 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Policy Optimization for Token-Level Reward Models
May 29, 2025Process reward models (PRMs) provide more nuanced supervision compared to outcome reward models (ORMs) for optimizing policy models, positioning them as a promising approach to enhancing the capabilities of LLMs in complex reasoning tasks. Recent efforts have advanced PRMs from step-level to token-level granularity by integrating reward modeling into the training of generative models, with reward scores derived from token generation probabilities. However, the conflict between generative language modeling and reward modeling may introduce instability and lead to inaccurate credit assignments. To address this challenge, we revisit token-level reward assignment by decoupling reward modeling from language generation and derive a token-level reward model through the optimization of a discriminative policy, termed the Q-function Reward Model (Q-RM). We theoretically demonstrate that Q-RM explicitly learns token-level Q-functions from preference data without relying on fine-grained annotations. In our experiments, Q-RM consistently outperforms all baseline methods across various benchmarks. For example, when integrated into PPO/REINFORCE algorithms, Q-RM enhances the average Pass@1 score by 5.85/4.70 points on mathematical reasoning tasks compared to the ORM baseline, and by 4.56/5.73 points compared to the token-level PRM counterpart. Moreover, reinforcement learning with Q-RM significantly enhances training efficiency, achieving convergence 12 times faster than ORM on GSM8K and 11 times faster than step-level PRM on MATH. Code and data are available at https://github.com/homzer/Q-RM.
SPRec: Leveraging Self-Play to Debias Preference Alignment for Large Language Model-based Recommendations
Dec 12, 2024Large language models (LLMs) have attracted significant attention in recommendation systems. Current LLM-based recommender systems primarily rely on supervised fine-tuning (SFT) to train the model for recommendation tasks. However, relying solely on positive samples limits the model's ability to align with user satisfaction and expectations. To address this, researchers have introduced Direct Preference Optimization (DPO), which explicitly aligns recommendations with user preferences using offline preference ranking data. Despite its advantages, our theoretical analysis reveals that DPO inherently biases the model towards a few items, exacerbating the filter bubble issue and ultimately degrading user experience. In this paper, we propose SPRec, a novel self-play recommendation framework designed to mitigate over-recommendation and improve fairness without requiring additional data or manual intervention. In each self-play iteration, the model undergoes an SFT step followed by a DPO step, treating offline interaction data as positive samples and the predicted outputs from the previous iteration as negative samples. This effectively re-weights the DPO loss function using the model's logits, adaptively suppressing biased items. Extensive experiments on multiple real-world datasets demonstrate SPRec's effectiveness in enhancing recommendation accuracy and addressing fairness concerns.
Self-Evolution Fine-Tuning for Policy Optimization
Jun 16, 2024



The alignment of large language models (LLMs) is crucial not only for unlocking their potential in specific tasks but also for ensuring that responses meet human expectations and adhere to safety and ethical principles. Current alignment methodologies face considerable challenges. For instance, supervised fine-tuning (SFT) requires extensive, high-quality annotated samples, while reinforcement learning from human feedback (RLHF) is complex and often unstable. In this paper, we introduce self-evolution fine-tuning (SEFT) for policy optimization, with the aim of eliminating the need for annotated samples while retaining the stability and efficiency of SFT. SEFT first trains an adaptive reviser to elevate low-quality responses while maintaining high-quality ones. The reviser then gradually guides the policy's optimization by fine-tuning it with enhanced responses. One of the prominent features of this method is its ability to leverage unlimited amounts of unannotated data for policy optimization through supervised fine-tuning. Our experiments on AlpacaEval 2.0 and MT-Bench demonstrate the effectiveness of SEFT. We also provide a comprehensive analysis of its advantages over existing alignment techniques.
BlockPruner: Fine-grained Pruning for Large Language Models
Jun 15, 2024With the rapid growth in the size and complexity of large language models (LLMs), the costs associated with their training and inference have escalated significantly. Research indicates that certain layers in LLMs harbor substantial redundancy, and pruning these layers has minimal impact on the overall performance. While various layer pruning methods have been developed based on this insight, they generally overlook the finer-grained redundancies within the layers themselves. In this paper, we delve deeper into the architecture of LLMs and demonstrate that finer-grained pruning can be achieved by targeting redundancies in multi-head attention (MHA) and multi-layer perceptron (MLP) blocks. We propose a novel, training-free structured pruning approach called BlockPruner. Unlike existing layer pruning methods, BlockPruner segments each Transformer layer into MHA and MLP blocks. It then assesses the importance of these blocks using perplexity measures and applies a heuristic search for iterative pruning. We applied BlockPruner to LLMs of various sizes and architectures and validated its performance across a wide range of downstream tasks. Experimental results show that BlockPruner achieves more granular and effective pruning compared to state-of-the-art baselines.
Large Language Models with Retrieval-Augmented Generation for Zero-Shot Disease Phenotyping
Dec 11, 2023Identifying disease phenotypes from electronic health records (EHRs) is critical for numerous secondary uses. Manually encoding physician knowledge into rules is particularly challenging for rare diseases due to inadequate EHR coding, necessitating review of clinical notes. Large language models (LLMs) offer promise in text understanding but may not efficiently handle real-world clinical documentation. We propose a zero-shot LLM-based method enriched by retrieval-augmented generation and MapReduce, which pre-identifies disease-related text snippets to be used in parallel as queries for the LLM to establish diagnosis. We show that this method as applied to pulmonary hypertension (PH), a rare disease characterized by elevated arterial pressures in the lungs, significantly outperforms physician logic rules ($F_1$ score of 0.62 vs. 0.75). This method has the potential to enhance rare disease cohort identification, expanding the scope of robust clinical research and care gap identification.
Learning to Memorize Entailment and Discourse Relations for Persona-Consistent Dialogues
Jan 12, 2023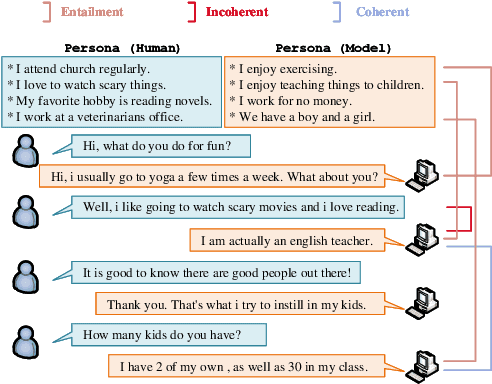
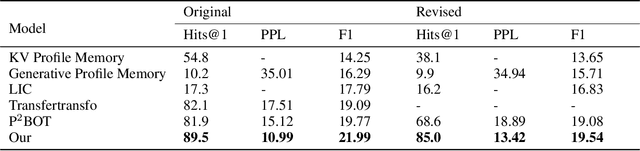
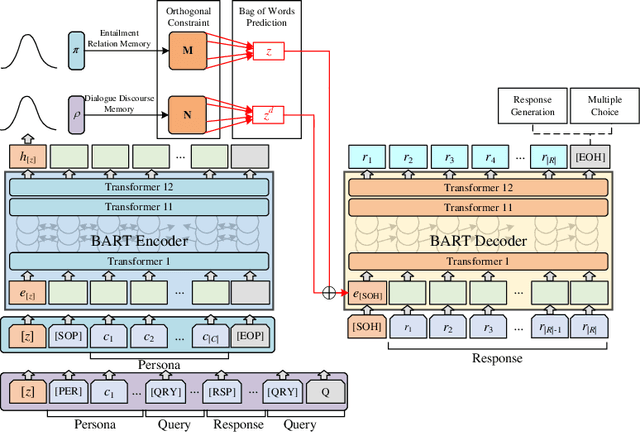

Maintaining engagement and consistency is particularly important in dialogue systems. Existing works have improved the performance of dialogue systems by intentionally learning interlocutor personas with sophisticated network structures. One issue with this approach is that it requires more personal corpora with annotations. Additionally, these models typically perform the next utterance prediction to generate a response but neglect the discourse coherence in the entire conversation. To address these issues, this study proposes a method of learning to memorize entailment and discourse relations for persona-consistent dialogue tasks. Entailment text pairs in natural language inference dataset were applied to learn latent entailment relations as external memories by premise-to-hypothesis generation task. Furthermore, an internal memory with a similar architecture was applied to the discourse information in the dialogue. Placing orthogonality restrictions on these two memory spaces ensures that the latent entailment relations remain dialogue-independent. Both memories collaborate to obtain entailment and discourse representation for the generation, allowing a deeper understanding of both consistency and coherence. Experiments on two large public datasets, PersonaChat and DSTC7-AVSD, demonstrated the effectiveness of the proposed method. Both automatic and human evaluations indicate that the proposed model outperforms several strong baselines in terms of both persona consistency and response coherence. Our source code is available at https://github.com/Chenrj233/LMEDR.
A Generic Knowledge Based Medical Diagnosis Expert System
Oct 26, 2021
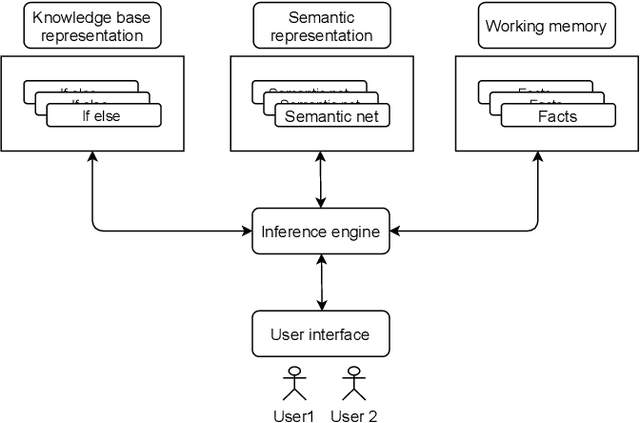
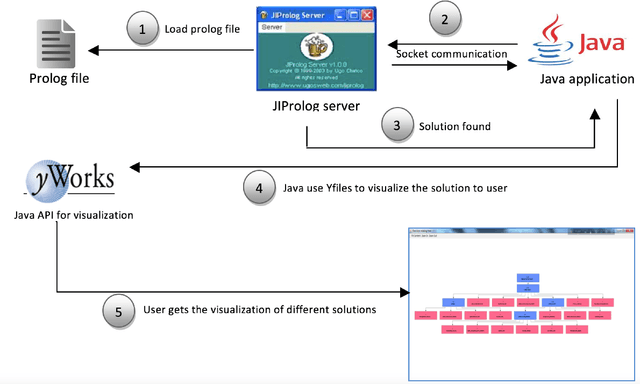
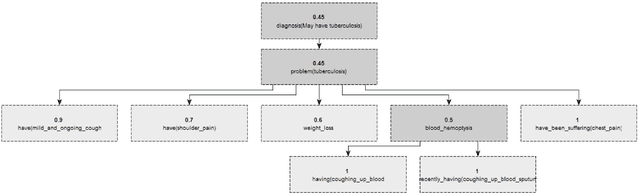
In this paper, we design and implement a generic medical knowledge based system (MKBS) for identifying diseases from several symptoms. In this system, some important aspects like knowledge bases system, knowledge representation, inference engine have been addressed. The system asks users different questions and inference engines will use the certainty factor to prune out low possible solutions. The proposed disease diagnosis system also uses a graphical user interface (GUI) to facilitate users to interact with the expert system. Our expert system is generic and flexible, which can be integrated with any rule bases system in disease diagnosis.
Responsibility Management through Responsibility Networks
Feb 23, 2021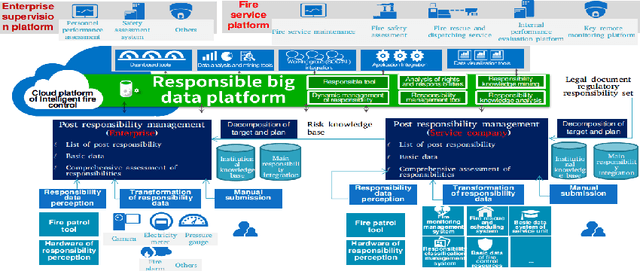
The safety management is critically important in the workplace. Unfortunately, responsibility issues therein such as inefficient supervision, poor evaluation and inadequate perception have not been properly addressed. To this end, in this paper, we deploy the Internet of Responsibilities (IoR) for responsibility management. Through the building of IoR framework, hierarchical responsibility management, automated responsibility evaluation at all level and efficient responsibility perception are achieved. The practical deployment of IoR system showed its effective responsibility management capability in various workplaces.
A Data-driven Human Responsibility Management System
Dec 06, 2020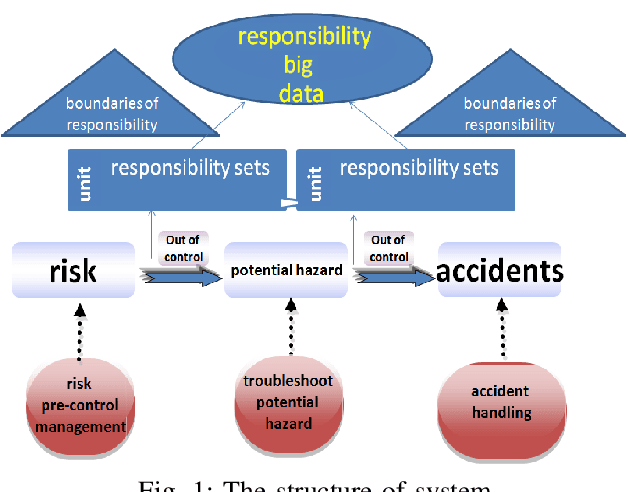
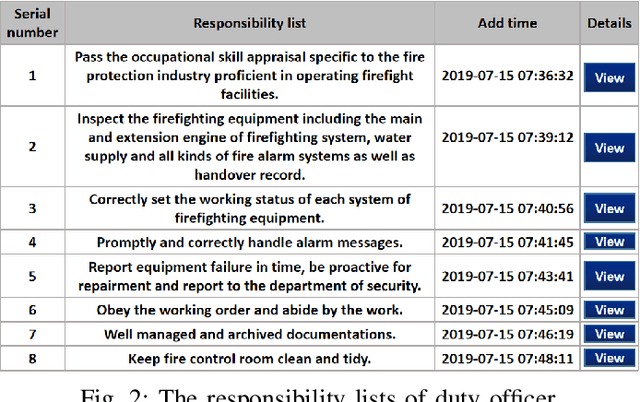

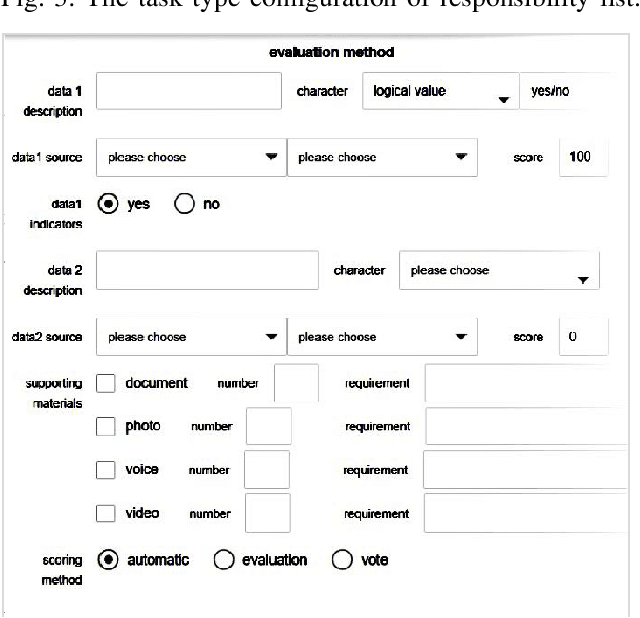
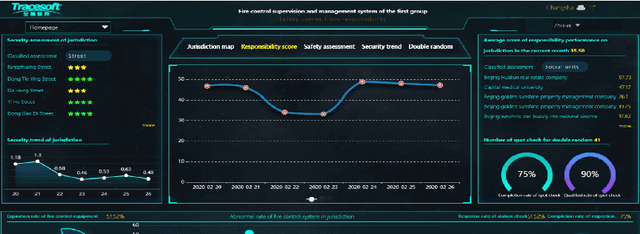
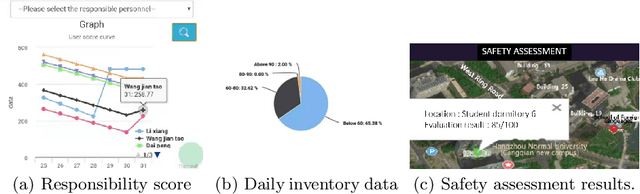
An ideal safe workplace is described as a place where staffs fulfill responsibilities in a well-organized order, potential hazardous events are being monitored in real-time, as well as the number of accidents and relevant damages are minimized. However, occupational-related death and injury are still increasing and have been highly attended in the last decades due to the lack of comprehensive safety management. A smart safety management system is therefore urgently needed, in which the staffs are instructed to fulfill responsibilities as well as automating risk evaluations and alerting staffs and departments when needed. In this paper, a smart system for safety management in the workplace based on responsibility big data analysis and the internet of things (IoT) are proposed. The real world implementation and assessment demonstrate that the proposed systems have superior accountability performance and improve the responsibility fulfillment through real-time supervision and self-reminder.