 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Internet of Responsibilities-Connecting Human Responsibilities using Big Data and Blockchain
Dec 07, 2023



Accountability in the workplace is critically important and remains a challenging problem, especially with respect to workplace safety management. In this paper, we introduce a novel notion, the Internet of Responsibilities, for accountability management. Our method sorts through the list of responsibilities with respect to hazardous positions. The positions are interconnected using directed acyclic graphs (DAGs) indicating the hierarchy of responsibilities in the organization. In addition, the system detects and collects responsibilities, and represents risk areas in terms of the positions of the responsibility nodes. Finally, an automatic reminder and assignment system is used to enforce a strict responsibility control without human intervention. Using blockchain technology, we further extend our system with the capability to store, recover and encrypt responsibility data. We show that through the application of the Internet of Responsibility network model driven by Big Data, enterprise and government agencies can attain a highly secured and safe workplace. Therefore, our model offers a combination of interconnected responsibilities, accountability, monitoring, and safety which is crucial for the protection of employees and the success of organizations.
Attention Mechanism based Cognition-level Scene Understanding
Apr 19, 2022
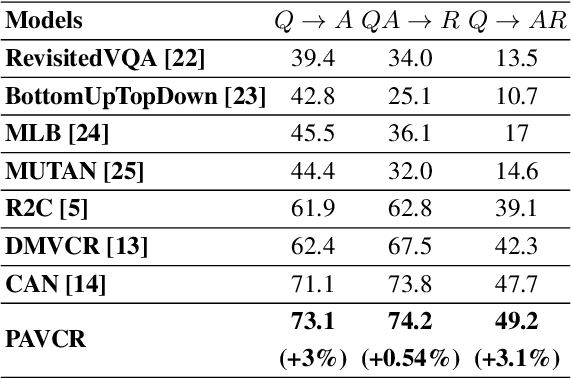
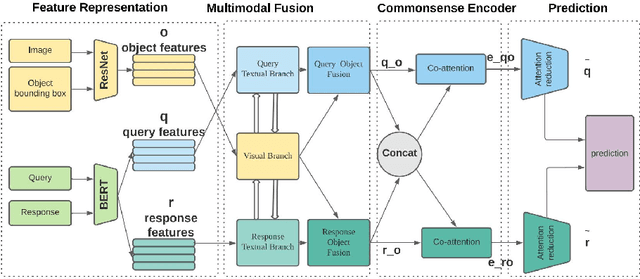

Given a question-image input, the Visual Commonsense Reasoning (VCR) model can predict an answer with the corresponding rationale, which requires inference ability from the real world. The VCR task, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge, is a cognition-level scene understanding task. The VCR task has aroused researchers' interest due to its wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and losing information in long sequences. In this paper, we propose a parallel attention-based cognitive VCR network PAVCR, which fuses visual-textual information efficiently and encodes semantic information in parallel to enable the model to capture rich information for cognition-level inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning.
A Generic Knowledge Based Medical Diagnosis Expert System
Oct 26, 2021
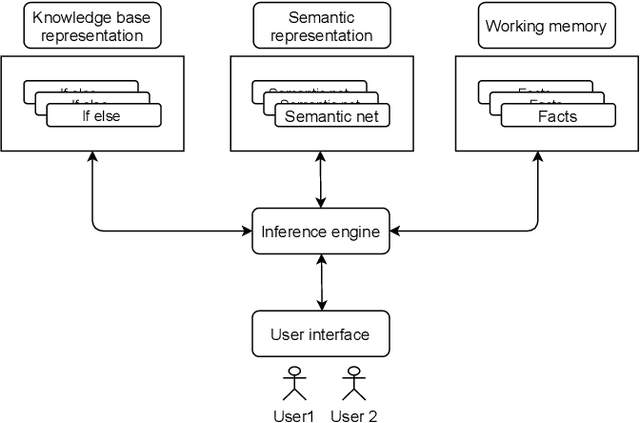
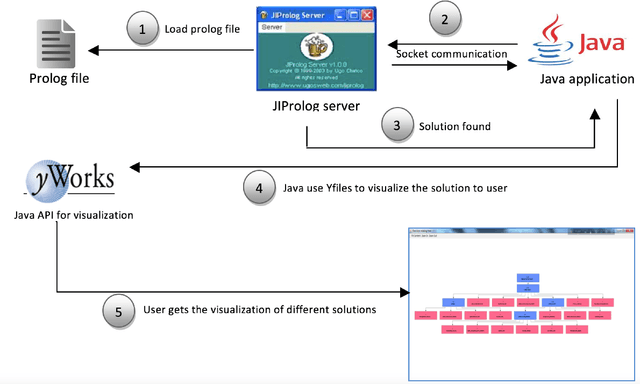
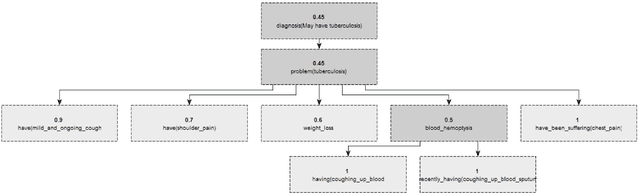
In this paper, we design and implement a generic medical knowledge based system (MKBS) for identifying diseases from several symptoms. In this system, some important aspects like knowledge bases system, knowledge representation, inference engine have been addressed. The system asks users different questions and inference engines will use the certainty factor to prune out low possible solutions. The proposed disease diagnosis system also uses a graphical user interface (GUI) to facilitate users to interact with the expert system. Our expert system is generic and flexible, which can be integrated with any rule bases system in disease diagnosis.
Interpretable Visual Understanding with Cognitive Attention Network
Aug 14, 2021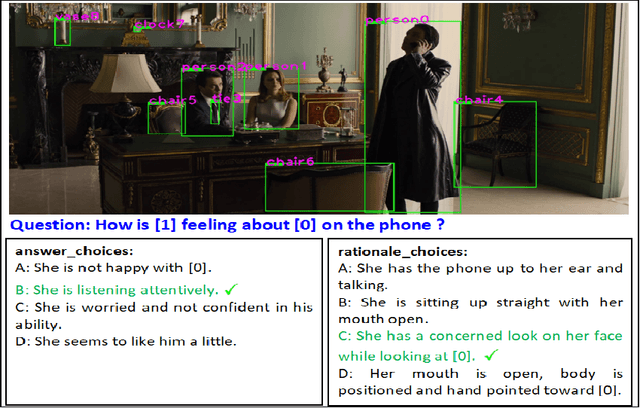
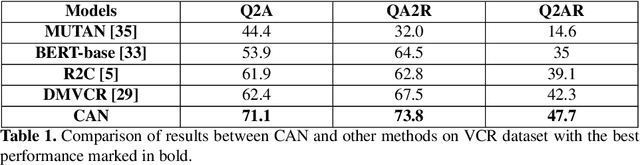
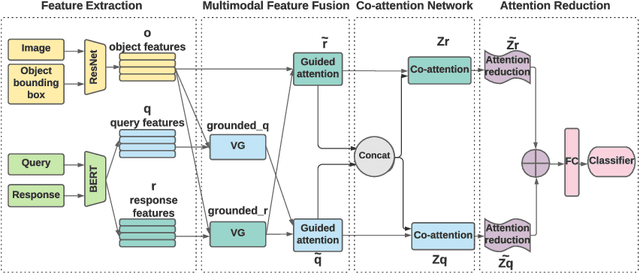
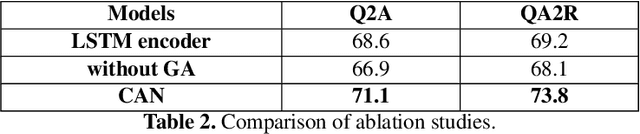
While image understanding on recognition-level has achieved remarkable advancements, reliable visual scene understanding requires comprehensive image understanding on recognition-level but also cognition-level, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge. In this paper, we propose a novel Cognitive Attention Network (CAN) for visual commonsense reasoning to achieve interpretable visual understanding. Specifically, we first introduce an image-text fusion module to fuse information from images and text collectively. Second, a novel inference module is designed to encode commonsense among image, query and response. Extensive experiments on large-scale Visual Commonsense Reasoning (VCR) benchmark dataset demonstrate the effectiveness of our approach. The implementation is publicly available at https://github.com/tanjatang/CAN
Cognitive Visual Commonsense Reasoning Using Dynamic Working Memory
Jul 10, 2021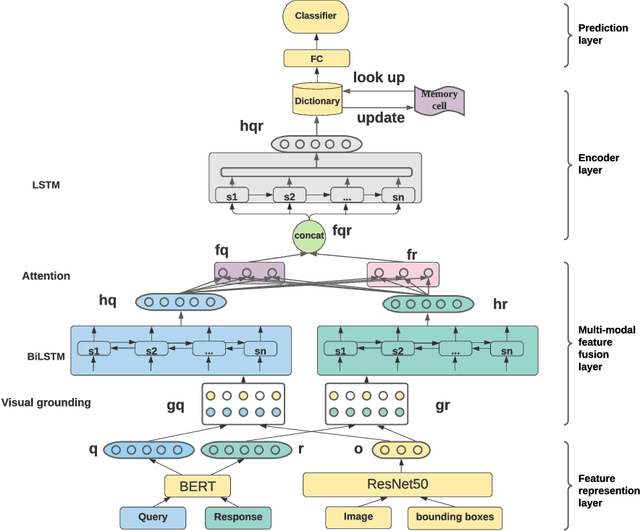
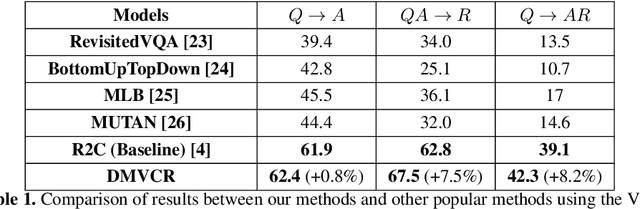

Visual Commonsense Reasoning (VCR) predicts an answer with corresponding rationale, given a question-image input. VCR is a recently introduced visual scene understanding task with a wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and prior knowledge. In this paper we propose a dynamic working memory based cognitive VCR network, which stores accumulated commonsense between sentences to provide prior knowledge for inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning. A Python implementation of our mechanism is publicly available at https://github.com/tanjatang/DMVCR
LSTM Based Sentiment Analysis for Cryptocurrency Prediction
Apr 03, 2021

Recent studies in big data analytics and natural language processing develop automatic techniques in analyzing sentiment in the social media information. In addition, the growing user base of social media and the high volume of posts also provide valuable sentiment information to predict the price fluctuation of the cryptocurrency. This research is directed to predicting the volatile price movement of cryptocurrency by analyzing the sentiment in social media and finding the correlation between them. While previous work has been developed to analyze sentiment in English social media posts, we propose a method to identify the sentiment of the Chinese social media posts from the most popular Chinese social media platform Sina-Weibo. We develop the pipeline to capture Weibo posts, describe the creation of the crypto-specific sentiment dictionary, and propose a long short-term memory (LSTM) based recurrent neural network along with the historical cryptocurrency price movement to predict the price trend for future time frames. The conducted experiments demonstrate the proposed approach outperforms the state of the art auto regressive based model by 18.5% in precision and 15.4% in recall.
Responsibility Management through Responsibility Networks
Feb 23, 2021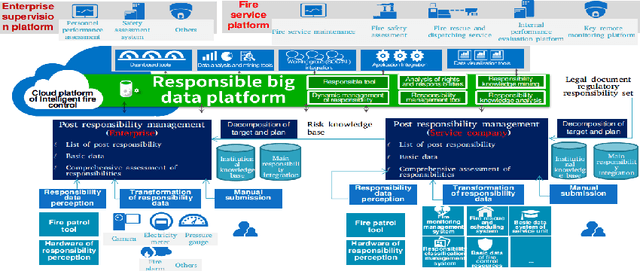
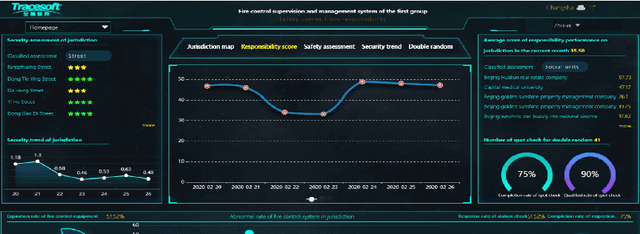
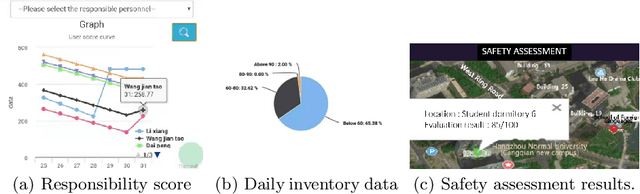
The safety management is critically important in the workplace. Unfortunately, responsibility issues therein such as inefficient supervision, poor evaluation and inadequate perception have not been properly addressed. To this end, in this paper, we deploy the Internet of Responsibilities (IoR) for responsibility management. Through the building of IoR framework, hierarchical responsibility management, automated responsibility evaluation at all level and efficient responsibility perception are achieved. The practical deployment of IoR system showed its effective responsibility management capability in various workplaces.
A Data-driven Human Responsibility Management System
Dec 06, 2020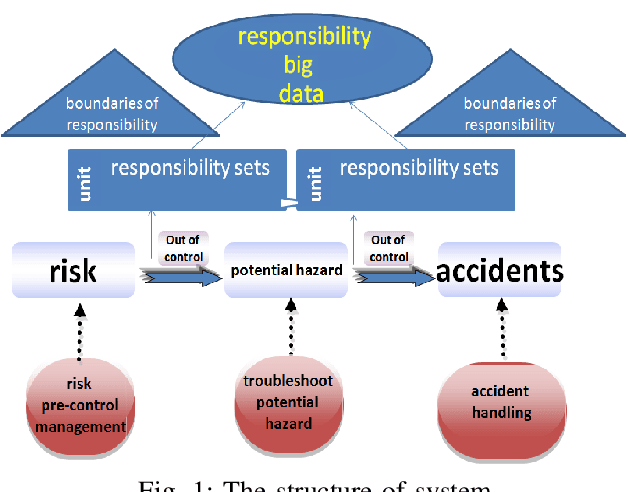
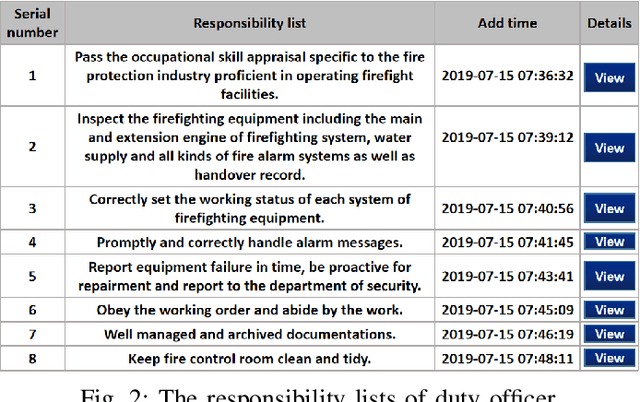

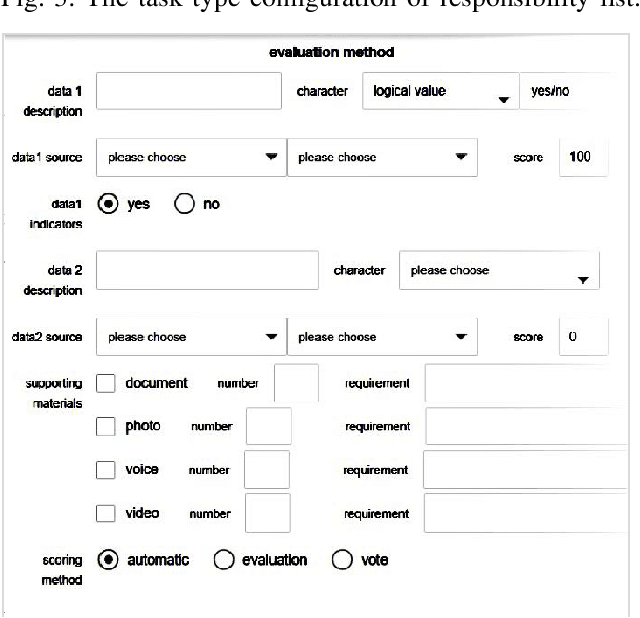
An ideal safe workplace is described as a place where staffs fulfill responsibilities in a well-organized order, potential hazardous events are being monitored in real-time, as well as the number of accidents and relevant damages are minimized. However, occupational-related death and injury are still increasing and have been highly attended in the last decades due to the lack of comprehensive safety management. A smart safety management system is therefore urgently needed, in which the staffs are instructed to fulfill responsibilities as well as automating risk evaluations and alerting staffs and departments when needed. In this paper, a smart system for safety management in the workplace based on responsibility big data analysis and the internet of things (IoT) are proposed. The real world implementation and assessment demonstrate that the proposed systems have superior accountability performance and improve the responsibility fulfillment through real-time supervision and self-reminder.
Using Machine Learning to Automate Mammogram Images Analysis
Dec 06, 2020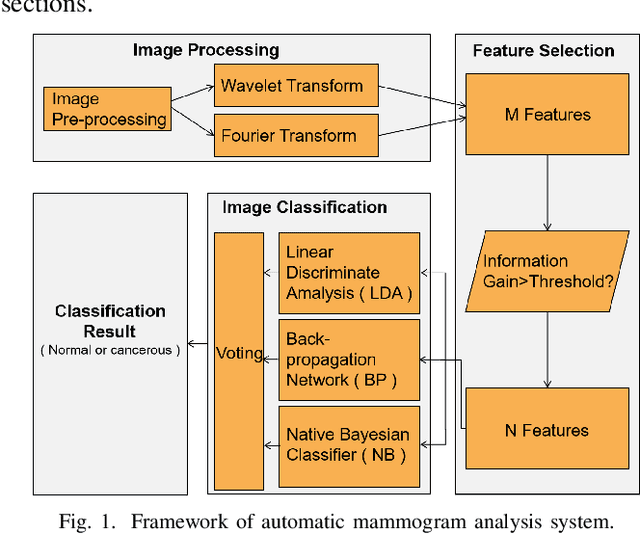
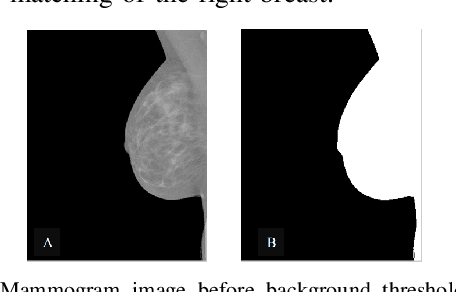
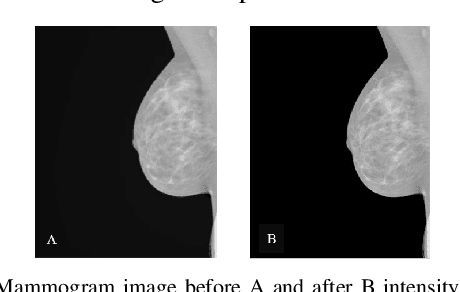
Breast cancer is the second leading cause of cancer-related death after lung cancer in women. Early detection of breast cancer in X-ray mammography is believed to have effectively reduced the mortality rate. However, a relatively high false positive rate and a low specificity in mammography technology still exist. In this work, a computer-aided automatic mammogram analysis system is proposed to process the mammogram images and automatically discriminate them as either normal or cancerous, consisting of three consecutive image processing, feature selection, and image classification stages. In designing the system, the discrete wavelet transforms (Daubechies 2, Daubechies 4, and Biorthogonal 6.8) and the Fourier cosine transform were first used to parse the mammogram images and extract statistical features. Then, an entropy-based feature selection method was implemented to reduce the number of features. Finally, different pattern recognition methods (including the Back-propagation Network, the Linear Discriminant Analysis, and the Naive Bayes Classifier) and a voting classification scheme were employed. The performance of each classification strategy was evaluated for sensitivity, specificity, and accuracy and for general performance using the Receiver Operating Curve. Our method is validated on the dataset from the Eastern Health in Newfoundland and Labrador of Canada. The experimental results demonstrated that the proposed automatic mammogram analysis system could effectively improve the classification performances.
Exploring Dynamic Context for Multi-path Trajectory Prediction
Nov 02, 2020
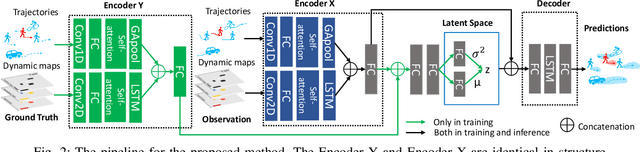
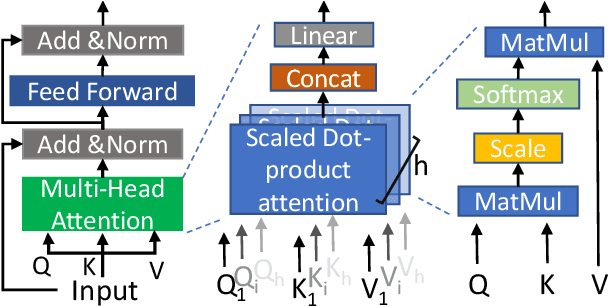
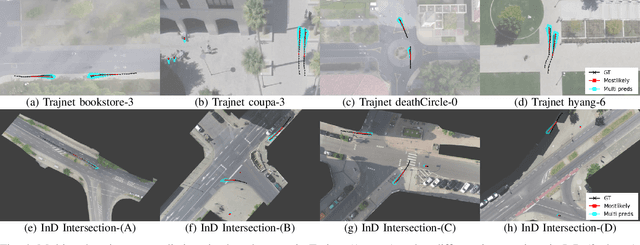
To accurately predict future positions of different agents in traffic scenarios is crucial for safely deploying intelligent autonomous systems in the real-world environment. However, it remains a challenge due to the behavior of a target agent being affected by other agents dynamically, and there being more than one socially possible paths the agent could take. In this paper, we propose a novel framework, named Dynamic Context Encoder Network (DCENet). In our framework, first, the spatial context between agents is explored by using self-attention architectures. Then, two LSTM encoders are trained to learn temporal context between steps by taking the observed trajectories and the extracted dynamic spatial context as input, respectively. The spatial-temporal context is encoded into a latent space using a Conditional Variational Auto-Encoder (CVAE) module. Finally, a set of future trajectories for each agent is predicted conditioned on the learned spatial-temporal context by sampling from the latent space, repeatedly. DCENet is evaluated on the largest and most challenging trajectory forecasting benchmark Trajnet and reports a new state-of-the-art performance. It also demonstrates superior performance evaluated on the benchmark InD for mixed traffic at intersections. A series of ablation studies are conducted to validate the effectiveness of each proposed module. Our code is available at https://github.com/wtliao/DCENet.