 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceNAS: Zero-shot LLM Pruning via Gradient Trace Correlation
Feb 02, 2026Structured pruning is essential for efficient deployment of Large Language Models (LLMs). The varying sensitivity of LLM sub-blocks to pruning necessitates the identification of optimal non-uniformly pruned models. Existing methods evaluate the importance of layers, attention heads, or weight channels in isolation. Such localized focus ignores the complex global structural dependencies that exist across the model. Training-aware structured pruning addresses global dependencies, but its computational cost can be just as expensive as post-pruning training. To alleviate the computational burden of training-aware pruning and capture global structural dependencies, we propose TraceNAS, a training-free Neural Architecture Search (NAS) framework that jointly explores structured pruning of LLM depth and width. TraceNAS identifies pruned models that maintain a high degree of loss landscape alignment with the pretrained model using a scale-invariant zero-shot proxy, effectively selecting models that exhibit maximal performance potential during post-pruning training. TraceNAS is highly efficient, enabling high-fidelity discovery of pruned models on a single GPU in 8.5 hours, yielding a 10$\times$ reduction in GPU-hours compared to training-aware methods. Evaluations on the Llama and Qwen families demonstrate that TraceNAS is competitive with training-aware baselines across commonsense and reasoning benchmarks.
TopoPrune: Robust Data Pruning via Unified Latent Space Topology
Feb 02, 2026Geometric data pruning methods, while practical for leveraging pretrained models, are fundamentally unstable. Their reliance on extrinsic geometry renders them highly sensitive to latent space perturbations, causing performance to degrade during cross-architecture transfer or in the presence of feature noise. We introduce TopoPrune, a framework which resolves this challenge by leveraging topology to capture the stable, intrinsic structure of data. TopoPrune operates at two scales, (1) utilizing a topology-aware manifold approximation to establish a global low-dimensional embedding of the dataset. Subsequently, (2) it employs differentiable persistent homology to perform a local topological optimization on the manifold embeddings, ranking samples by their structural complexity. We demonstrate that our unified dual-scale topological approach ensures high accuracy and precision, particularly at significant dataset pruning rates (e.g., 90%). Furthermore, through the inherent stability properties of topology, TopoPrune is (a) exceptionally robust to noise perturbations of latent feature embeddings and (b) demonstrates superior transferability across diverse network architectures. This study demonstrates a promising avenue towards stable and principled topology-based frameworks for robust data-efficient learning.
MMM-fair: An Interactive Toolkit for Exploring and Operationalizing Multi-Fairness Trade-offs
Sep 09, 2025Fairness-aware classification requires balancing performance and fairness, often intensified by intersectional biases. Conflicting fairness definitions further complicate the task, making it difficult to identify universally fair solutions. Despite growing regulatory and societal demands for equitable AI, popular toolkits offer limited support for exploring multi-dimensional fairness and related trade-offs. To address this, we present mmm-fair, an open-source toolkit leveraging boosting-based ensemble approaches that dynamically optimizes model weights to jointly minimize classification errors and diverse fairness violations, enabling flexible multi-objective optimization. The system empowers users to deploy models that align with their context-specific needs while reliably uncovering intersectional biases often missed by state-of-the-art methods. In a nutshell, mmm-fair uniquely combines in-depth multi-attribute fairness, multi-objective optimization, a no-code, chat-based interface, LLM-powered explanations, interactive Pareto exploration for model selection, custom fairness constraint definition, and deployment-ready models in a single open-source toolkit, a combination rarely found in existing fairness tools. Demo walkthrough available at: https://youtu.be/_rcpjlXFqkw.
Achieving Hilbert-Schmidt Independence Under Rényi Differential Privacy for Fair and Private Data Generation
Aug 29, 2025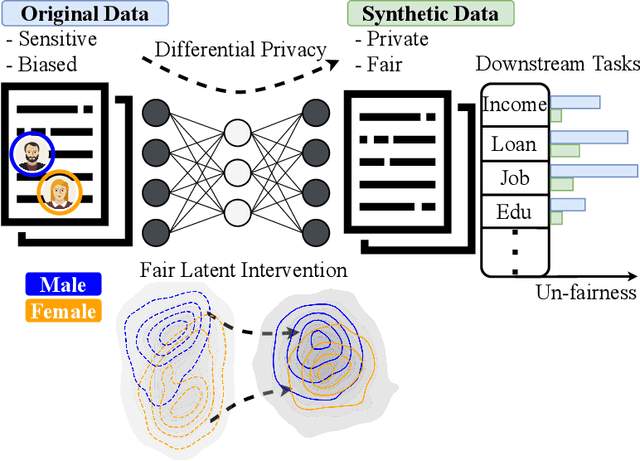
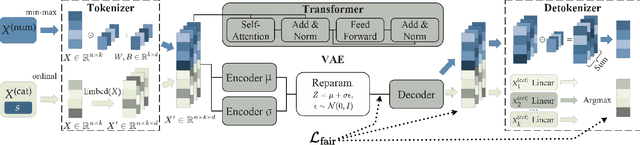

As privacy regulations such as the GDPR and HIPAA and responsibility frameworks for artificial intelligence such as the AI Act gain traction, the ethical and responsible use of real-world data faces increasing constraints. Synthetic data generation has emerged as a promising solution to risk-aware data sharing and model development, particularly for tabular datasets that are foundational to sensitive domains such as healthcare. To address both privacy and fairness concerns in this setting, we propose FLIP (Fair Latent Intervention under Privacy guarantees), a transformer-based variational autoencoder augmented with latent diffusion to generate heterogeneous tabular data. Unlike the typical setup in fairness-aware data generation, we assume a task-agnostic setup, not reliant on a fixed, defined downstream task, thus offering broader applicability. To ensure privacy, FLIP employs R\'enyi differential privacy (RDP) constraints during training and addresses fairness in the input space with RDP-compatible balanced sampling that accounts for group-specific noise levels across multiple sampling rates. In the latent space, we promote fairness by aligning neuron activation patterns across protected groups using Centered Kernel Alignment (CKA), a similarity measure extending the Hilbert-Schmidt Independence Criterion (HSIC). This alignment encourages statistical independence between latent representations and the protected feature. Empirical results demonstrate that FLIP effectively provides significant fairness improvements for task-agnostic fairness and across diverse downstream tasks under differential privacy constraints.
ALMA: Aggregated Lipschitz Maximization Attack on Auto-encoders
May 06, 2025Despite the extensive use of deep autoencoders (AEs) in critical applications, their adversarial robustness remains relatively underexplored compared to classification models. AE robustness is characterized by the Lipschitz bounds of its components. Existing robustness evaluation frameworks based on white-box attacks do not fully exploit the vulnerabilities of intermediate ill-conditioned layers in AEs. In the context of optimizing imperceptible norm-bounded additive perturbations to maximize output damage, existing methods struggle to effectively propagate adversarial loss gradients throughout the network, often converging to less effective perturbations. To address this, we propose a novel layer-conditioning-based adversarial optimization objective that effectively guides the adversarial map toward regions of local Lipschitz bounds by enhancing loss gradient information propagation during attack optimization. We demonstrate through extensive experiments on state-of-the-art AEs that our adversarial objective results in stronger attacks, outperforming existing methods in both universal and sample-specific scenarios. As a defense method against this attack, we introduce an inference-time adversarially trained defense plugin that mitigates the effects of adversarial examples.
Synthetic Tabular Data Generation for Class Imbalance and Fairness: A Comparative Study
Sep 08, 2024



Due to their data-driven nature, Machine Learning (ML) models are susceptible to bias inherited from data, especially in classification problems where class and group imbalances are prevalent. Class imbalance (in the classification target) and group imbalance (in protected attributes like sex or race) can undermine both ML utility and fairness. Although class and group imbalances commonly coincide in real-world tabular datasets, limited methods address this scenario. While most methods use oversampling techniques, like interpolation, to mitigate imbalances, recent advancements in synthetic tabular data generation offer promise but have not been adequately explored for this purpose. To this end, this paper conducts a comparative analysis to address class and group imbalances using state-of-the-art models for synthetic tabular data generation and various sampling strategies. Experimental results on four datasets, demonstrate the effectiveness of generative models for bias mitigation, creating opportunities for further exploration in this direction.
DCT-CryptoNets: Scaling Private Inference in the Frequency Domain
Aug 27, 2024The convergence of fully homomorphic encryption (FHE) and machine learning offers unprecedented opportunities for private inference of sensitive data. FHE enables computation directly on encrypted data, safeguarding the entire machine learning pipeline, including data and model confidentiality. However, existing FHE-based implementations for deep neural networks face significant challenges in computational cost, latency, and scalability, limiting their practical deployment. This paper introduces DCT-CryptoNets, a novel approach that leverages frequency-domain learning to tackle these issues. Our method operates directly in the frequency domain, utilizing the discrete cosine transform (DCT) commonly employed in JPEG compression. This approach is inherently compatible with remote computing services, where images are usually transmitted and stored in compressed formats. DCT-CryptoNets reduces the computational burden of homomorphic operations by focusing on perceptually relevant low-frequency components. This is demonstrated by substantial latency reduction of up to 5.3$\times$ compared to prior work on image classification tasks, including a novel demonstration of ImageNet inference within 2.5 hours, down from 12.5 hours compared to prior work on equivalent compute resources. Moreover, DCT-CryptoNets improves the reliability of encrypted accuracy by reducing variability (e.g., from $\pm$2.5\% to $\pm$1.0\% on ImageNet). This study demonstrates a promising avenue for achieving efficient and practical privacy-preserving deep learning on high resolution images seen in real-world applications.
Adversarial Robustness of VAEs across Intersectional Subgroups
Jul 04, 2024Despite advancements in Autoencoders (AEs) for tasks like dimensionality reduction, representation learning and data generation, they remain vulnerable to adversarial attacks. Variational Autoencoders (VAEs), with their probabilistic approach to disentangling latent spaces, show stronger resistance to such perturbations compared to deterministic AEs; however, their resilience against adversarial inputs is still a concern. This study evaluates the robustness of VAEs against non-targeted adversarial attacks by optimizing minimal sample-specific perturbations to cause maximal damage across diverse demographic subgroups (combinations of age and gender). We investigate two questions: whether there are robustness disparities among subgroups, and what factors contribute to these disparities, such as data scarcity and representation entanglement. Our findings reveal that robustness disparities exist but are not always correlated with the size of the subgroup. By using downstream gender and age classifiers and examining latent embeddings, we highlight the vulnerability of subgroups like older women, who are prone to misclassification due to adversarial perturbations pushing their representations toward those of other subgroups.
FairBranch: Fairness Conflict Correction on Task-group Branches for Fair Multi-Task Learning
Oct 20, 2023
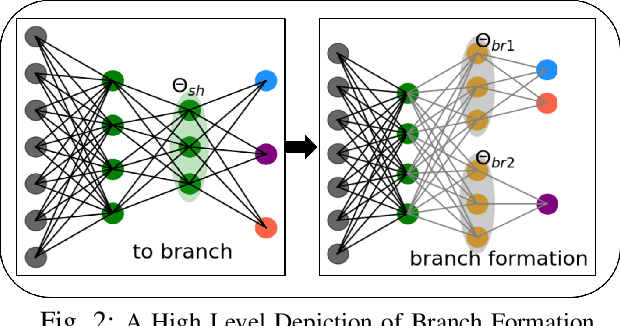
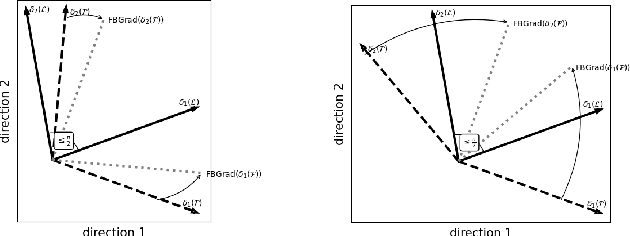
The generalization capacity of Multi-Task Learning (MTL) becomes limited when unrelated tasks negatively impact each other by updating shared parameters with conflicting gradients, resulting in negative transfer and a reduction in MTL accuracy compared to single-task learning (STL). Recently, there has been an increasing focus on the fairness of MTL models, necessitating the optimization of both accuracy and fairness for individual tasks. Similarly to how negative transfer affects accuracy, task-specific fairness considerations can adversely influence the fairness of other tasks when there is a conflict of fairness loss gradients among jointly learned tasks, termed bias transfer. To address both negative and bias transfer in MTL, we introduce a novel method called FairBranch. FairBranch branches the MTL model by assessing the similarity of learned parameters, grouping related tasks to mitigate negative transfer. Additionally, it incorporates fairness loss gradient conflict correction between adjoining task-group branches to address bias transfer within these task groups. Our experiments in tabular and visual MTL problems demonstrate that FairBranch surpasses state-of-the-art MTL methods in terms of both fairness and accuracy.
Multi-dimensional discrimination in Law and Machine Learning -- A comparative overview
Feb 12, 2023AI-driven decision-making can lead to discrimination against certain individuals or social groups based on protected characteristics/attributes such as race, gender, or age. The domain of fairness-aware machine learning focuses on methods and algorithms for understanding, mitigating, and accounting for bias in AI/ML models. Still, thus far, the vast majority of the proposed methods assess fairness based on a single protected attribute, e.g. only gender or race. In reality, though, human identities are multi-dimensional, and discrimination can occur based on more than one protected characteristic, leading to the so-called ``multi-dimensional discrimination'' or ``multi-dimensional fairness'' problem. While well-elaborated in legal literature, the multi-dimensionality of discrimination is less explored in the machine learning community. Recent approaches in this direction mainly follow the so-called intersectional fairness definition from the legal domain, whereas other notions like additive and sequential discrimination are less studied or not considered thus far. In this work, we overview the different definitions of multi-dimensional discrimination/fairness in the legal domain as well as how they have been transferred/ operationalized (if) in the fairness-aware machine learning domain. By juxtaposing these two domains, we draw the connections, identify the limitations, and point out open research directions.