 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-Aware Graph Representation Learning with Limited Demographic Information
Nov 18, 2025Ensuring fairness in Graph Neural Networks is fundamental to promoting trustworthy and socially responsible machine learning systems. In response, numerous fair graph learning methods have been proposed in recent years. However, most of them assume full access to demographic information, a requirement rarely met in practice due to privacy, legal, or regulatory restrictions. To this end, this paper introduces a novel fair graph learning framework that mitigates bias in graph learning under limited demographic information. Specifically, we propose a mechanism guided by partial demographic data to generate proxies for demographic information and design a strategy that enforces consistent node embeddings across demographic groups. In addition, we develop an adaptive confidence strategy that dynamically adjusts each node's contribution to fairness and utility based on prediction confidence. We further provide theoretical analysis demonstrating that our framework, FairGLite, achieves provable upper bounds on group fairness metrics, offering formal guarantees for bias mitigation. Through extensive experiments on multiple datasets and fair graph learning frameworks, we demonstrate the framework's effectiveness in both mitigating bias and maintaining model utility.
AI Fairness Beyond Complete Demographics: Current Achievements and Future Directions
Nov 17, 2025Fairness in artificial intelligence (AI) has become a growing concern due to discriminatory outcomes in AI-based decision-making systems. While various methods have been proposed to mitigate bias, most rely on complete demographic information, an assumption often impractical due to legal constraints and the risk of reinforcing discrimination. This survey examines fairness in AI when demographics are incomplete, addressing the gap between traditional approaches and real-world challenges. We introduce a novel taxonomy of fairness notions in this setting, clarifying their relationships and distinctions. Additionally, we summarize existing techniques that promote fairness beyond complete demographics and highlight open research questions to encourage further progress in the field.
ReQFlow: Rectified Quaternion Flow for Efficient and High-Quality Protein Backbone Generation
Feb 20, 2025Protein backbone generation plays a central role in de novo protein design and is significant for many biological and medical applications. Although diffusion and flow-based generative models provide potential solutions to this challenging task, they often generate proteins with undesired designability and suffer computational inefficiency. In this study, we propose a novel rectified quaternion flow (ReQFlow) matching method for fast and high-quality protein backbone generation. In particular, our method generates a local translation and a 3D rotation from random noise for each residue in a protein chain, which represents each 3D rotation as a unit quaternion and constructs its flow by spherical linear interpolation (SLERP) in an exponential format. We train the model by quaternion flow (QFlow) matching with guaranteed numerical stability and rectify the QFlow model to accelerate its inference and improve the designability of generated protein backbones, leading to the proposed ReQFlow model. Experiments show that ReQFlow achieves state-of-the-art performance in protein backbone generation while requiring much fewer sampling steps and significantly less inference time (e.g., being 37x faster than RFDiffusion and 62x faster than Genie2 when generating a backbone of length 300), demonstrating its effectiveness and efficiency. The code is available at https://github.com/AngxiaoYue/ReQFlow.
Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL
Nov 20, 2024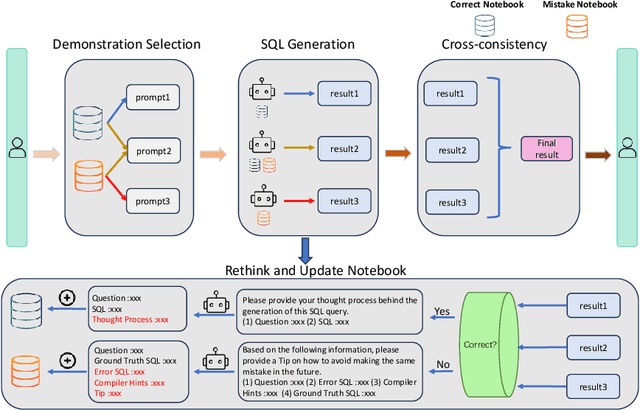

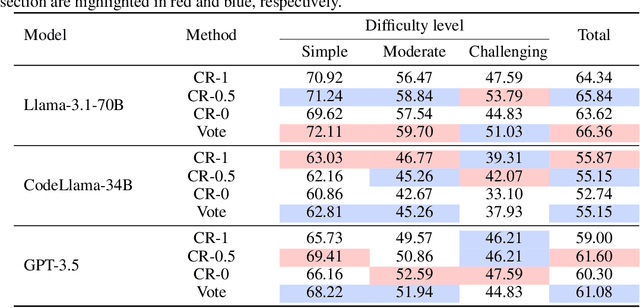

Large Language Models (LLMs) exhibit impressive problem-solving skills across many tasks, but they still underperform compared to humans in various downstream applications, such as text-to-SQL. On the BIRD benchmark leaderboard, human performance achieves an accuracy of 92.96\%, whereas the top-performing method reaches only 72.39\%. Notably, these state-of-the-art (SoTA) methods predominantly rely on in-context learning to simulate human-like reasoning. However, they overlook a critical human skill: continual learning. Inspired by the educational practice of maintaining mistake notebooks during our formative years, we propose LPE-SQL (Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL), a novel framework designed to augment LLMs by enabling continual learning without requiring parameter fine-tuning. LPE-SQL consists of four modules that \textbf{i)} retrieve relevant entries, \textbf{ii)} efficient sql generation, \textbf{iii)} generate the final result through a cross-consistency mechanism and \textbf{iv)} log successful and failed tasks along with their reasoning processes or reflection-generated tips. Importantly, the core module of LPE-SQL is the fourth one, while the other modules employ foundational methods, allowing LPE-SQL to be easily integrated with SoTA technologies to further enhance performance. Our experimental results demonstrate that this continual learning approach yields substantial performance gains, with the smaller Llama-3.1-70B model with surpassing the performance of the larger Llama-3.1-405B model using SoTA methods.
Fairness in Large Language Models in Three Hour
Aug 05, 2024Large Language Models (LLMs) have demonstrated remarkable success across various domains but often lack fairness considerations, potentially leading to discriminatory outcomes against marginalized populations. Unlike fairness in traditional machine learning, fairness in LLMs involves unique backgrounds, taxonomies, and fulfillment techniques. This tutorial provides a systematic overview of recent advances in the literature concerning fair LLMs, beginning with real-world case studies to introduce LLMs, followed by an analysis of bias causes therein. The concept of fairness in LLMs is then explored, summarizing the strategies for evaluating bias and the algorithms designed to promote fairness. Additionally, resources for assessing bias in LLMs, including toolkits and datasets, are compiled, and current research challenges and open questions in the field are discussed. The repository is available at \url{https://github.com/LavinWong/Fairness-in-Large-Language-Models}.
AI-Driven Healthcare: A Survey on Ensuring Fairness and Mitigating Bias
Jul 29, 2024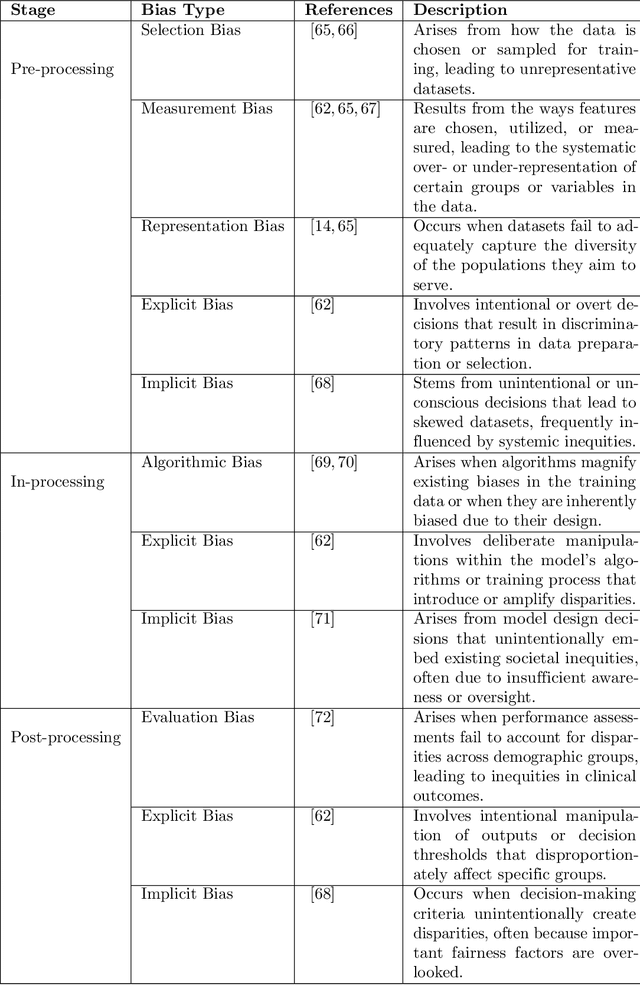
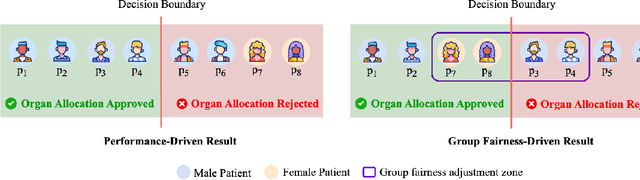
Artificial intelligence (AI) is rapidly advancing in healthcare, enhancing the efficiency and effectiveness of services across various specialties, including cardiology, ophthalmology, dermatology, emergency medicine, etc. AI applications have significantly improved diagnostic accuracy, treatment personalization, and patient outcome predictions by leveraging technologies such as machine learning, neural networks, and natural language processing. However, these advancements also introduce substantial ethical and fairness challenges, particularly related to biases in data and algorithms. These biases can lead to disparities in healthcare delivery, affecting diagnostic accuracy and treatment outcomes across different demographic groups. This survey paper examines the integration of AI in healthcare, highlighting critical challenges related to bias and exploring strategies for mitigation. We emphasize the necessity of diverse datasets, fairness-aware algorithms, and regulatory frameworks to ensure equitable healthcare delivery. The paper concludes with recommendations for future research, advocating for interdisciplinary approaches, transparency in AI decision-making, and the development of innovative and inclusive AI applications.
Fairness Definitions in Language Models Explained
Jul 26, 2024



Language Models (LMs) have demonstrated exceptional performance across various Natural Language Processing (NLP) tasks. Despite these advancements, LMs can inherit and amplify societal biases related to sensitive attributes such as gender and race, limiting their adoption in real-world applications. Therefore, fairness has been extensively explored in LMs, leading to the proposal of various fairness notions. However, the lack of clear agreement on which fairness definition to apply in specific contexts (\textit{e.g.,} medium-sized LMs versus large-sized LMs) and the complexity of understanding the distinctions between these definitions can create confusion and impede further progress. To this end, this paper proposes a systematic survey that clarifies the definitions of fairness as they apply to LMs. Specifically, we begin with a brief introduction to LMs and fairness in LMs, followed by a comprehensive, up-to-date overview of existing fairness notions in LMs and the introduction of a novel taxonomy that categorizes these concepts based on their foundational principles and operational distinctions. We further illustrate each definition through experiments, showcasing their practical implications and outcomes. Finally, we discuss current research challenges and open questions, aiming to foster innovative ideas and advance the field. The implementation and additional resources are publicly available at https://github.com/LavinWong/Fairness-in-Large-Language-Models/tree/main/definitions.
FairAIED: Navigating Fairness, Bias, and Ethics in Educational AI Applications
Jul 26, 2024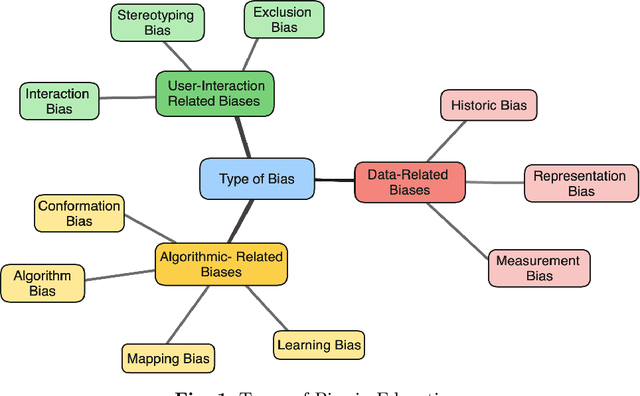
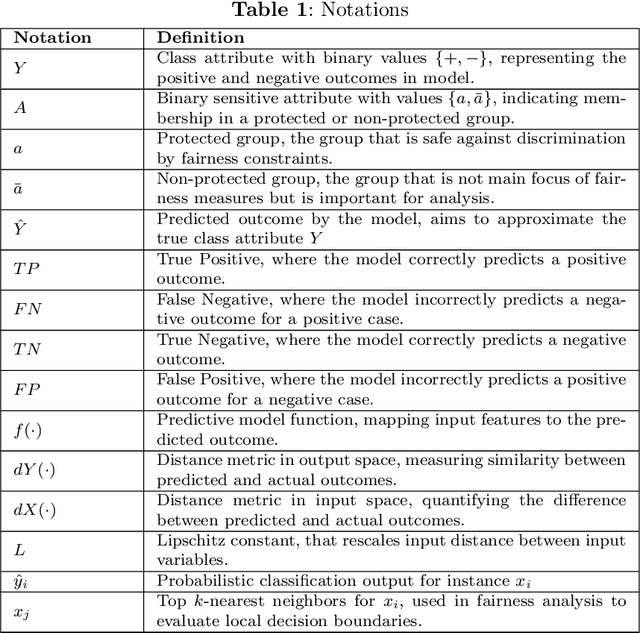
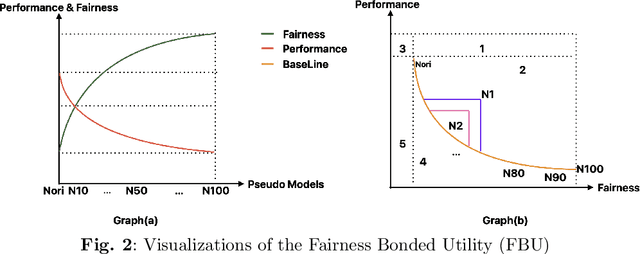
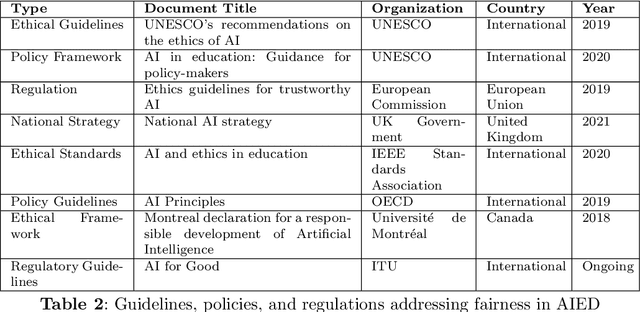
The integration of Artificial Intelligence (AI) into education has transformative potential, providing tailored learning experiences and creative instructional approaches. However, the inherent biases in AI algorithms hinder this improvement by unintentionally perpetuating prejudice against specific demographics, especially in human-centered applications like education. This survey delves deeply into the developing topic of algorithmic fairness in educational contexts, providing a comprehensive evaluation of the diverse literature on fairness, bias, and ethics in AI-driven educational applications. It identifies the common forms of biases, such as data-related, algorithmic, and user-interaction, that fundamentally undermine the accomplishment of fairness in AI teaching aids. By outlining existing techniques for mitigating these biases, ranging from varied data gathering to algorithmic fairness interventions, the survey emphasizes the critical role of ethical considerations and legal frameworks in shaping a more equitable educational environment. Furthermore, it guides readers through the complexities of fairness measurements, methods, and datasets, shedding light on the way to bias reduction. Despite these gains, this survey highlights long-standing issues, such as achieving a balance between fairness and accuracy, as well as the need for diverse datasets. Overcoming these challenges and ensuring the ethical and fair use of AI's promise in education call for a collaborative, interdisciplinary approach.
Uncertain Boundaries: Multidisciplinary Approaches to Copyright Issues in Generative AI
Mar 31, 2024In the rapidly evolving landscape of generative artificial intelligence (AI), the increasingly pertinent issue of copyright infringement arises as AI advances to generate content from scraped copyrighted data, prompting questions about ownership and protection that impact professionals across various careers. With this in mind, this survey provides an extensive examination of copyright infringement as it pertains to generative AI, aiming to stay abreast of the latest developments and open problems. Specifically, it will first outline methods of detecting copyright infringement in mediums such as text, image, and video. Next, it will delve an exploration of existing techniques aimed at safeguarding copyrighted works from generative models. Furthermore, this survey will discuss resources and tools for users to evaluate copyright violations. Finally, insights into ongoing regulations and proposals for AI will be explored and compared. Through combining these disciplines, the implications of AI-driven content and copyright are thoroughly illustrated and brought into question.
Fairness in Large Language Models: A Taxonomic Survey
Mar 31, 2024Large Language Models (LLMs) have demonstrated remarkable success across various domains. However, despite their promising performance in numerous real-world applications, most of these algorithms lack fairness considerations. Consequently, they may lead to discriminatory outcomes against certain communities, particularly marginalized populations, prompting extensive study in fair LLMs. On the other hand, fairness in LLMs, in contrast to fairness in traditional machine learning, entails exclusive backgrounds, taxonomies, and fulfillment techniques. To this end, this survey presents a comprehensive overview of recent advances in the existing literature concerning fair LLMs. Specifically, a brief introduction to LLMs is provided, followed by an analysis of factors contributing to bias in LLMs. Additionally, the concept of fairness in LLMs is discussed categorically, summarizing metrics for evaluating bias in LLMs and existing algorithms for promoting fairness. Furthermore, resources for evaluating bias in LLMs, including toolkits and datasets, are summarized. Finally, existing research challenges and open questions are discussed.