist. In this work, a computer-aided automatic mammogram analysis system is proposed to process the mammogram images and automatically discriminate them as either normal or cancerous, consisting of three consecutive image processing, feature selection, and image classification stages. In designing the system, the discrete wavelet transforms (Daubechies 2, Daubechies 4, and Biorthogonal 6.8) and the Fourier cosine transform were first used to parse the mammogram images and extract statistical features. Then, an entropy-based feature selection method was implemented to reduce the number of features. Finally, different pattern recognition methods (including the Back-propagation Network, the Linear Discriminant Analysis, and the Naive Bayes Classifier) and a voting classification scheme were employed. The performance of each classification strategy was evaluated for sensitivity, specificity, and accuracy and for general performance using the Receiver Operating Curve. Our method is validated on the dataset from the Eastern Health in Newfoundland and Labrador of Canada. The experimental results demonstrated that the proposed automatic mammogram analysis system could effectively improve the classification performances.
FairNN- Conjoint Learning of Fair Representations for Fair Decisions
Apr 11, 2020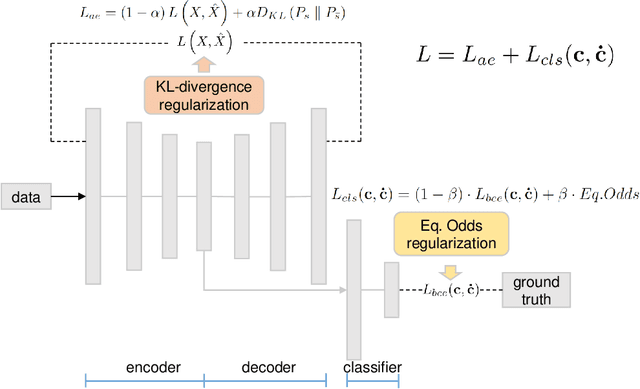

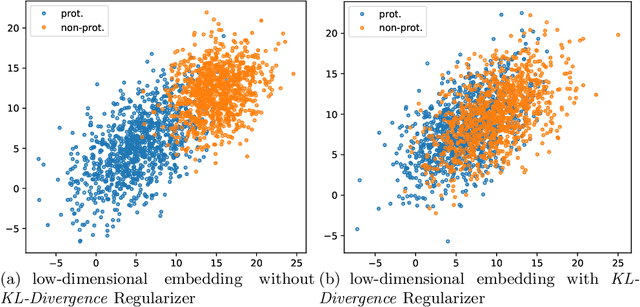
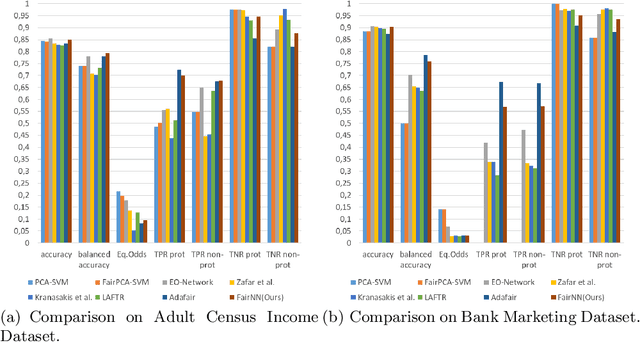
In this paper, we propose FairNN a neural network that performs joint feature representation and classification for fairness-aware learning. Our approach optimizes a multi-objective loss function in which (a) learns a fair representation by suppressing protected attributes (b) maintains the information content by minimizing a reconstruction loss and (c) allows for solving a classification task in a fair manner by minimizing the classification error and respecting the equalized odds-based fairness regularized. Our experiments on a variety of datasets demonstrate that such a joint approach is superior to separate treatment of unfairness in representation learning or supervised learning. Additionally, our regularizers can be adaptively weighted to balance the different components of the loss function, thus allowing for a very general framework for conjoint fair representation learning and decision making.