 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models with Retrieval-Augmented Generation for Zero-Shot Disease Phenotyping
Dec 11, 2023Identifying disease phenotypes from electronic health records (EHRs) is critical for numerous secondary uses. Manually encoding physician knowledge into rules is particularly challenging for rare diseases due to inadequate EHR coding, necessitating review of clinical notes. Large language models (LLMs) offer promise in text understanding but may not efficiently handle real-world clinical documentation. We propose a zero-shot LLM-based method enriched by retrieval-augmented generation and MapReduce, which pre-identifies disease-related text snippets to be used in parallel as queries for the LLM to establish diagnosis. We show that this method as applied to pulmonary hypertension (PH), a rare disease characterized by elevated arterial pressures in the lungs, significantly outperforms physician logic rules ($F_1$ score of 0.62 vs. 0.75). This method has the potential to enhance rare disease cohort identification, expanding the scope of robust clinical research and care gap identification.
Adapting Sequence to Sequence models for Text Normalization in Social Media
Apr 12, 2019
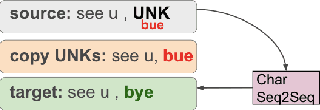
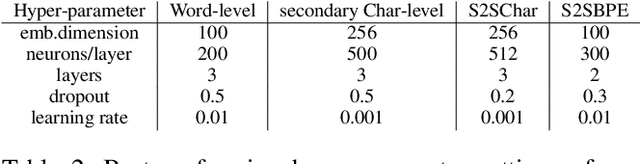

Social media offer an abundant source of valuable raw data, however informal writing can quickly become a bottleneck for many natural language processing (NLP) tasks. Off-the-shelf tools are usually trained on formal text and cannot explicitly handle noise found in short online posts. Moreover, the variety of frequently occurring linguistic variations presents several challenges, even for humans who might not be able to comprehend the meaning of such posts, especially when they contain slang and abbreviations. Text Normalization aims to transform online user-generated text to a canonical form. Current text normalization systems rely on string or phonetic similarity and classification models that work on a local fashion. We argue that processing contextual information is crucial for this task and introduce a social media text normalization hybrid word-character attention-based encoder-decoder model that can serve as a pre-processing step for NLP applications to adapt to noisy text in social media. Our character-based component is trained on synthetic adversarial examples that are designed to capture errors commonly found in online user-generated text. Experiments show that our model surpasses neural architectures designed for text normalization and achieves comparable performance with state-of-the-art related work.
METCC: METric learning for Confounder Control Making distance matter in high dimensional biological analysis
Dec 07, 2018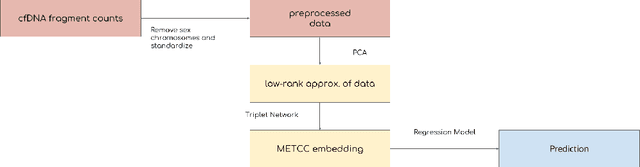

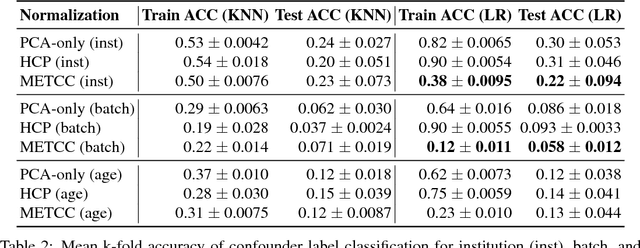
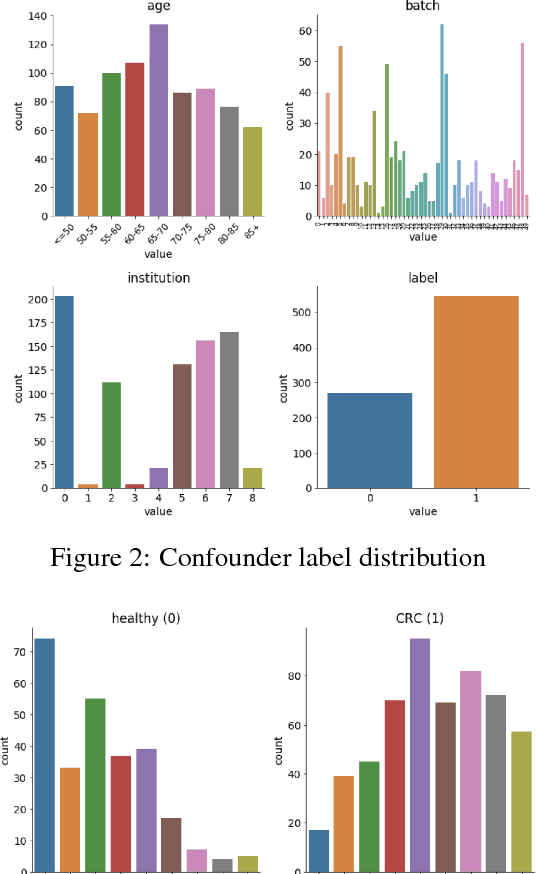
High-dimensional data acquired from biological experiments such as next generation sequencing are subject to a number of confounding effects. These effects include both technical effects, such as variation across batches from instrument noise or sample processing, or institution-specific differences in sample acquisition and physical handling, as well as biological effects arising from true but irrelevant differences in the biology of each sample, such as age biases in diseases. Prior work has used linear methods to adjust for such batch effects. Here, we apply contrastive metric learning by a non-linear triplet network to optimize the ability to distinguish biologically distinct sample classes in the presence of irrelevant technical and biological variation. Using whole-genome cell-free DNA data from 817 patients, we demonstrate that our approach, METric learning for Confounder Control (METCC), is able to match or exceed the classification performance achieved using a best-in-class linear method (HCP) or no normalization. Critically, results from METCC appear less confounded by irrelevant technical variables like institution and batch than those from other methods even without access to high quality metadata information required by many existing techniques; offering hope for improved generalization.