 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn experimental study on fairness-aware machine learning for credit scoring problem
Dec 28, 2024



Digitalization of credit scoring is an essential requirement for financial organizations and commercial banks, especially in the context of digital transformation. Machine learning techniques are commonly used to evaluate customers' creditworthiness. However, the predicted outcomes of machine learning models can be biased toward protected attributes, such as race or gender. Numerous fairness-aware machine learning models and fairness measures have been proposed. Nevertheless, their performance in the context of credit scoring has not been thoroughly investigated. In this paper, we present a comprehensive experimental study of fairness-aware machine learning in credit scoring. The study explores key aspects of credit scoring, including financial datasets, predictive models, and fairness measures. We also provide a detailed evaluation of fairness-aware predictive models and fairness measures on widely used financial datasets.
Fairness Definitions in Language Models Explained
Jul 26, 2024



Language Models (LMs) have demonstrated exceptional performance across various Natural Language Processing (NLP) tasks. Despite these advancements, LMs can inherit and amplify societal biases related to sensitive attributes such as gender and race, limiting their adoption in real-world applications. Therefore, fairness has been extensively explored in LMs, leading to the proposal of various fairness notions. However, the lack of clear agreement on which fairness definition to apply in specific contexts (\textit{e.g.,} medium-sized LMs versus large-sized LMs) and the complexity of understanding the distinctions between these definitions can create confusion and impede further progress. To this end, this paper proposes a systematic survey that clarifies the definitions of fairness as they apply to LMs. Specifically, we begin with a brief introduction to LMs and fairness in LMs, followed by a comprehensive, up-to-date overview of existing fairness notions in LMs and the introduction of a novel taxonomy that categorizes these concepts based on their foundational principles and operational distinctions. We further illustrate each definition through experiments, showcasing their practical implications and outcomes. Finally, we discuss current research challenges and open questions, aiming to foster innovative ideas and advance the field. The implementation and additional resources are publicly available at https://github.com/LavinWong/Fairness-in-Large-Language-Models/tree/main/definitions.
ToVo: Toxicity Taxonomy via Voting
Jun 21, 2024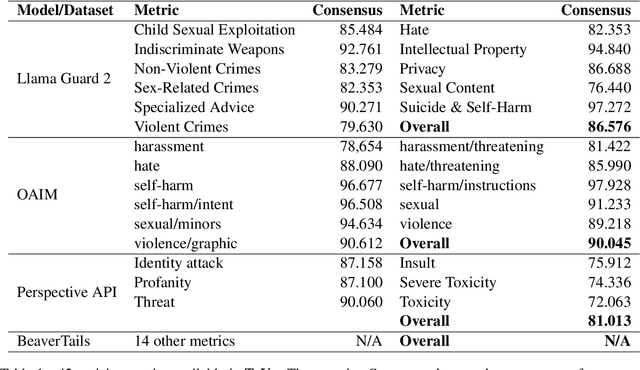



Existing toxic detection models face significant limitations, such as lack of transparency, customization, and reproducibility. These challenges stem from the closed-source nature of their training data and the paucity of explanations for their evaluation mechanism. To address these issues, we propose a dataset creation mechanism that integrates voting and chain-of-thought processes, producing a high-quality open-source dataset for toxic content detection. Our methodology ensures diverse classification metrics for each sample and includes both classification scores and explanatory reasoning for the classifications. We utilize the dataset created through our proposed mechanism to train our model, which is then compared against existing widely-used detectors. Our approach not only enhances transparency and customizability but also facilitates better fine-tuning for specific use cases. This work contributes a robust framework for developing toxic content detection models, emphasizing openness and adaptability, thus paving the way for more effective and user-specific content moderation solutions.