 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALMA: Aggregated Lipschitz Maximization Attack on Auto-encoders
May 06, 2025Despite the extensive use of deep autoencoders (AEs) in critical applications, their adversarial robustness remains relatively underexplored compared to classification models. AE robustness is characterized by the Lipschitz bounds of its components. Existing robustness evaluation frameworks based on white-box attacks do not fully exploit the vulnerabilities of intermediate ill-conditioned layers in AEs. In the context of optimizing imperceptible norm-bounded additive perturbations to maximize output damage, existing methods struggle to effectively propagate adversarial loss gradients throughout the network, often converging to less effective perturbations. To address this, we propose a novel layer-conditioning-based adversarial optimization objective that effectively guides the adversarial map toward regions of local Lipschitz bounds by enhancing loss gradient information propagation during attack optimization. We demonstrate through extensive experiments on state-of-the-art AEs that our adversarial objective results in stronger attacks, outperforming existing methods in both universal and sample-specific scenarios. As a defense method against this attack, we introduce an inference-time adversarially trained defense plugin that mitigates the effects of adversarial examples.
Adversarial Robustness of VAEs across Intersectional Subgroups
Jul 04, 2024Despite advancements in Autoencoders (AEs) for tasks like dimensionality reduction, representation learning and data generation, they remain vulnerable to adversarial attacks. Variational Autoencoders (VAEs), with their probabilistic approach to disentangling latent spaces, show stronger resistance to such perturbations compared to deterministic AEs; however, their resilience against adversarial inputs is still a concern. This study evaluates the robustness of VAEs against non-targeted adversarial attacks by optimizing minimal sample-specific perturbations to cause maximal damage across diverse demographic subgroups (combinations of age and gender). We investigate two questions: whether there are robustness disparities among subgroups, and what factors contribute to these disparities, such as data scarcity and representation entanglement. Our findings reveal that robustness disparities exist but are not always correlated with the size of the subgroup. By using downstream gender and age classifiers and examining latent embeddings, we highlight the vulnerability of subgroups like older women, who are prone to misclassification due to adversarial perturbations pushing their representations toward those of other subgroups.
Ensuring Topological Data-Structure Preservation under Autoencoder Compression due to Latent Space Regularization in Gauss--Legendre nodes
Sep 21, 2023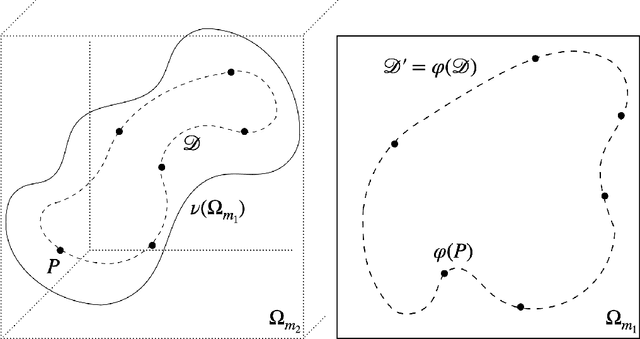
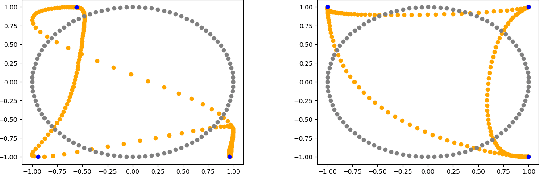
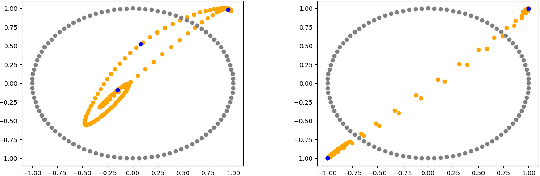
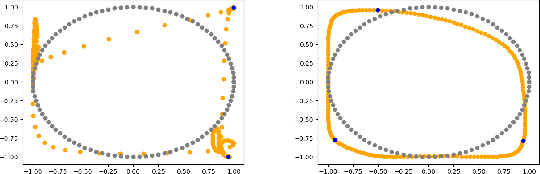
We formulate a data independent latent space regularisation constraint for general unsupervised autoencoders. The regularisation rests on sampling the autoencoder Jacobian in Legendre nodes, being the centre of the Gauss-Legendre quadrature. Revisiting this classic enables to prove that regularised autoencoders ensure a one-to-one re-embedding of the initial data manifold to its latent representation. Demonstrations show that prior proposed regularisation strategies, such as contractive autoencoding, cause topological defects already for simple examples, and so do convolutional based (variational) autoencoders. In contrast, topological preservation is ensured already by standard multilayer perceptron neural networks when being regularised due to our contribution. This observation extends through the classic FashionMNIST dataset up to real world encoding problems for MRI brain scans, suggesting that, across disciplines, reliable low dimensional representations of complex high-dimensional datasets can be delivered due to this regularisation technique.