 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation
Jan 27, 2025



Ranking and recommendation systems are the foundation for numerous online experiences, ranging from search results to personalized content delivery. These systems have evolved into complex, multilayered architectures that leverage vast datasets and often incorporate thousands of predictive models. The maintenance and enhancement of these models is a labor intensive process that requires extensive feature engineering. This approach not only exacerbates technical debt but also hampers innovation in extending these systems to emerging problem domains. In this report, we present our research to address these challenges by utilizing a large foundation model with a textual interface for ranking and recommendation tasks. We illustrate several key advantages of our approach: (1) a single model can manage multiple predictive tasks involved in ranking and recommendation, (2) decoder models with textual interface due to their comprehension of reasoning capabilities, can generalize to new recommendation surfaces and out-of-domain problems, and (3) by employing natural language interfaces for task definitions and verbalizing member behaviors and their social connections, we eliminate the need for feature engineering and the maintenance of complex directed acyclic graphs of model dependencies. We introduce our research pre-production model, 360Brew V1.0, a 150B parameter, decoder-only model that has been trained and fine-tuned on LinkedIn's data and tasks. This model is capable of solving over 30 predictive tasks across various segments of the LinkedIn platform, achieving performance levels comparable to or exceeding those of current production systems based on offline metrics, without task-specific fine-tuning. Notably, each of these tasks is conventionally addressed by dedicated models that have been developed and maintained over multiple years by teams of a similar or larger size than our own.
Lambda Learner: Fast Incremental Learning on Data Streams
Oct 11, 2020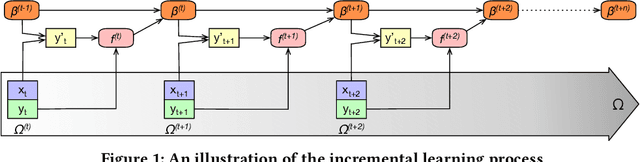
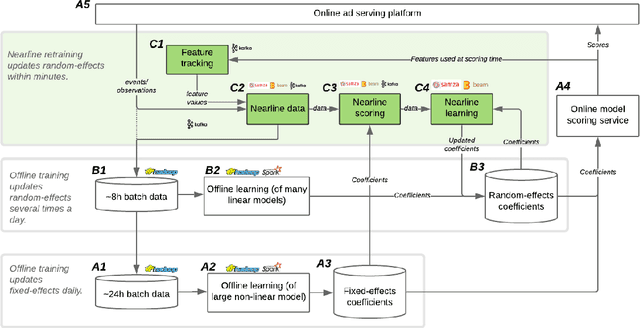
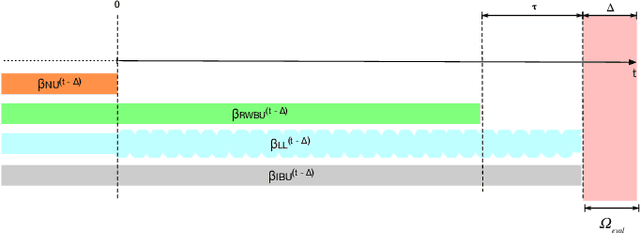
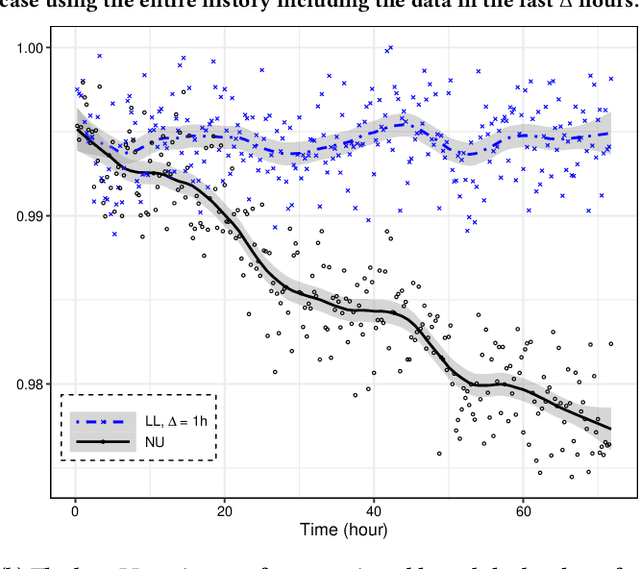
One of the most well-established applications of machine learning is in deciding what content to show website visitors. When observation data comes from high-velocity, user-generated data streams, machine learning methods perform a balancing act between model complexity, training time, and computational costs. Furthermore, when model freshness is critical, the training of models becomes time-constrained. Parallelized batch offline training, although horizontally scalable, is often not time-considerate or cost-effective. In this paper, we propose Lambda Learner, a new framework for training models by incremental updates in response to mini-batches from data streams. We show that the resulting model of our framework closely estimates a periodically updated model trained on offline data and outperforms it when model updates are time-sensitive. We provide theoretical proof that the incremental learning updates improve the loss-function over a stale batch model. We present a large-scale deployment on the sponsored content platform for a large social network, serving hundreds of millions of users across different channels (e.g., desktop, mobile). We address challenges and complexities from both algorithms and infrastructure perspectives, and illustrate the system details for computation, storage, and streaming production of training data.
An Attentive Survey of Attention Models
Apr 05, 2019
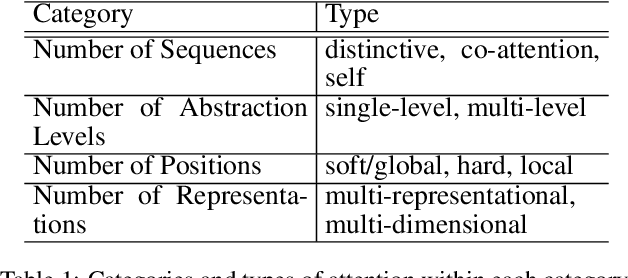
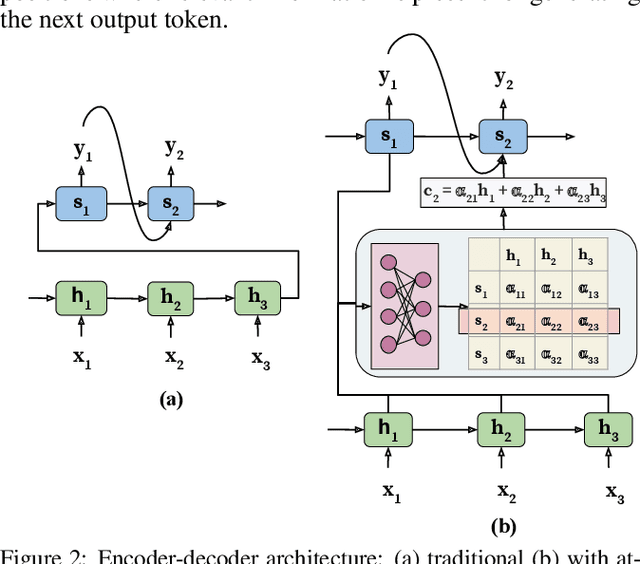
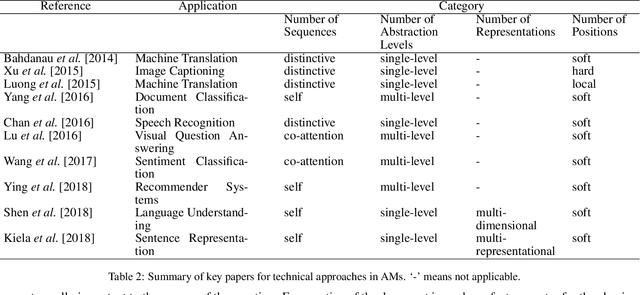
Attention Model has now become an important concept in neural networks that has been researched within diverse application domains. This survey provides a structured and comprehensive overview of the developments in modeling attention. In particular, we propose a taxonomy which groups existing techniques into coherent categories. We review the different neural architectures in which attention has been incorporated, and also show how attention improves interpretability of neural models. Finally, we discuss some applications in which modeling attention has a significant impact. We hope this survey will provide a succinct introduction to attention models and guide practitioners while developing approaches for their applications.
Towards Deep and Representation Learning for Talent Search at LinkedIn
Sep 17, 2018
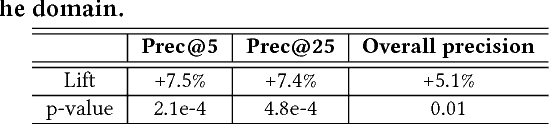
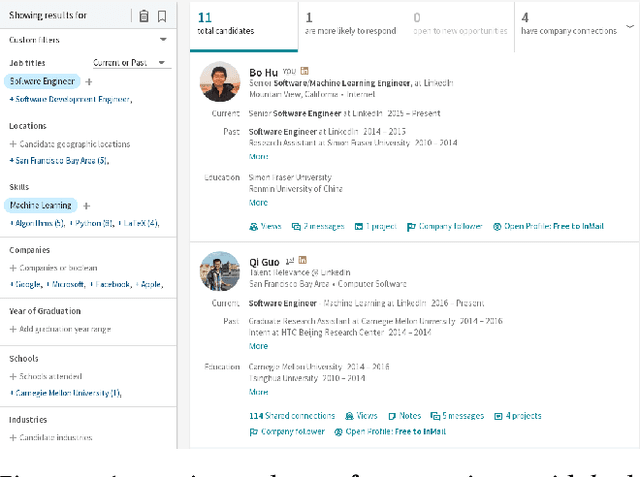
Talent search and recommendation systems at LinkedIn strive to match the potential candidates to the hiring needs of a recruiter or a hiring manager expressed in terms of a search query or a job posting. Recent work in this domain has mainly focused on linear models, which do not take complex relationships between features into account, as well as ensemble tree models, which introduce non-linearity but are still insufficient for exploring all the potential feature interactions, and strictly separate feature generation from modeling. In this paper, we present the results of our application of deep and representation learning models on LinkedIn Recruiter. Our key contributions include: (i) Learning semantic representations of sparse entities within the talent search domain, such as recruiter ids, candidate ids, and skill entity ids, for which we utilize neural network models that take advantage of LinkedIn Economic Graph, and (ii) Deep models for learning recruiter engagement and candidate response in talent search applications. We also explore learning to rank approaches applied to deep models, and show the benefits for the talent search use case. Finally, we present offline and online evaluation results for LinkedIn talent search and recommendation systems, and discuss potential challenges along the path to a fully deep model architecture. The challenges and approaches discussed generalize to any multi-faceted search engine.
Deploying Deep Ranking Models for Search Verticals
Jun 06, 2018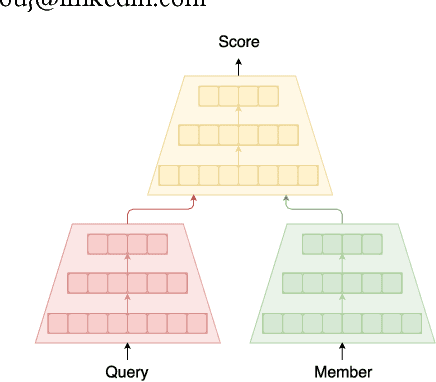
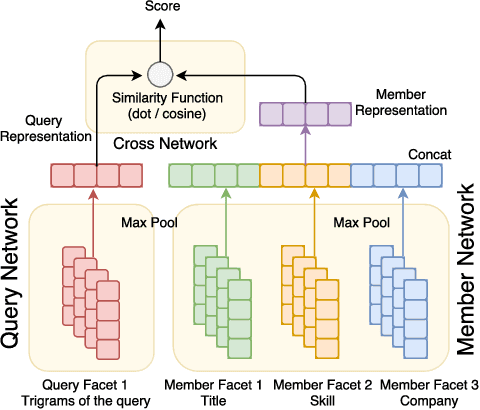
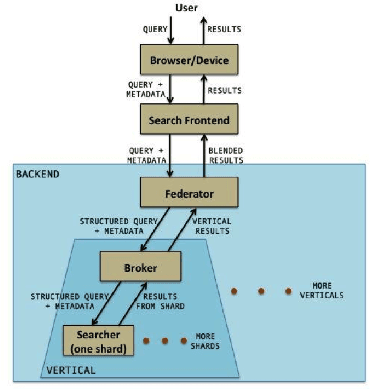
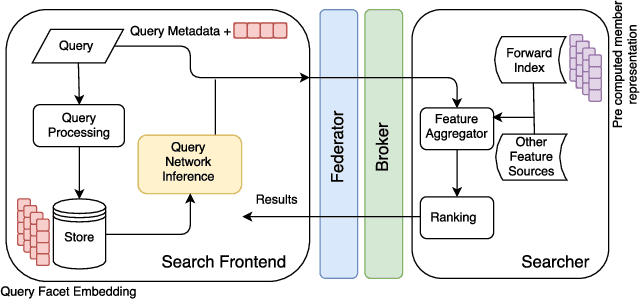
In this paper, we present an architecture executing a complex machine learning model such as a neural network capturing semantic similarity between a query and a document; and deploy to a real-world production system serving 500M+users. We present the challenges that arise in a real-world system and how we solve them. We demonstrate that our architecture provides competitive modeling capability without any significant performance impact to the system in terms of latency. Our modular solution and insights can be used by other real-world search systems to realize and productionize recent gains in neural networks.
Painting Analysis Using Wavelets and Probabilistic Topic Models
Jan 26, 2014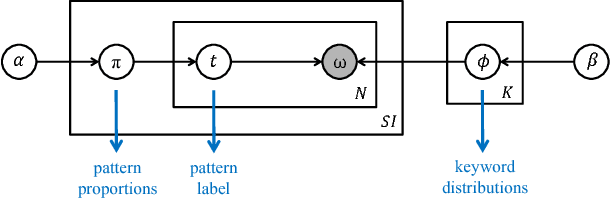
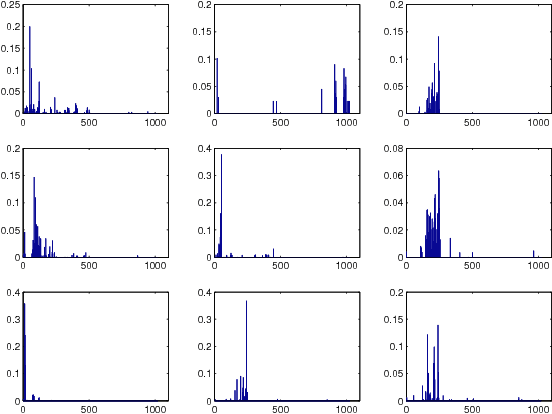
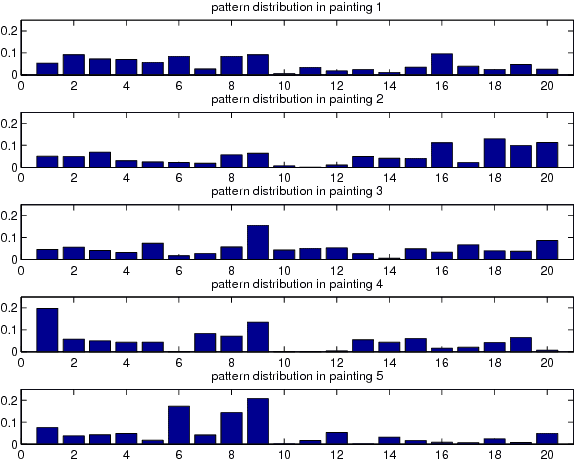

In this paper, computer-based techniques for stylistic analysis of paintings are applied to the five panels of the 14th century Peruzzi Altarpiece by Giotto di Bondone. Features are extracted by combining a dual-tree complex wavelet transform with a hidden Markov tree (HMT) model. Hierarchical clustering is used to identify stylistic keywords in image patches, and keyword frequencies are calculated for sub-images that each contains many patches. A generative hierarchical Bayesian model learns stylistic patterns of keywords; these patterns are then used to characterize the styles of the sub-images; this in turn, permits to discriminate between paintings. Results suggest that such unsupervised probabilistic topic models can be useful to distill characteristic elements of style.
A Bayesian Nonparametric Approach to Image Super-resolution
Sep 22, 2012


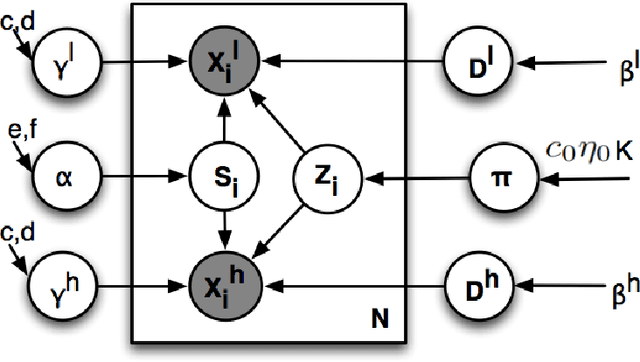
Super-resolution methods form high-resolution images from low-resolution images. In this paper, we develop a new Bayesian nonparametric model for super-resolution. Our method uses a beta-Bernoulli process to learn a set of recurring visual patterns, called dictionary elements, from the data. Because it is nonparametric, the number of elements found is also determined from the data. We test the results on both benchmark and natural images, comparing with several other models from the research literature. We perform large-scale human evaluation experiments to assess the visual quality of the results. In a first implementation, we use Gibbs sampling to approximate the posterior. However, this algorithm is not feasible for large-scale data. To circumvent this, we then develop an online variational Bayes (VB) algorithm. This algorithm finds high quality dictionaries in a fraction of the time needed by the Gibbs sampler.
Compressed Inference for Probabilistic Sequential Models
Feb 14, 2012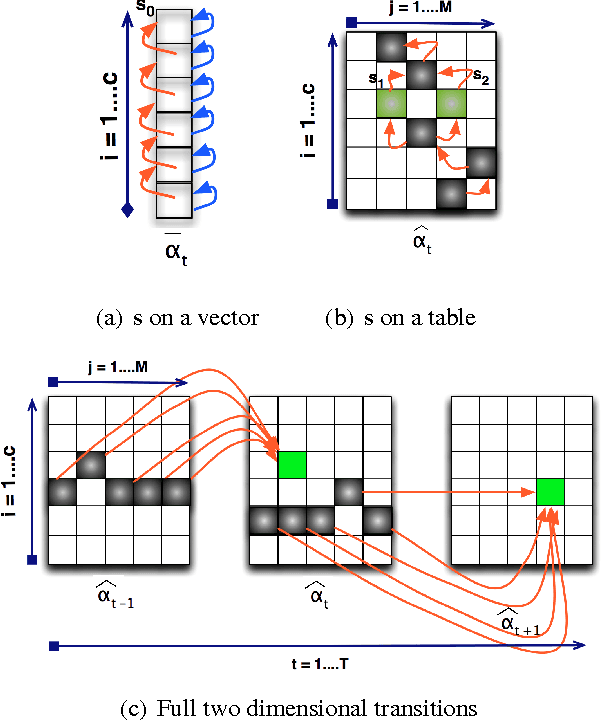
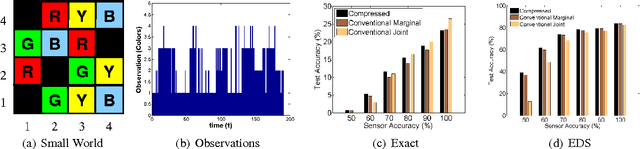

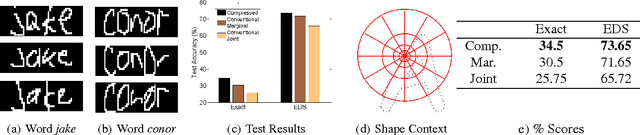
Hidden Markov models (HMMs) and conditional random fields (CRFs) are two popular techniques for modeling sequential data. Inference algorithms designed over CRFs and HMMs allow estimation of the state sequence given the observations. In several applications, estimation of the state sequence is not the end goal; instead the goal is to compute some function of it. In such scenarios, estimating the state sequence by conventional inference techniques, followed by computing the functional mapping from the estimate is not necessarily optimal. A more formal approach is to directly infer the final outcome from the observations. In particular, we consider the specific instantiation of the problem where the goal is to find the state trajectories without exact transition points and derive a novel polynomial time inference algorithm that outperforms vanilla inference techniques. We show that this particular problem arises commonly in many disparate applications and present experiments on three of them: (1) Toy robot tracking; (2) Single stroke character recognition; (3) Handwritten word recognition.