 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Algorithms for Global Inference in Internet Marketplaces
Mar 10, 2021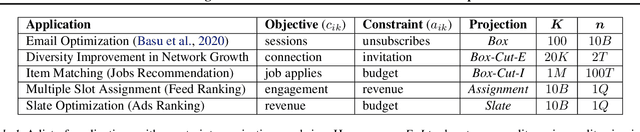
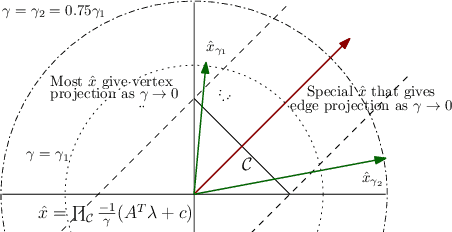

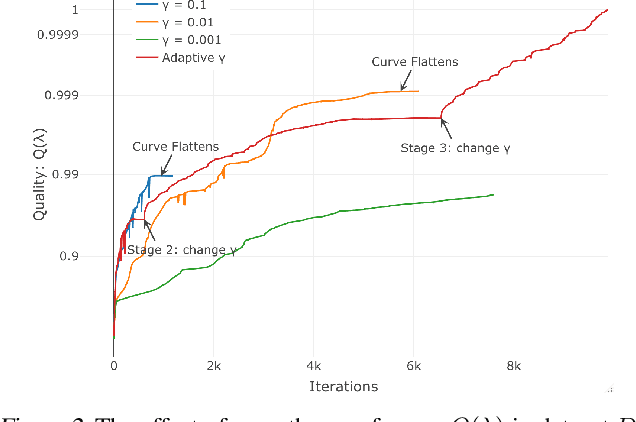
Matching demand to supply in internet marketplaces (e-commerce, ride-sharing, food delivery, professional services, advertising) is a global inference problem that can be formulated as a Linear Program (LP) with (millions of) coupling constraints and (up to a billion) non-coupling polytope constraints. Until recently, solving such problems on web-scale data with an LP formulation was intractable. Recent work (Basu et al., 2020) developed a dual decomposition-based approach to solve such problems when the polytope constraints are simple. In this work, we motivate the need to go beyond these simple polytopes and show real-world internet marketplaces that require more complex structured polytope constraints. We expand on the recent literature with novel algorithms that are more broadly applicable to global inference problems. We derive an efficient incremental algorithm using a theoretical insight on the nature of solutions on the polytopes to project onto any arbitrary polytope, that shows massive improvements in performance. Using better optimization routines along with an adaptive algorithm to control the smoothness of the objective, improves the speed of the solution even further. We showcase the efficacy of our approach via experimental results on web-scale marketplace data.
Lambda Learner: Fast Incremental Learning on Data Streams
Oct 11, 2020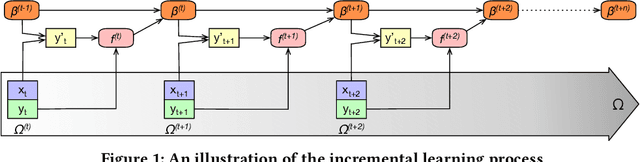
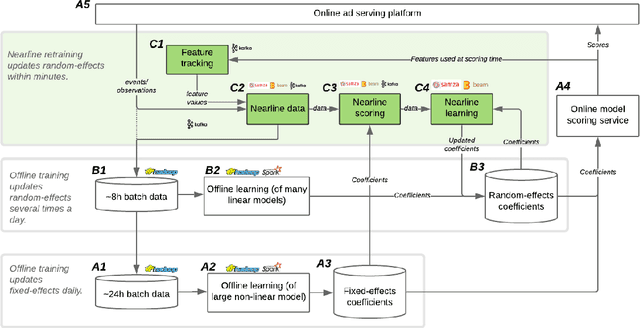
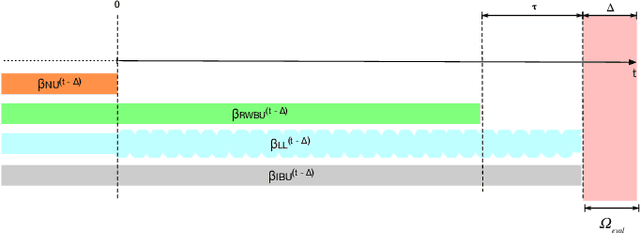
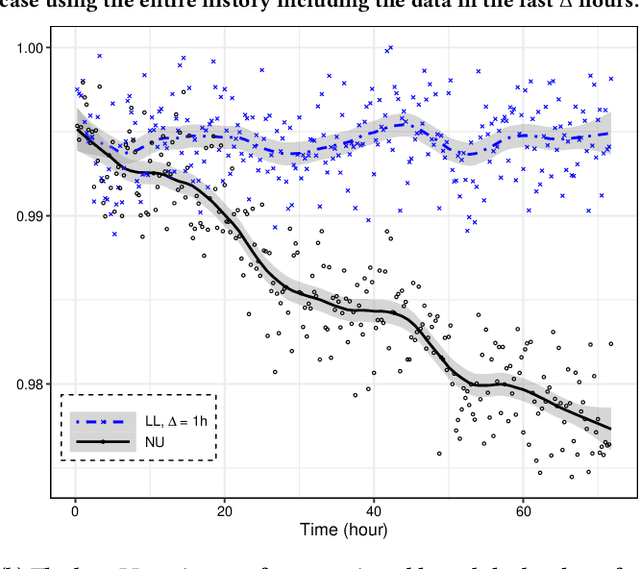
One of the most well-established applications of machine learning is in deciding what content to show website visitors. When observation data comes from high-velocity, user-generated data streams, machine learning methods perform a balancing act between model complexity, training time, and computational costs. Furthermore, when model freshness is critical, the training of models becomes time-constrained. Parallelized batch offline training, although horizontally scalable, is often not time-considerate or cost-effective. In this paper, we propose Lambda Learner, a new framework for training models by incremental updates in response to mini-batches from data streams. We show that the resulting model of our framework closely estimates a periodically updated model trained on offline data and outperforms it when model updates are time-sensitive. We provide theoretical proof that the incremental learning updates improve the loss-function over a stale batch model. We present a large-scale deployment on the sponsored content platform for a large social network, serving hundreds of millions of users across different channels (e.g., desktop, mobile). We address challenges and complexities from both algorithms and infrastructure perspectives, and illustrate the system details for computation, storage, and streaming production of training data.