 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Hilbert-Schmidt Independence Under Rényi Differential Privacy for Fair and Private Data Generation
Aug 29, 2025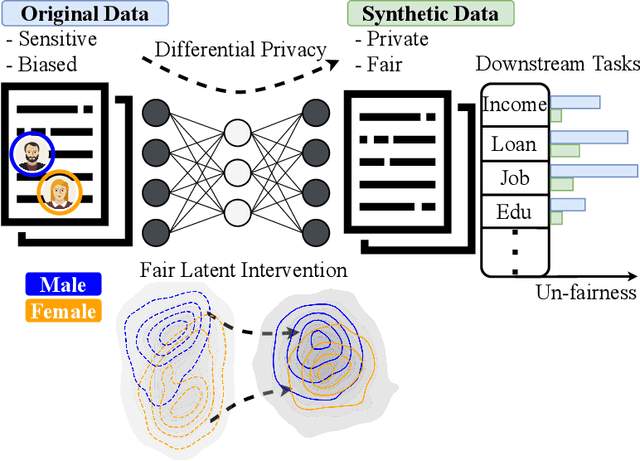
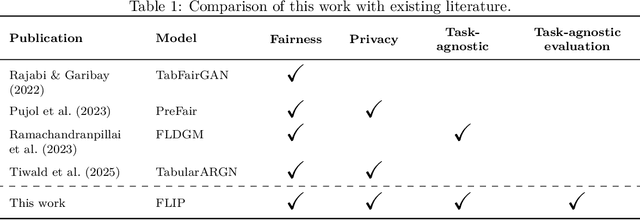
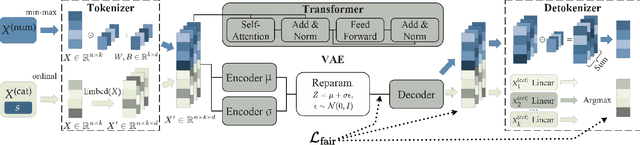

As privacy regulations such as the GDPR and HIPAA and responsibility frameworks for artificial intelligence such as the AI Act gain traction, the ethical and responsible use of real-world data faces increasing constraints. Synthetic data generation has emerged as a promising solution to risk-aware data sharing and model development, particularly for tabular datasets that are foundational to sensitive domains such as healthcare. To address both privacy and fairness concerns in this setting, we propose FLIP (Fair Latent Intervention under Privacy guarantees), a transformer-based variational autoencoder augmented with latent diffusion to generate heterogeneous tabular data. Unlike the typical setup in fairness-aware data generation, we assume a task-agnostic setup, not reliant on a fixed, defined downstream task, thus offering broader applicability. To ensure privacy, FLIP employs R\'enyi differential privacy (RDP) constraints during training and addresses fairness in the input space with RDP-compatible balanced sampling that accounts for group-specific noise levels across multiple sampling rates. In the latent space, we promote fairness by aligning neuron activation patterns across protected groups using Centered Kernel Alignment (CKA), a similarity measure extending the Hilbert-Schmidt Independence Criterion (HSIC). This alignment encourages statistical independence between latent representations and the protected feature. Empirical results demonstrate that FLIP effectively provides significant fairness improvements for task-agnostic fairness and across diverse downstream tasks under differential privacy constraints.
FSDEM: Feature Selection Dynamic Evaluation Metric
Aug 26, 2024Expressive evaluation metrics are indispensable for informative experiments in all areas, and while several metrics are established in some areas, in others, such as feature selection, only indirect or otherwise limited evaluation metrics are found. In this paper, we propose a novel evaluation metric to address several problems of its predecessors and allow for flexible and reliable evaluation of feature selection algorithms. The proposed metric is a dynamic metric with two properties that can be used to evaluate both the performance and the stability of a feature selection algorithm. We conduct several empirical experiments to illustrate the use of the proposed metric in the successful evaluation of feature selection algorithms. We also provide a comparison and analysis to show the different aspects involved in the evaluation of the feature selection algorithms. The results indicate that the proposed metric is successful in carrying out the evaluation task for feature selection algorithms. This paper is an extended version of a paper accepted at SISAP 2024.
SynthEval: A Framework for Detailed Utility and Privacy Evaluation of Tabular Synthetic Data
Apr 24, 2024With the growing demand for synthetic data to address contemporary issues in machine learning, such as data scarcity, data fairness, and data privacy, having robust tools for assessing the utility and potential privacy risks of such data becomes crucial. SynthEval, a novel open-source evaluation framework distinguishes itself from existing tools by treating categorical and numerical attributes with equal care, without assuming any special kind of preprocessing steps. This~makes it applicable to virtually any synthetic dataset of tabular records. Our tool leverages statistical and machine learning techniques to comprehensively evaluate synthetic data fidelity and privacy-preserving integrity. SynthEval integrates a wide selection of metrics that can be used independently or in highly customisable benchmark configurations, and can easily be extended with additional metrics. In this paper, we describe SynthEval and illustrate its versatility with examples. The framework facilitates better benchmarking and more consistent comparisons of model capabilities.
Sharing is CAIRing: Characterizing Principles and Assessing Properties of Universal Privacy Evaluation for Synthetic Tabular Data
Dec 19, 2023



Data sharing is a necessity for innovative progress in many domains, especially in healthcare. However, the ability to share data is hindered by regulations protecting the privacy of natural persons. Synthetic tabular data provide a promising solution to address data sharing difficulties but does not inherently guarantee privacy. Still, there is a lack of agreement on appropriate methods for assessing the privacy-preserving capabilities of synthetic data, making it difficult to compare results across studies. To the best of our knowledge, this is the first work to identify properties that constitute good universal privacy evaluation metrics for synthetic tabular data. The goal of such metrics is to enable comparability across studies and to allow non-technical stakeholders to understand how privacy is protected. We identify four principles for the assessment of metrics: Comparability, Applicability, Interpretability, and Representativeness (CAIR). To quantify and rank the degree to which evaluation metrics conform to the CAIR principles, we design a rubric using a scale of 1-4. Each of the four properties is scored on four parameters, yielding 16 total dimensions. We study the applicability and usefulness of the CAIR principles and rubric by assessing a selection of metrics popular in other studies. The results provide granular insights into the strengths and weaknesses of existing metrics that not only rank the metrics but highlight areas of potential improvements. We expect that the CAIR principles will foster agreement among researchers and organizations on which universal privacy evaluation metrics are appropriate for synthetic tabular data.