 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating db-A* for Kinodynamic Motion Planning Using Diffusion
Mar 10, 2025We present a novel approach for generating motion primitives for kinodynamic motion planning using diffusion models. The motions generated by our approach are adapted to each problem instance by utilizing problem-specific parameters, allowing for finding solutions faster and of better quality. The diffusion models used in our approach are trained on randomly cut solution trajectories. These trajectories are created by solving randomly generated problem instances with a kinodynamic motion planner. Experimental results show significant improvements up to 30 percent in both computation time and solution quality across varying robot dynamics such as second-order unicycle or car with trailer.
Accelerating db-A$^\textbf{*}$ for Kinodynamic Motion Planning Using Diffusion
Mar 07, 2025We present a novel approach for generating motion primitives for kinodynamic motion planning using diffusion models. The motions generated by our approach are adapted to each problem instance by utilizing problem-specific parameters, allowing for finding solutions faster and of better quality. The diffusion models used in our approach are trained on randomly cut solution trajectories. These trajectories are created by solving randomly generated problem instances with a kinodynamic motion planner. Experimental results show significant improvements up to 30 percent in both computation time and solution quality across varying robot dynamics such as second-order unicycle or car with trailer.
Ensuring Topological Data-Structure Preservation under Autoencoder Compression due to Latent Space Regularization in Gauss--Legendre nodes
Sep 21, 2023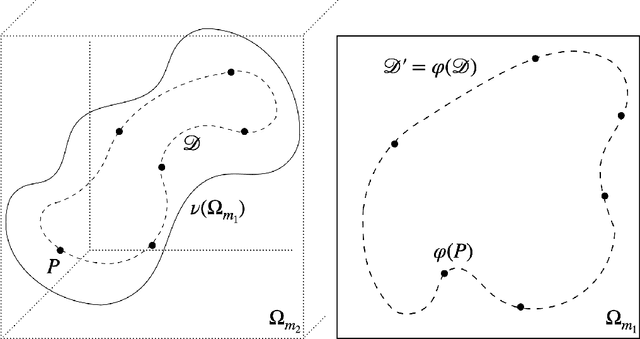
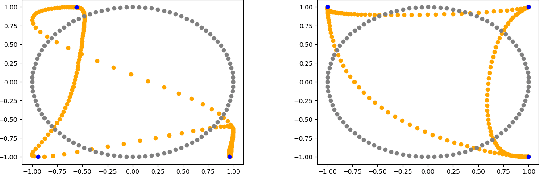
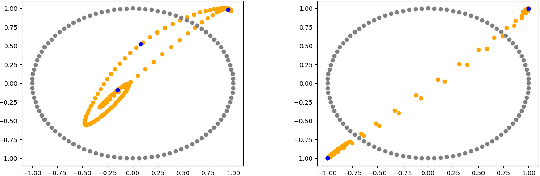
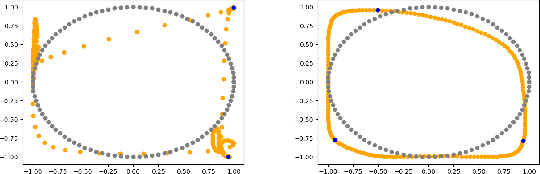
We formulate a data independent latent space regularisation constraint for general unsupervised autoencoders. The regularisation rests on sampling the autoencoder Jacobian in Legendre nodes, being the centre of the Gauss-Legendre quadrature. Revisiting this classic enables to prove that regularised autoencoders ensure a one-to-one re-embedding of the initial data manifold to its latent representation. Demonstrations show that prior proposed regularisation strategies, such as contractive autoencoding, cause topological defects already for simple examples, and so do convolutional based (variational) autoencoders. In contrast, topological preservation is ensured already by standard multilayer perceptron neural networks when being regularised due to our contribution. This observation extends through the classic FashionMNIST dataset up to real world encoding problems for MRI brain scans, suggesting that, across disciplines, reliable low dimensional representations of complex high-dimensional datasets can be delivered due to this regularisation technique.
Kidnapping Deep Learning-based Multirotors using Optimized Flying Adversarial Patches
Aug 01, 2023
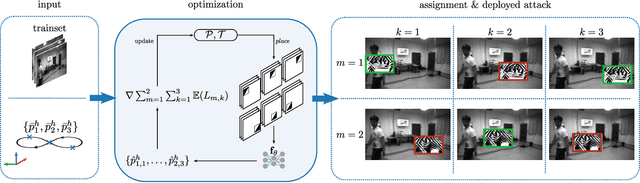
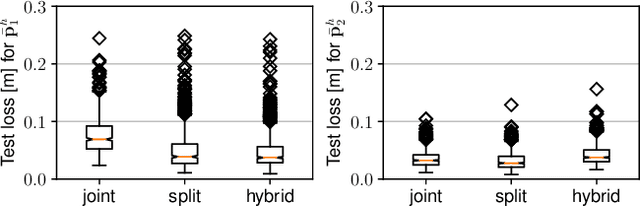
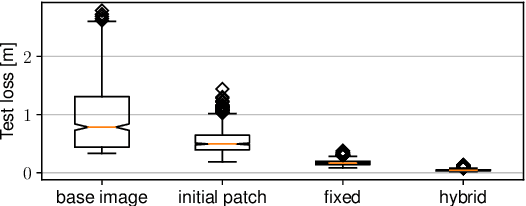
Autonomous flying robots, such as multirotors, often rely on deep learning models that makes predictions based on a camera image, e.g. for pose estimation. These models can predict surprising results if applied to input images outside the training domain. This fault can be exploited by adversarial attacks, for example, by computing small images, so-called adversarial patches, that can be placed in the environment to manipulate the neural network's prediction. We introduce flying adversarial patches, where multiple images are mounted on at least one other flying robot and therefore can be placed anywhere in the field of view of a victim multirotor. By introducing the attacker robots, the system is extended to an adversarial multi-robot system. For an effective attack, we compare three methods that simultaneously optimize multiple adversarial patches and their position in the input image. We show that our methods scale well with the number of adversarial patches. Moreover, we demonstrate physical flights with two robots, where we employ a novel attack policy that uses the computed adversarial patches to kidnap a robot that was supposed to follow a human.
Flying Adversarial Patches: Manipulating the Behavior of Deep Learning-based Autonomous Multirotors
May 22, 2023Autonomous flying robots, e.g. multirotors, often rely on a neural network that makes predictions based on a camera image. These deep learning (DL) models can compute surprising results if applied to input images outside the training domain. Adversarial attacks exploit this fault, for example, by computing small images, so-called adversarial patches, that can be placed in the environment to manipulate the neural network's prediction. We introduce flying adversarial patches, where an image is mounted on another flying robot and therefore can be placed anywhere in the field of view of a victim multirotor. For an effective attack, we compare three methods that simultaneously optimize the adversarial patch and its position in the input image. We perform an empirical validation on a publicly available DL model and dataset for autonomous multirotors. Ultimately, our attacking multirotor would be able to gain full control over the motions of the victim multirotor.
InFlow: Robust outlier detection utilizing Normalizing Flows
Jun 10, 2021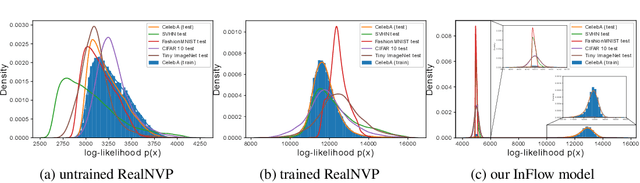
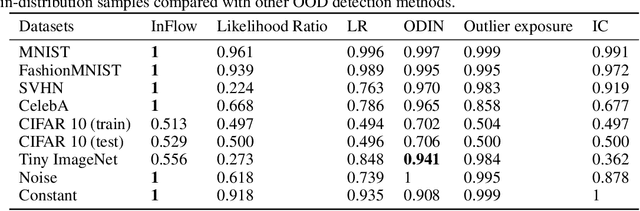
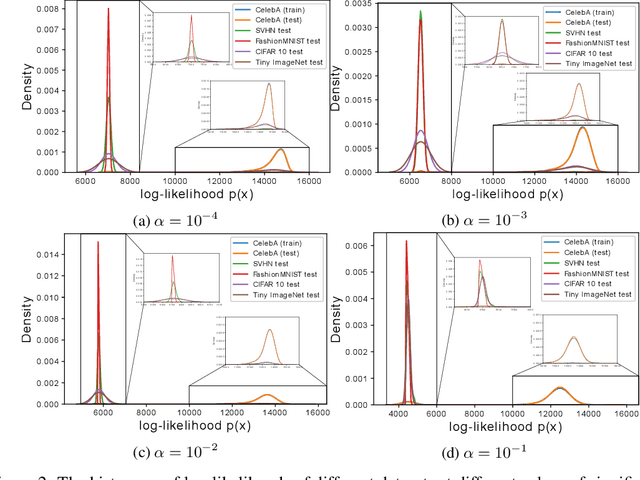
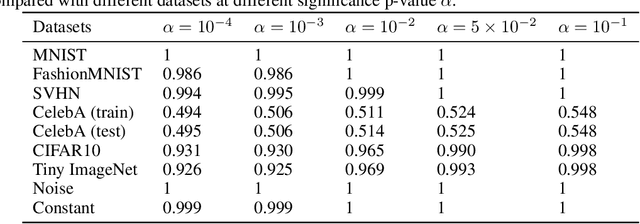
Normalizing flows are prominent deep generative models that provide tractable probability distributions and efficient density estimation. However, they are well known to fail while detecting Out-of-Distribution (OOD) inputs as they directly encode the local features of the input representations in their latent space. In this paper, we solve this overconfidence issue of normalizing flows by demonstrating that flows, if extended by an attention mechanism, can reliably detect outliers including adversarial attacks. Our approach does not require outlier data for training and we showcase the efficiency of our method for OOD detection by reporting state-of-the-art performance in diverse experimental settings. Code available at https://github.com/ComputationalRadiationPhysics/InFlow .