 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Customer Support AI Agents at 100M-User Scale: An Evaluation-Driven Framework
Jun 07, 2026The rapid rise in LLM capabilities has made AI agents increasingly viable across a broad range of tasks. Among the most promising applications is building production-ready customer-facing agents, a challenge that demands coordinated excellence in evaluation methodology, context engineering, training, and online measurement. Yet these critical pillars are typically developed in isolation, creating blind spots that only surface after deployment. In this paper, we present a unified framework that bridges offline development with online impact for customer support AI agents at Nubank, a company with 100M+ users. Our approach integrates several key components: (1) structured context engineering tailored to customer support agents, (2) systematic human-in-the-loop prompt iteration, (3) rigorous LLM judge evaluation with measured inter-rater agreement and GEPA optimization for consistency, and (4) ideation-to-production validation. A central insight is that evaluation-pipeline quality directly determines iteration velocity. We present results from five production deployments spanning distinct domains: card delivery, debt management, credit-limit support, card management, and product explanation. These deployments deliver consistent customer-satisfaction gains while substantially accelerating iteration. In our card-delivery deployment, large-scale A/B testing yields a 37 percentage-point improvement in AI transactional Net Promoter Score and a 29 percentage-point gain in self-service rate over prior agent variants, alongside a strong correlation between offline simulation metrics and online outcomes, demonstrating that eval-driven development reliably predicts production impact. On most use cases, AI satisfaction reaches within a few percentage points of expert human agents.
Logit Attenuating Weight Normalization
Aug 12, 2021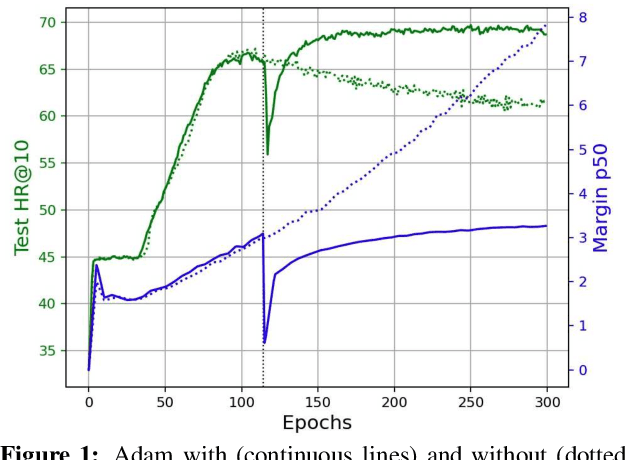
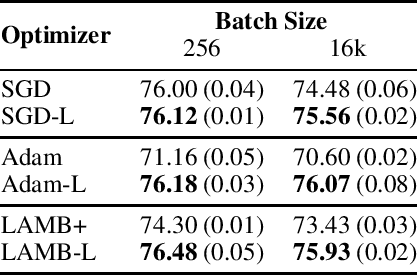

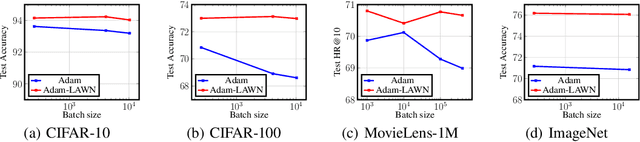
Over-parameterized deep networks trained using gradient-based optimizers are a popular choice for solving classification and ranking problems. Without appropriately tuned $\ell_2$ regularization or weight decay, such networks have the tendency to make output scores (logits) and network weights large, causing training loss to become too small and the network to lose its adaptivity (ability to move around) in the parameter space. Although regularization is typically understood from an overfitting perspective, we highlight its role in making the network more adaptive and enabling it to escape more easily from weights that generalize poorly. To provide such a capability, we propose a method called Logit Attenuating Weight Normalization (LAWN), that can be stacked onto any gradient-based optimizer. LAWN controls the logits by constraining the weight norms of layers in the final homogeneous sub-network. Empirically, we show that the resulting LAWN variant of the optimizer makes a deep network more adaptive to finding minimas with superior generalization performance on large-scale image classification and recommender systems. While LAWN is particularly impressive in improving Adam, it greatly improves all optimizers when used with large batch sizes
Efficient Algorithms for Global Inference in Internet Marketplaces
Mar 10, 2021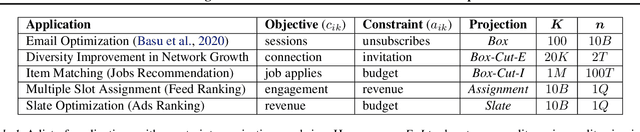
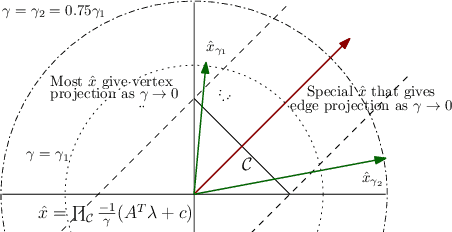

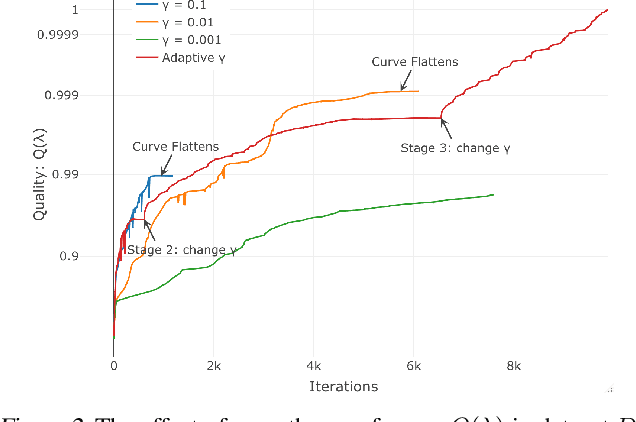
Matching demand to supply in internet marketplaces (e-commerce, ride-sharing, food delivery, professional services, advertising) is a global inference problem that can be formulated as a Linear Program (LP) with (millions of) coupling constraints and (up to a billion) non-coupling polytope constraints. Until recently, solving such problems on web-scale data with an LP formulation was intractable. Recent work (Basu et al., 2020) developed a dual decomposition-based approach to solve such problems when the polytope constraints are simple. In this work, we motivate the need to go beyond these simple polytopes and show real-world internet marketplaces that require more complex structured polytope constraints. We expand on the recent literature with novel algorithms that are more broadly applicable to global inference problems. We derive an efficient incremental algorithm using a theoretical insight on the nature of solutions on the polytopes to project onto any arbitrary polytope, that shows massive improvements in performance. Using better optimization routines along with an adaptive algorithm to control the smoothness of the objective, improves the speed of the solution even further. We showcase the efficacy of our approach via experimental results on web-scale marketplace data.
Lambda Learner: Fast Incremental Learning on Data Streams
Oct 11, 2020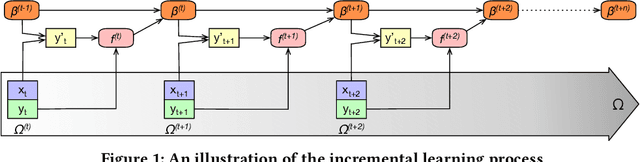
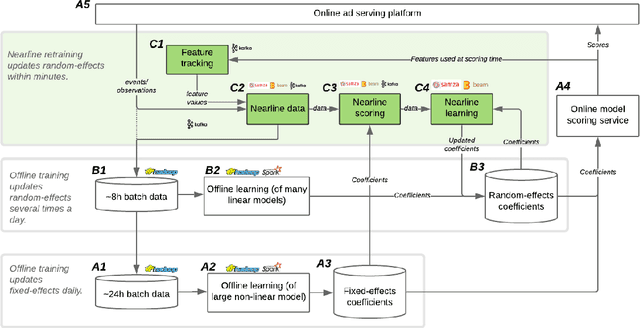
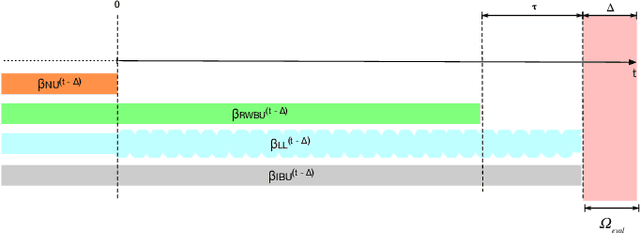
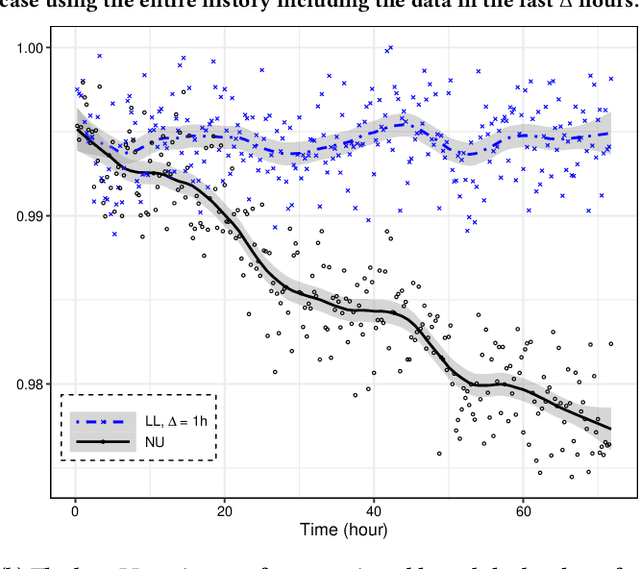
One of the most well-established applications of machine learning is in deciding what content to show website visitors. When observation data comes from high-velocity, user-generated data streams, machine learning methods perform a balancing act between model complexity, training time, and computational costs. Furthermore, when model freshness is critical, the training of models becomes time-constrained. Parallelized batch offline training, although horizontally scalable, is often not time-considerate or cost-effective. In this paper, we propose Lambda Learner, a new framework for training models by incremental updates in response to mini-batches from data streams. We show that the resulting model of our framework closely estimates a periodically updated model trained on offline data and outperforms it when model updates are time-sensitive. We provide theoretical proof that the incremental learning updates improve the loss-function over a stale batch model. We present a large-scale deployment on the sponsored content platform for a large social network, serving hundreds of millions of users across different channels (e.g., desktop, mobile). We address challenges and complexities from both algorithms and infrastructure perspectives, and illustrate the system details for computation, storage, and streaming production of training data.
An Attentive Survey of Attention Models
Apr 05, 2019
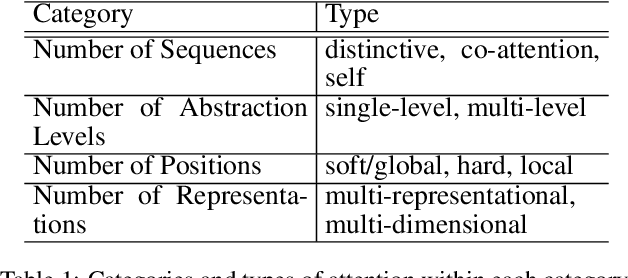
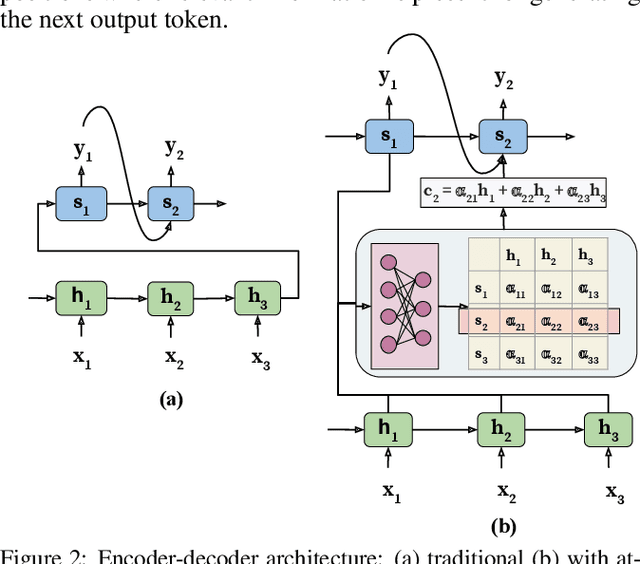
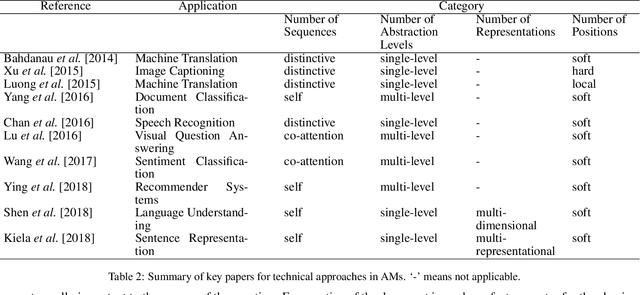
Attention Model has now become an important concept in neural networks that has been researched within diverse application domains. This survey provides a structured and comprehensive overview of the developments in modeling attention. In particular, we propose a taxonomy which groups existing techniques into coherent categories. We review the different neural architectures in which attention has been incorporated, and also show how attention improves interpretability of neural models. Finally, we discuss some applications in which modeling attention has a significant impact. We hope this survey will provide a succinct introduction to attention models and guide practitioners while developing approaches for their applications.
Towards Deep and Representation Learning for Talent Search at LinkedIn
Sep 17, 2018
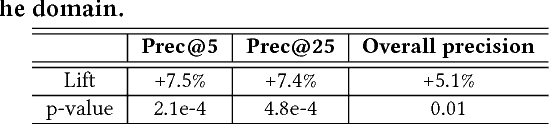
Talent search and recommendation systems at LinkedIn strive to match the potential candidates to the hiring needs of a recruiter or a hiring manager expressed in terms of a search query or a job posting. Recent work in this domain has mainly focused on linear models, which do not take complex relationships between features into account, as well as ensemble tree models, which introduce non-linearity but are still insufficient for exploring all the potential feature interactions, and strictly separate feature generation from modeling. In this paper, we present the results of our application of deep and representation learning models on LinkedIn Recruiter. Our key contributions include: (i) Learning semantic representations of sparse entities within the talent search domain, such as recruiter ids, candidate ids, and skill entity ids, for which we utilize neural network models that take advantage of LinkedIn Economic Graph, and (ii) Deep models for learning recruiter engagement and candidate response in talent search applications. We also explore learning to rank approaches applied to deep models, and show the benefits for the talent search use case. Finally, we present offline and online evaluation results for LinkedIn talent search and recommendation systems, and discuss potential challenges along the path to a fully deep model architecture. The challenges and approaches discussed generalize to any multi-faceted search engine.
Deploying Deep Ranking Models for Search Verticals
Jun 06, 2018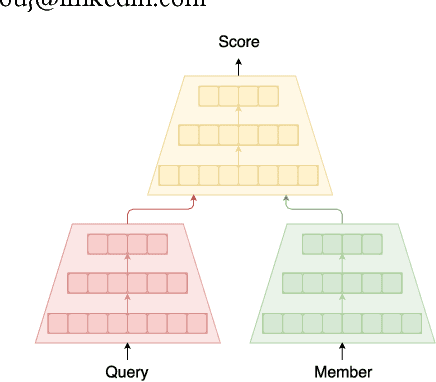
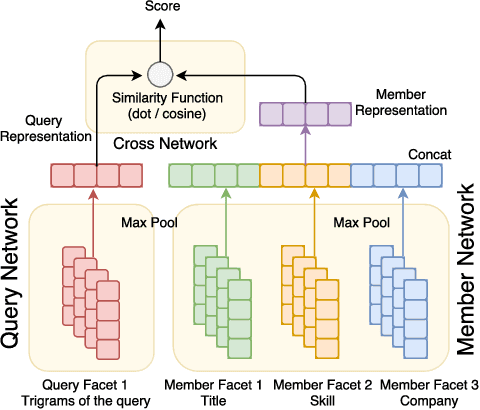
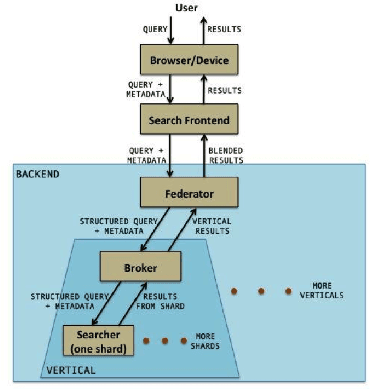
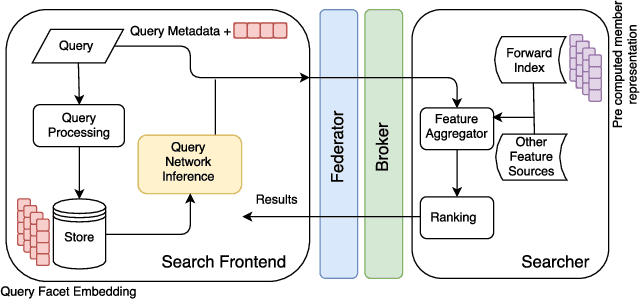
In this paper, we present an architecture executing a complex machine learning model such as a neural network capturing semantic similarity between a query and a document; and deploy to a real-world production system serving 500M+users. We present the challenges that arise in a real-world system and how we solve them. We demonstrate that our architecture provides competitive modeling capability without any significant performance impact to the system in terms of latency. Our modular solution and insights can be used by other real-world search systems to realize and productionize recent gains in neural networks.