 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Analysis of Decentralized Federated Learning Deployments
Mar 14, 2025



The widespread adoption of smartphones and smart wearable devices has led to the widespread use of Centralized Federated Learning (CFL) for training powerful machine learning models while preserving data privacy. However, CFL faces limitations due to its overreliance on a central server, which impacts latency and system robustness. Decentralized Federated Learning (DFL) is introduced to address these challenges. It facilitates direct collaboration among participating devices without relying on a central server. Each device can independently connect with other devices and share model parameters. This work explores crucial factors influencing the convergence and generalization capacity of DFL models, emphasizing network topologies, non-IID data distribution, and training strategies. We first derive the convergence rate of different DFL model deployment strategies. Then, we comprehensively analyze various network topologies (e.g., linear, ring, star, and mesh) with different degrees of non-IID data and evaluate them over widely adopted machine learning models (e.g., classical, deep neural networks, and Large Language Models) and real-world datasets. The results reveal that models converge to the optimal one for IID data. However, the convergence rate is inversely proportional to the degree of non-IID data distribution. Our findings will serve as valuable guidelines for designing effective DFL model deployments in practical applications.
A Generalized Transformer-based Radio Link Failure Prediction Framework in 5G RANs
Jul 06, 2024



Radio link failure (RLF) prediction system in Radio Access Networks (RANs) is critical for ensuring seamless communication and meeting the stringent requirements of high data rates, low latency, and improved reliability in 5G networks. However, weather conditions such as precipitation, humidity, temperature, and wind impact these communication links. Usually, historical radio link Key Performance Indicators (KPIs) and their surrounding weather station observations are utilized for building learning-based RLF prediction models. However, such models must be capable of learning the spatial weather context in a dynamic RAN and effectively encoding time series KPIs with the weather observation data. Existing works fail to incorporate both of these essential design aspects of the prediction models. This paper fills the gap by proposing GenTrap, a novel RLF prediction framework that introduces a graph neural network (GNN)-based learnable weather effect aggregation module and employs state-of-the-art time series transformer as the temporal feature extractor for radio link failure prediction. The proposed aggregation method of GenTrap can be integrated into any existing prediction model to achieve better performance and generalizability. We evaluate GenTrap on two real-world datasets (rural and urban) with 2.6 million KPI data points and show that GenTrap offers a significantly higher F1-score (0.93 for rural and 0.79 for urban) compared to its counterparts while possessing generalization capability.
Root Cause Analysis of Anomalies in 5G RAN Using Graph Neural Network and Transformer
Jun 21, 2024



The emergence of 5G technology marks a significant milestone in developing telecommunication networks, enabling exciting new applications such as augmented reality and self-driving vehicles. However, these improvements bring an increased management complexity and a special concern in dealing with failures, as the applications 5G intends to support heavily rely on high network performance and low latency. Thus, automatic self-healing solutions have become effective in dealing with this requirement, allowing a learning-based system to automatically detect anomalies and perform Root Cause Analysis (RCA). However, there are inherent challenges to the implementation of such intelligent systems. First, there is a lack of suitable data for anomaly detection and RCA, as labelled data for failure scenarios is uncommon. Secondly, current intelligent solutions are tailored to LTE networks and do not fully capture the spatio-temporal characteristics present in the data. Considering this, we utilize a calibrated simulator, Simu5G, and generate open-source data for normal and failure scenarios. Using this data, we propose Simba, a state-of-the-art approach for anomaly detection and root cause analysis in 5G Radio Access Networks (RANs). We leverage Graph Neural Networks to capture spatial relationships while a Transformer model is used to learn the temporal dependencies of the data. We implement a prototype of Simba and evaluate it over multiple failures. The outcomes are compared against existing solutions to confirm the superiority of Simba.
A Calibrated and Automated Simulator for Innovations in 5G
Apr 16, 2024
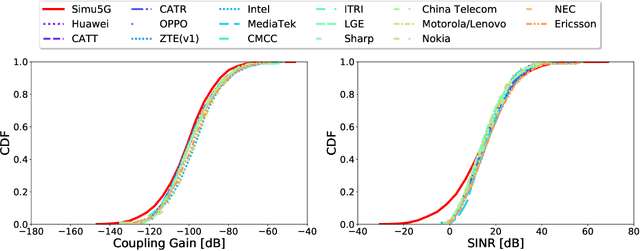
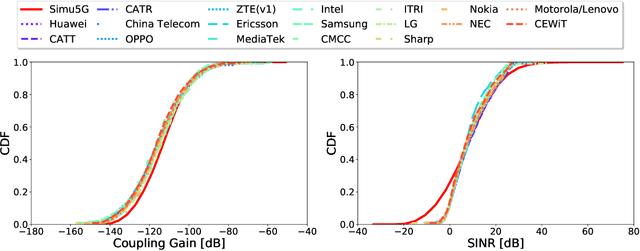
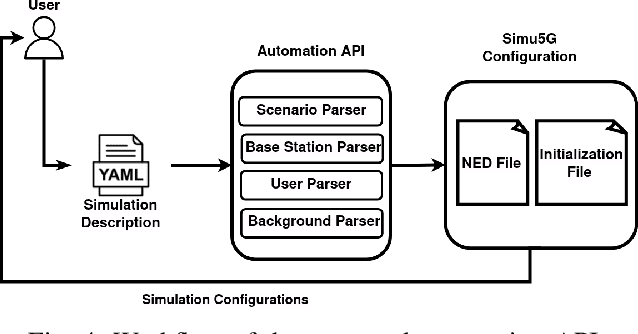
The rise of 5G deployments has created the environment for many emerging technologies to flourish. Self-driving vehicles, Augmented and Virtual Reality, and remote operations are examples of applications that leverage 5G networks' support for extremely low latency, high bandwidth, and increased throughput. However, the complex architecture of 5G hinders innovation due to the lack of accessibility to testbeds or realistic simulators with adequate 5G functionalities. Also, configuring and managing simulators are complex and time consuming. Finally, the lack of adequate representative data hinders the data-driven designs in 5G campaigns. Thus, we calibrated a system-level open-source simulator, Simu5G, following 3GPP guidelines to enable faster innovation in the 5G domain. Furthermore, we developed an API for automatic simulator configuration without knowing the underlying architectural details. Finally, we demonstrate the usage of the calibrated and automated simulator by developing an ML-based anomaly detection in a 5G Radio Access Network (RAN).
Learn to Compress (LtC): Efficient Learning-based Streaming Video Analytics
Jul 25, 2023



Video analytics are often performed as cloud services in edge settings, mainly to offload computation, and also in situations where the results are not directly consumed at the video sensors. Sending high-quality video data from the edge devices can be expensive both in terms of bandwidth and power use. In order to build a streaming video analytics pipeline that makes efficient use of these resources, it is therefore imperative to reduce the size of the video stream. Traditional video compression algorithms are unaware of the semantics of the video, and can be both inefficient and harmful for the analytics performance. In this paper, we introduce LtC, a collaborative framework between the video source and the analytics server, that efficiently learns to reduce the video streams within an analytics pipeline. Specifically, LtC uses the full-fledged analytics algorithm at the server as a teacher to train a lightweight student neural network, which is then deployed at the video source. The student network is trained to comprehend the semantic significance of various regions within the videos, which is used to differentially preserve the crucial regions in high quality while the remaining regions undergo aggressive compression. Furthermore, LtC also incorporates a novel temporal filtering algorithm based on feature-differencing to omit transmitting frames that do not contribute new information. Overall, LtC is able to use 28-35% less bandwidth and has up to 45% shorter response delay compared to recently published state of the art streaming frameworks while achieving similar analytics performance.
Preventing Discriminatory Decision-making in Evolving Data Streams
Feb 16, 2023
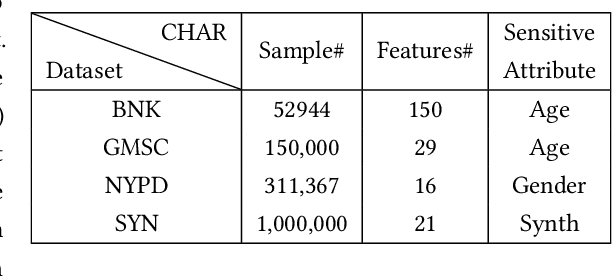


Bias in machine learning has rightly received significant attention over the last decade. However, most fair machine learning (fair-ML) work to address bias in decision-making systems has focused solely on the offline setting. Despite the wide prevalence of online systems in the real world, work on identifying and correcting bias in the online setting is severely lacking. The unique challenges of the online environment make addressing bias more difficult than in the offline setting. First, Streaming Machine Learning (SML) algorithms must deal with the constantly evolving real-time data stream. Second, they need to adapt to changing data distributions (concept drift) to make accurate predictions on new incoming data. Adding fairness constraints to this already complicated task is not straightforward. In this work, we focus on the challenges of achieving fairness in biased data streams while accounting for the presence of concept drift, accessing one sample at a time. We present Fair Sampling over Stream ($FS^2$), a novel fair rebalancing approach capable of being integrated with SML classification algorithms. Furthermore, we devise the first unified performance-fairness metric, Fairness Bonded Utility (FBU), to evaluate and compare the trade-off between performance and fairness of different bias mitigation methods efficiently. FBU simplifies the comparison of fairness-performance trade-offs of multiple techniques through one unified and intuitive evaluation, allowing model designers to easily choose a technique. Overall, extensive evaluations show our measures surpass those of other fair online techniques previously reported in the literature.
Towards Fair Machine Learning Software: Understanding and Addressing Model Bias Through Counterfactual Thinking
Feb 16, 2023The increasing use of Machine Learning (ML) software can lead to unfair and unethical decisions, thus fairness bugs in software are becoming a growing concern. Addressing these fairness bugs often involves sacrificing ML performance, such as accuracy. To address this issue, we present a novel counterfactual approach that uses counterfactual thinking to tackle the root causes of bias in ML software. In addition, our approach combines models optimized for both performance and fairness, resulting in an optimal solution in both aspects. We conducted a thorough evaluation of our approach on 10 benchmark tasks using a combination of 5 performance metrics, 3 fairness metrics, and 15 measurement scenarios, all applied to 8 real-world datasets. The conducted extensive evaluations show that the proposed method significantly improves the fairness of ML software while maintaining competitive performance, outperforming state-of-the-art solutions in 84.6% of overall cases based on a recent benchmarking tool.
Attention Mechanism based Cognition-level Scene Understanding
Apr 19, 2022
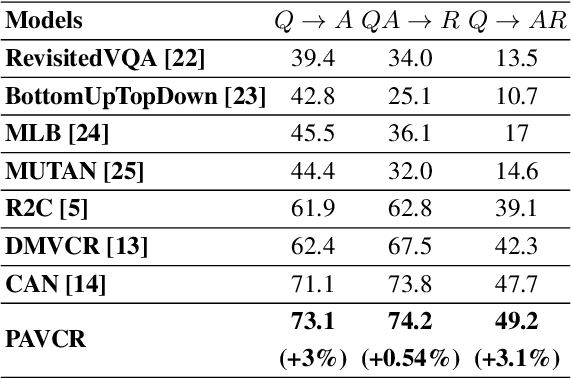
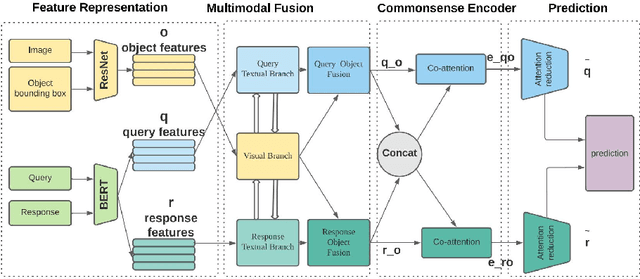

Given a question-image input, the Visual Commonsense Reasoning (VCR) model can predict an answer with the corresponding rationale, which requires inference ability from the real world. The VCR task, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge, is a cognition-level scene understanding task. The VCR task has aroused researchers' interest due to its wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and losing information in long sequences. In this paper, we propose a parallel attention-based cognitive VCR network PAVCR, which fuses visual-textual information efficiently and encodes semantic information in parallel to enable the model to capture rich information for cognition-level inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning.