 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMCO2: Advancing Accurate Carbon Footprint Prediction for LLM Inferences
Oct 03, 2024Throughout its lifecycle, a large language model (LLM) generates a substantially larger carbon footprint during inference than training. LLM inference requests vary in batch size, prompt length, and token generation number, while cloud providers employ different GPU types and quantities to meet diverse service-level objectives for accuracy and latency. It is crucial for both users and cloud providers to have a tool that quickly and accurately estimates the carbon impact of LLM inferences based on a combination of inference request and hardware configurations before execution. Estimating the carbon footprint of LLM inferences is more complex than training due to lower and highly variable model FLOPS utilization, rendering previous equation-based models inaccurate. Additionally, existing machine learning (ML) prediction methods either lack accuracy or demand extensive training data, as they inadequately handle the distinct prefill and decode phases, overlook hardware-specific features, and inefficiently sample uncommon inference configurations. We introduce \coo, a graph neural network (GNN)-based model that greatly improves the accuracy of LLM inference carbon footprint predictions compared to previous methods.
Inference Performance Optimization for Large Language Models on CPUs
Jul 10, 2024



Large language models (LLMs) have shown exceptional performance and vast potential across diverse tasks. However, the deployment of LLMs with high performance in low-resource environments has garnered significant attention in the industry. When GPU hardware resources are limited, we can explore alternative options on CPUs. To mitigate the financial burden and alleviate constraints imposed by hardware resources, optimizing inference performance is necessary. In this paper, we introduce an easily deployable inference performance optimization solution aimed at accelerating LLMs on CPUs. In this solution, we implement an effective way to reduce the KV cache size while ensuring precision. We propose a distributed inference optimization approach and implement it based on oneAPI Collective Communications Library. Furthermore, we propose optimization approaches for LLMs on CPU, and conduct tailored optimizations for the most commonly used models. The code is open-sourced at https://github.com/intel/xFasterTransformer.
Preventing Discriminatory Decision-making in Evolving Data Streams
Feb 16, 2023
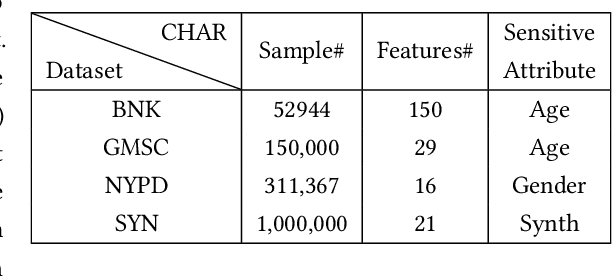


Bias in machine learning has rightly received significant attention over the last decade. However, most fair machine learning (fair-ML) work to address bias in decision-making systems has focused solely on the offline setting. Despite the wide prevalence of online systems in the real world, work on identifying and correcting bias in the online setting is severely lacking. The unique challenges of the online environment make addressing bias more difficult than in the offline setting. First, Streaming Machine Learning (SML) algorithms must deal with the constantly evolving real-time data stream. Second, they need to adapt to changing data distributions (concept drift) to make accurate predictions on new incoming data. Adding fairness constraints to this already complicated task is not straightforward. In this work, we focus on the challenges of achieving fairness in biased data streams while accounting for the presence of concept drift, accessing one sample at a time. We present Fair Sampling over Stream ($FS^2$), a novel fair rebalancing approach capable of being integrated with SML classification algorithms. Furthermore, we devise the first unified performance-fairness metric, Fairness Bonded Utility (FBU), to evaluate and compare the trade-off between performance and fairness of different bias mitigation methods efficiently. FBU simplifies the comparison of fairness-performance trade-offs of multiple techniques through one unified and intuitive evaluation, allowing model designers to easily choose a technique. Overall, extensive evaluations show our measures surpass those of other fair online techniques previously reported in the literature.
Deploying Deep Ranking Models for Search Verticals
Jun 06, 2018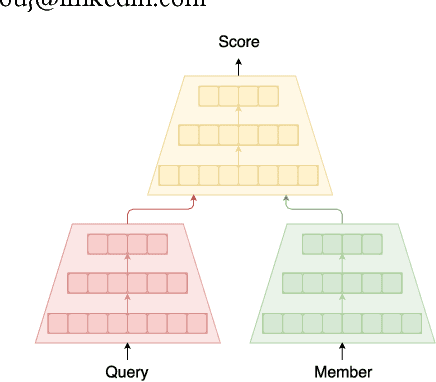
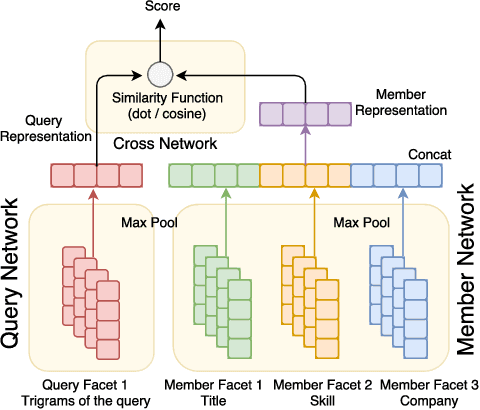
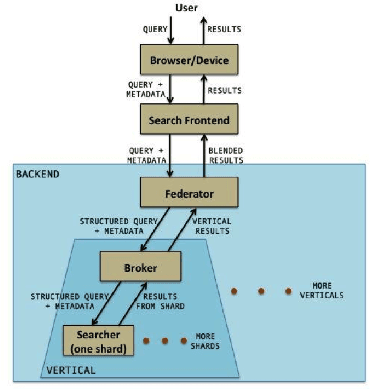
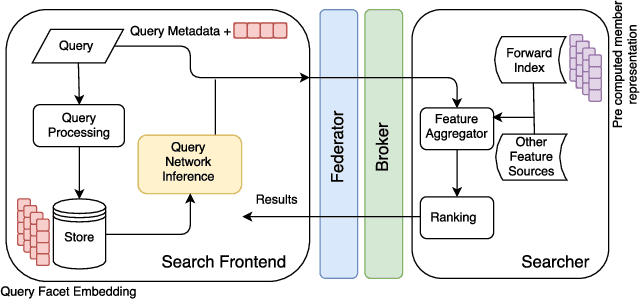
In this paper, we present an architecture executing a complex machine learning model such as a neural network capturing semantic similarity between a query and a document; and deploy to a real-world production system serving 500M+users. We present the challenges that arise in a real-world system and how we solve them. We demonstrate that our architecture provides competitive modeling capability without any significant performance impact to the system in terms of latency. Our modular solution and insights can be used by other real-world search systems to realize and productionize recent gains in neural networks.