 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn experimental study on fairness-aware machine learning for credit scoring problem
Dec 28, 2024



Digitalization of credit scoring is an essential requirement for financial organizations and commercial banks, especially in the context of digital transformation. Machine learning techniques are commonly used to evaluate customers' creditworthiness. However, the predicted outcomes of machine learning models can be biased toward protected attributes, such as race or gender. Numerous fairness-aware machine learning models and fairness measures have been proposed. Nevertheless, their performance in the context of credit scoring has not been thoroughly investigated. In this paper, we present a comprehensive experimental study of fairness-aware machine learning in credit scoring. The study explores key aspects of credit scoring, including financial datasets, predictive models, and fairness measures. We also provide a detailed evaluation of fairness-aware predictive models and fairness measures on widely used financial datasets.
FairAIED: Navigating Fairness, Bias, and Ethics in Educational AI Applications
Jul 26, 2024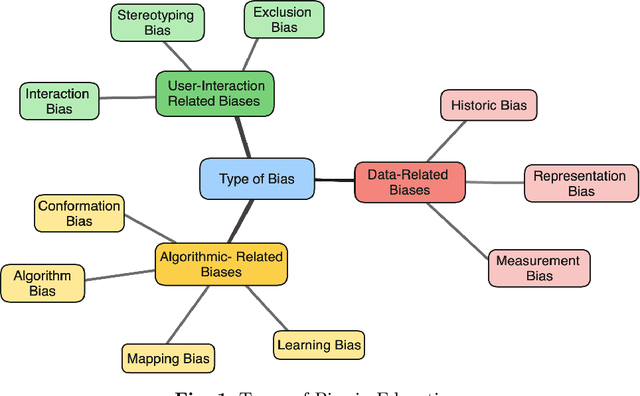
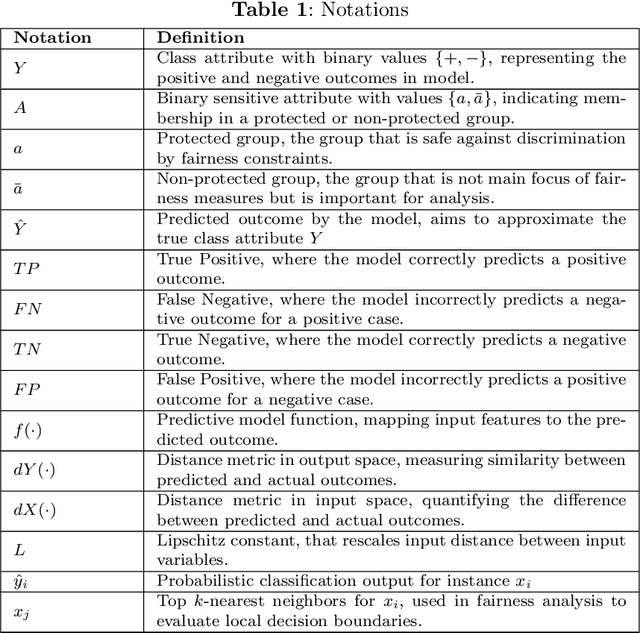
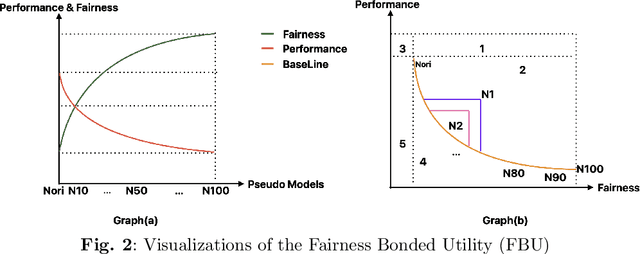
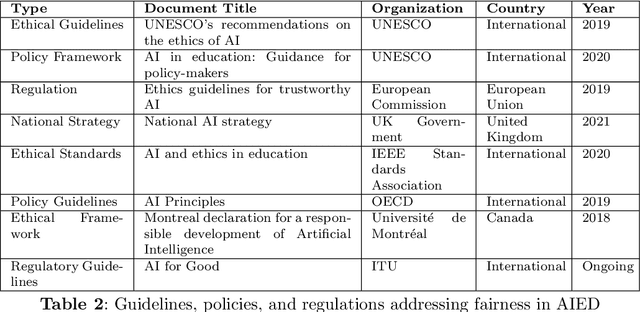
The integration of Artificial Intelligence (AI) into education has transformative potential, providing tailored learning experiences and creative instructional approaches. However, the inherent biases in AI algorithms hinder this improvement by unintentionally perpetuating prejudice against specific demographics, especially in human-centered applications like education. This survey delves deeply into the developing topic of algorithmic fairness in educational contexts, providing a comprehensive evaluation of the diverse literature on fairness, bias, and ethics in AI-driven educational applications. It identifies the common forms of biases, such as data-related, algorithmic, and user-interaction, that fundamentally undermine the accomplishment of fairness in AI teaching aids. By outlining existing techniques for mitigating these biases, ranging from varied data gathering to algorithmic fairness interventions, the survey emphasizes the critical role of ethical considerations and legal frameworks in shaping a more equitable educational environment. Furthermore, it guides readers through the complexities of fairness measurements, methods, and datasets, shedding light on the way to bias reduction. Despite these gains, this survey highlights long-standing issues, such as achieving a balance between fairness and accuracy, as well as the need for diverse datasets. Overcoming these challenges and ensuring the ethical and fair use of AI's promise in education call for a collaborative, interdisciplinary approach.
A review of clustering models in educational data science towards fairness-aware learning
Jan 09, 2023Ensuring fairness is essential for every education system. Machine learning is increasingly supporting the education system and educational data science (EDS) domain, from decision support to educational activities and learning analytics. However, the machine learning-based decisions can be biased because the algorithms may generate the results based on students' protected attributes such as race or gender. Clustering is an important machine learning technique to explore student data in order to support the decision-maker, as well as support educational activities, such as group assignments. Therefore, ensuring high-quality clustering models along with satisfying fairness constraints are important requirements. This chapter comprehensively surveys clustering models and their fairness in EDS. We especially focus on investigating the fair clustering models applied in educational activities. These models are believed to be practical tools for analyzing students' data and ensuring fairness in EDS.
Evaluation of group fairness measures in student performance prediction problems
Aug 22, 2022

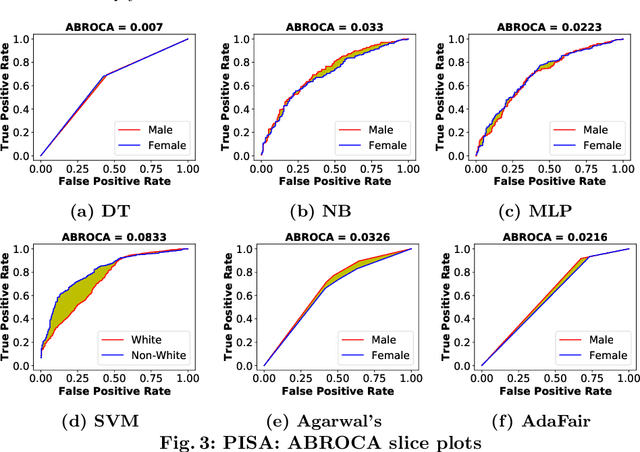
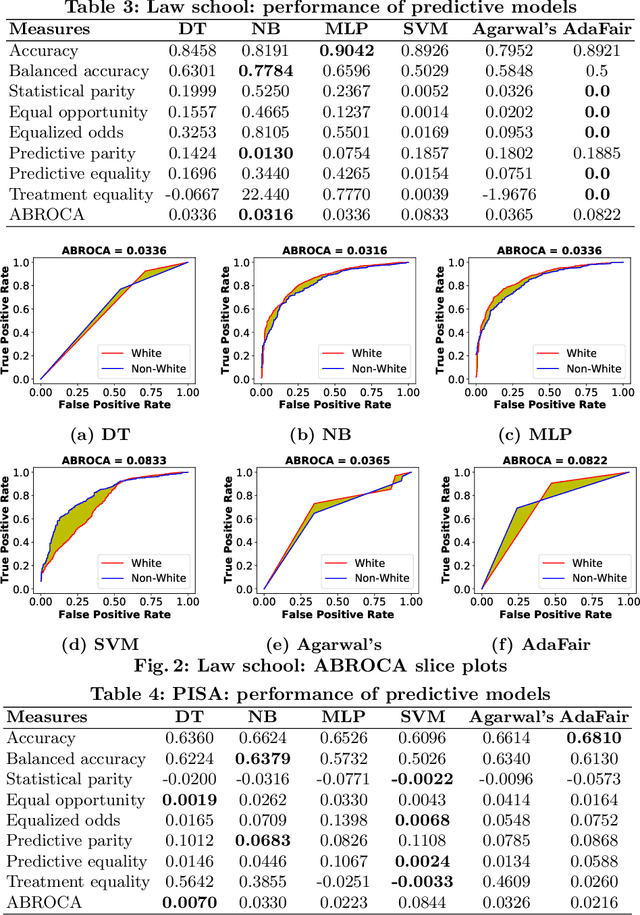
Predicting students' academic performance is one of the key tasks of educational data mining (EDM). Traditionally, the high forecasting quality of such models was deemed critical. More recently, the issues of fairness and discrimination w.r.t. protected attributes, such as gender or race, have gained attention. Although there are several fairness-aware learning approaches in EDM, a comparative evaluation of these measures is still missing. In this paper, we evaluate different group fairness measures for student performance prediction problems on various educational datasets and fairness-aware learning models. Our study shows that the choice of the fairness measure is important, likewise for the choice of the grade threshold.
Multiple Fairness and Cardinality constraints for Students-Topics Grouping Problem
Jun 20, 2022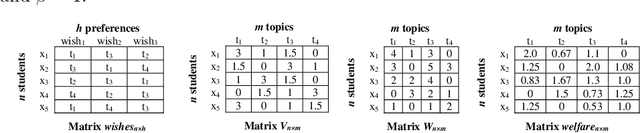


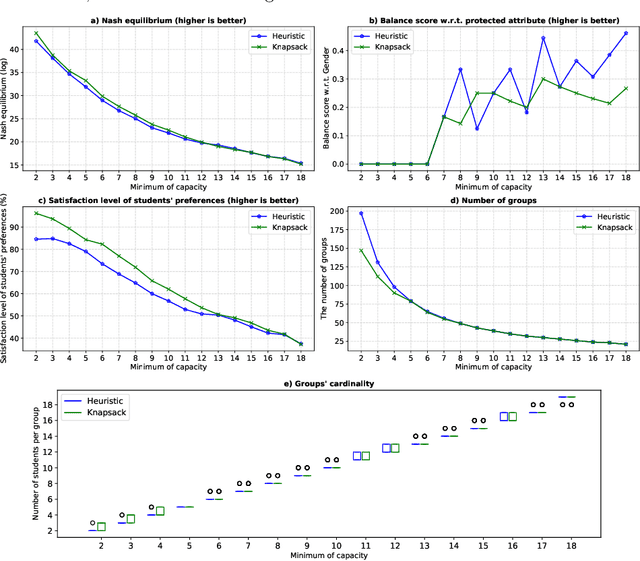
Group work is a prevalent activity in educational settings, where students are often divided into topic-specific groups based on their preferences. The grouping should reflect the students' aspirations as much as possible. Usually, the resulting groups should also be balanced in terms of protected attributes like gender or race since studies indicate that students might learn better in a diverse group. Moreover, balancing the group cardinalities is also an essential requirement for fair workload distribution across the groups. In this paper, we introduce the multi-fair capacitated (MFC) grouping problem that fairly partitions students into non-overlapping groups while ensuring balanced group cardinalities (with a lower bound and an upper bound), and maximizing the diversity of members in terms of protected attributes. We propose two approaches: a heuristic method and a knapsack-based method to obtain the MFC grouping. The experiments on a real dataset and a semi-synthetic dataset show that our proposed methods can satisfy students' preferences well and deliver balanced and diverse groups regarding cardinality and the protected attribute, respectively.
Attention Mechanism based Cognition-level Scene Understanding
Apr 19, 2022
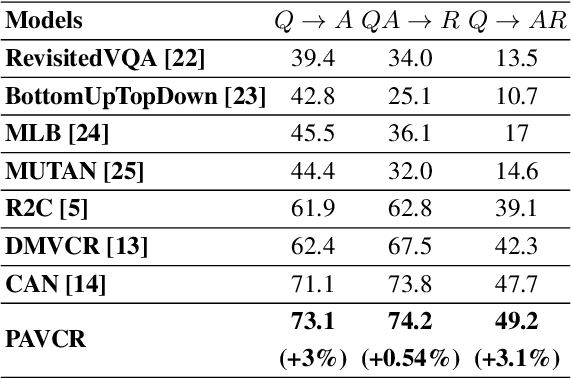
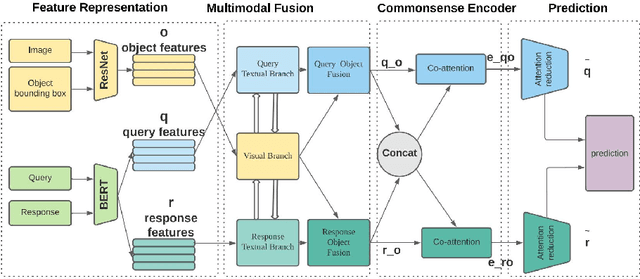

Given a question-image input, the Visual Commonsense Reasoning (VCR) model can predict an answer with the corresponding rationale, which requires inference ability from the real world. The VCR task, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge, is a cognition-level scene understanding task. The VCR task has aroused researchers' interest due to its wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and losing information in long sequences. In this paper, we propose a parallel attention-based cognitive VCR network PAVCR, which fuses visual-textual information efficiently and encodes semantic information in parallel to enable the model to capture rich information for cognition-level inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning.
A survey on datasets for fairness-aware machine learning
Oct 01, 2021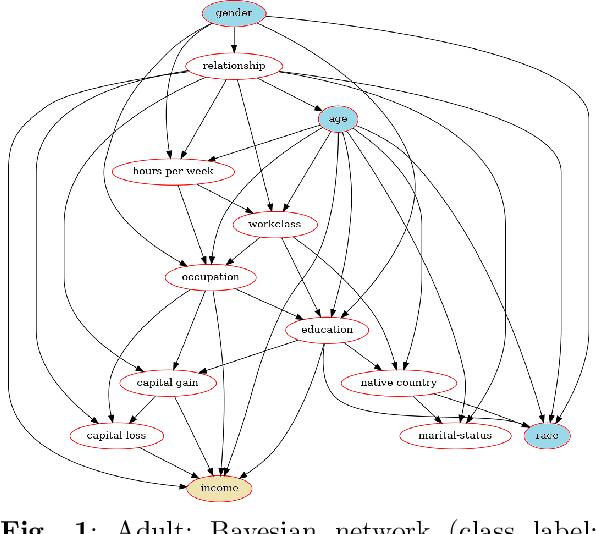
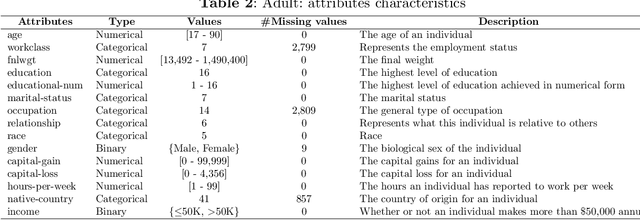
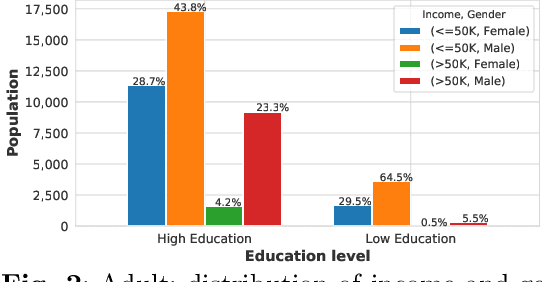
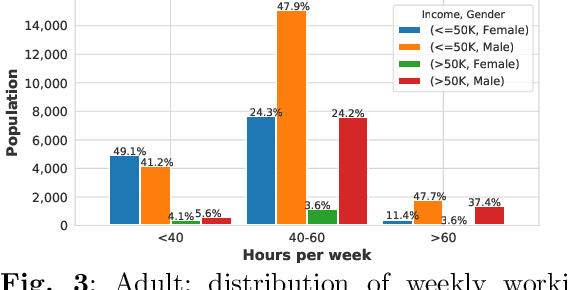
As decision-making increasingly relies on machine learning and (big) data, the issue of fairness in data-driven AI systems is receiving increasing attention from both research and industry. A large variety of fairness-aware machine learning solutions have been proposed which propose fairness-related interventions in the data, learning algorithms and/or model outputs. However, a vital part of proposing new approaches is evaluating them empirically on benchmark datasets that represent realistic and diverse settings. Therefore, in this paper, we overview real-world datasets used for fairness-aware machine learning. We focus on tabular data as the most common data representation for fairness-aware machine learning. We start our analysis by identifying relationships among the different attributes, particularly w.r.t. protected attributes and class attributes, using a Bayesian network. For a deeper understanding of bias and fairness in the datasets, we investigate the interesting relationships using exploratory analysis.
Fair-Capacitated Clustering
Apr 28, 2021



Traditionally, clustering algorithms focus on partitioning the data into groups of similar instances. The similarity objective, however, is not sufficient in applications where a fair-representation of the groups in terms of protected attributes like gender or race, is required for each cluster. Moreover, in many applications, to make the clusters useful for the end-user, a balanced cardinality among the clusters is required. Our motivation comes from the education domain where studies indicate that students might learn better in diverse student groups and of course groups of similar cardinality are more practical e.g., for group assignments. To this end, we introduce the fair-capacitated clustering problem that partitions the data into clusters of similar instances while ensuring cluster fairness and balancing cluster cardinalities. We propose a two-step solution to the problem: i) we rely on fairlets to generate minimal sets that satisfy the fair constraint and ii) we propose two approaches, namely hierarchical clustering and partitioning-based clustering, to obtain the fair-capacitated clustering. The hierarchical approach embeds the additional cardinality requirements during the merging step while the partitioning-based one alters the assignment step using a knapsack problem formulation to satisfy the additional requirements. Our experiments on four educational datasets show that our approaches deliver well-balanced clusters in terms of both fairness and cardinality while maintaining a good clustering quality.
Data augmentation for dealing with low sampling rates in NILM
Mar 30, 2021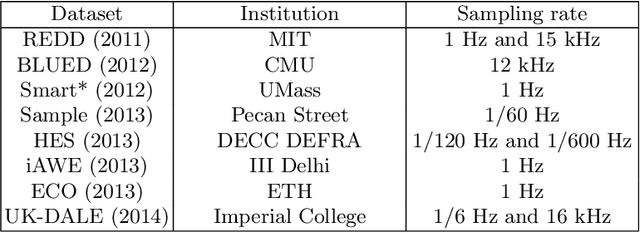
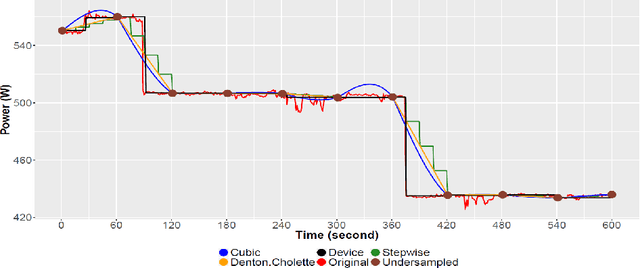


Data have an important role in evaluating the performance of NILM algorithms. The best performance of NILM algorithms is achieved with high-quality evaluation data. However, many existing real-world data sets come with a low sampling quality, and often with gaps, lacking data for some recording periods. As a result, in such data, NILM algorithms can hardly recognize devices and estimate their power consumption properly. An important step towards improving the performance of these energy disaggregation methods is to improve the quality of the data sets. In this paper, we carry out experiments using several methods to increase the sampling rate of low sampling rate data. Our results show that augmentation of low-frequency data can support the considered NILM algorithms in estimating appliances' consumption with a higher F-score measurement.