 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
A Better Match for Drivers and Riders: Reinforcement Learning at Lyft
Oct 20, 2023To better match drivers to riders in our ridesharing application, we revised Lyft's core matching algorithm. We use a novel online reinforcement learning approach that estimates the future earnings of drivers in real time and use this information to find more efficient matches. This change was the first documented implementation of a ridesharing matching algorithm that can learn and improve in real time. We evaluated the new approach during weeks of switchback experimentation in most Lyft markets, and estimated how it benefited drivers, riders, and the platform. In particular, it enabled our drivers to serve millions of additional riders each year, leading to more than $30 million per year in incremental revenue. Lyft rolled out the algorithm globally in 2021.
Lambda Learner: Fast Incremental Learning on Data Streams
Oct 11, 2020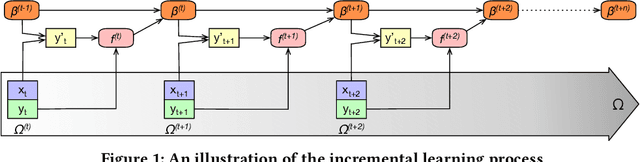
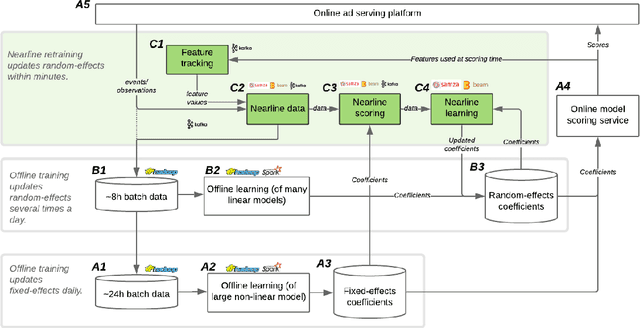
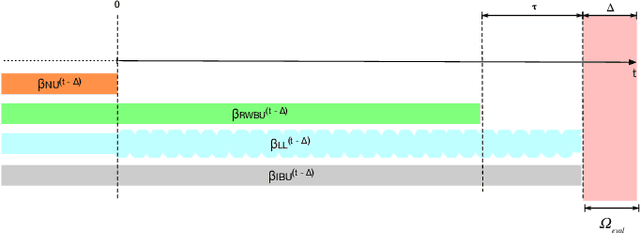
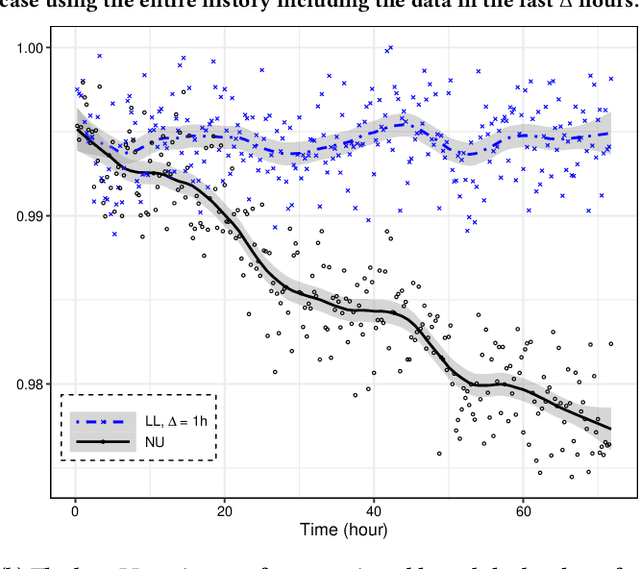
One of the most well-established applications of machine learning is in deciding what content to show website visitors. When observation data comes from high-velocity, user-generated data streams, machine learning methods perform a balancing act between model complexity, training time, and computational costs. Furthermore, when model freshness is critical, the training of models becomes time-constrained. Parallelized batch offline training, although horizontally scalable, is often not time-considerate or cost-effective. In this paper, we propose Lambda Learner, a new framework for training models by incremental updates in response to mini-batches from data streams. We show that the resulting model of our framework closely estimates a periodically updated model trained on offline data and outperforms it when model updates are time-sensitive. We provide theoretical proof that the incremental learning updates improve the loss-function over a stale batch model. We present a large-scale deployment on the sponsored content platform for a large social network, serving hundreds of millions of users across different channels (e.g., desktop, mobile). We address challenges and complexities from both algorithms and infrastructure perspectives, and illustrate the system details for computation, storage, and streaming production of training data.