 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Sequence to Sequence models for Text Normalization in Social Media
Paper and Code

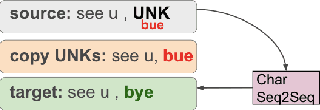
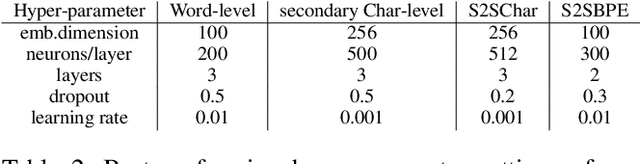

Social media offer an abundant source of valuable raw data, however informal writing can quickly become a bottleneck for many natural language processing (NLP) tasks. Off-the-shelf tools are usually trained on formal text and cannot explicitly handle noise found in short online posts. Moreover, the variety of frequently occurring linguistic variations presents several challenges, even for humans who might not be able to comprehend the meaning of such posts, especially when they contain slang and abbreviations. Text Normalization aims to transform online user-generated text to a canonical form. Current text normalization systems rely on string or phonetic similarity and classification models that work on a local fashion. We argue that processing contextual information is crucial for this task and introduce a social media text normalization hybrid word-character attention-based encoder-decoder model that can serve as a pre-processing step for NLP applications to adapt to noisy text in social media. Our character-based component is trained on synthetic adversarial examples that are designed to capture errors commonly found in online user-generated text. Experiments show that our model surpasses neural architectures designed for text normalization and achieves comparable performance with state-of-the-art related work.