 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot, No Problem: Descriptive Continual Relation Extraction
Feb 27, 2025Few-shot Continual Relation Extraction is a crucial challenge for enabling AI systems to identify and adapt to evolving relationships in dynamic real-world domains. Traditional memory-based approaches often overfit to limited samples, failing to reinforce old knowledge, with the scarcity of data in few-shot scenarios further exacerbating these issues by hindering effective data augmentation in the latent space. In this paper, we propose a novel retrieval-based solution, starting with a large language model to generate descriptions for each relation. From these descriptions, we introduce a bi-encoder retrieval training paradigm to enrich both sample and class representation learning. Leveraging these enhanced representations, we design a retrieval-based prediction method where each sample "retrieves" the best fitting relation via a reciprocal rank fusion score that integrates both relation description vectors and class prototypes. Extensive experiments on multiple datasets demonstrate that our method significantly advances the state-of-the-art by maintaining robust performance across sequential tasks, effectively addressing catastrophic forgetting.
Adaptive Prompting for Continual Relation Extraction: A Within-Task Variance Perspective
Dec 12, 2024



To address catastrophic forgetting in Continual Relation Extraction (CRE), many current approaches rely on memory buffers to rehearse previously learned knowledge while acquiring new tasks. Recently, prompt-based methods have emerged as potent alternatives to rehearsal-based strategies, demonstrating strong empirical performance. However, upon analyzing existing prompt-based approaches for CRE, we identified several critical limitations, such as inaccurate prompt selection, inadequate mechanisms for mitigating forgetting in shared parameters, and suboptimal handling of cross-task and within-task variances. To overcome these challenges, we draw inspiration from the relationship between prefix-tuning and mixture of experts, proposing a novel approach that employs a prompt pool for each task, capturing variations within each task while enhancing cross-task variances. Furthermore, we incorporate a generative model to consolidate prior knowledge within shared parameters, eliminating the need for explicit data storage. Extensive experiments validate the efficacy of our approach, demonstrating superior performance over state-of-the-art prompt-based and rehearsal-free methods in continual relation extraction.
Lifelong Event Detection via Optimal Transport
Oct 11, 2024



Continual Event Detection (CED) poses a formidable challenge due to the catastrophic forgetting phenomenon, where learning new tasks (with new coming event types) hampers performance on previous ones. In this paper, we introduce a novel approach, Lifelong Event Detection via Optimal Transport (LEDOT), that leverages optimal transport principles to align the optimization of our classification module with the intrinsic nature of each class, as defined by their pre-trained language modeling. Our method integrates replay sets, prototype latent representations, and an innovative Optimal Transport component. Extensive experiments on MAVEN and ACE datasets demonstrate LEDOT's superior performance, consistently outperforming state-of-the-art baselines. The results underscore LEDOT as a pioneering solution in continual event detection, offering a more effective and nuanced approach to addressing catastrophic forgetting in evolving environments.
ToVo: Toxicity Taxonomy via Voting
Jun 21, 2024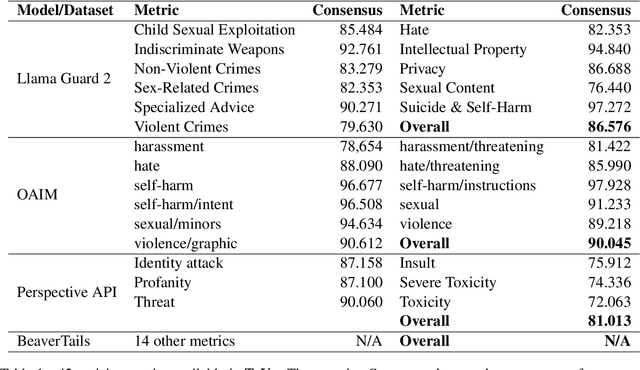



Existing toxic detection models face significant limitations, such as lack of transparency, customization, and reproducibility. These challenges stem from the closed-source nature of their training data and the paucity of explanations for their evaluation mechanism. To address these issues, we propose a dataset creation mechanism that integrates voting and chain-of-thought processes, producing a high-quality open-source dataset for toxic content detection. Our methodology ensures diverse classification metrics for each sample and includes both classification scores and explanatory reasoning for the classifications. We utilize the dataset created through our proposed mechanism to train our model, which is then compared against existing widely-used detectors. Our approach not only enhances transparency and customizability but also facilitates better fine-tuning for specific use cases. This work contributes a robust framework for developing toxic content detection models, emphasizing openness and adaptability, thus paving the way for more effective and user-specific content moderation solutions.
Realistic Evaluation of Toxicity in Large Language Models
May 17, 2024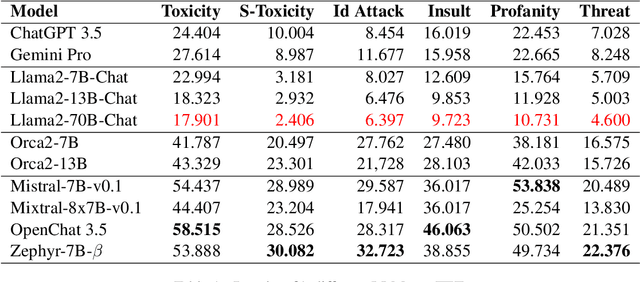

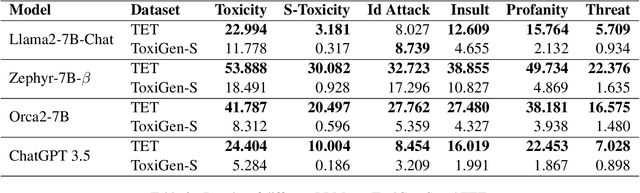

Large language models (LLMs) have become integral to our professional workflows and daily lives. Nevertheless, these machine companions of ours have a critical flaw: the huge amount of data which endows them with vast and diverse knowledge, also exposes them to the inevitable toxicity and bias. While most LLMs incorporate defense mechanisms to prevent the generation of harmful content, these safeguards can be easily bypassed with minimal prompt engineering. In this paper, we introduce the new Thoroughly Engineered Toxicity (TET) dataset, comprising manually crafted prompts designed to nullify the protective layers of such models. Through extensive evaluations, we demonstrate the pivotal role of TET in providing a rigorous benchmark for evaluation of toxicity awareness in several popular LLMs: it highlights the toxicity in the LLMs that might remain hidden when using normal prompts, thus revealing subtler issues in their behavior.