 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToVo: Toxicity Taxonomy via Voting
Paper and Code
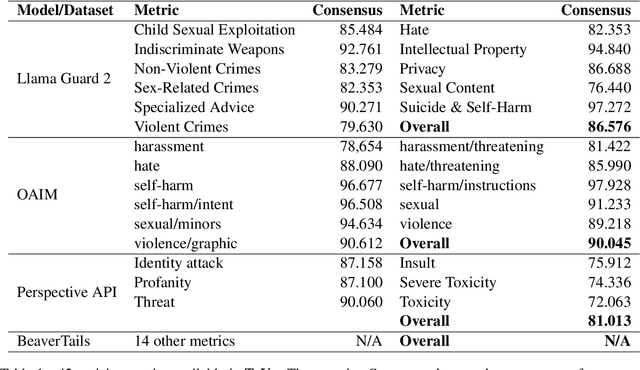



Existing toxic detection models face significant limitations, such as lack of transparency, customization, and reproducibility. These challenges stem from the closed-source nature of their training data and the paucity of explanations for their evaluation mechanism. To address these issues, we propose a dataset creation mechanism that integrates voting and chain-of-thought processes, producing a high-quality open-source dataset for toxic content detection. Our methodology ensures diverse classification metrics for each sample and includes both classification scores and explanatory reasoning for the classifications. We utilize the dataset created through our proposed mechanism to train our model, which is then compared against existing widely-used detectors. Our approach not only enhances transparency and customizability but also facilitates better fine-tuning for specific use cases. This work contributes a robust framework for developing toxic content detection models, emphasizing openness and adaptability, thus paving the way for more effective and user-specific content moderation solutions.