 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToVo: Toxicity Taxonomy via Voting
Jun 21, 2024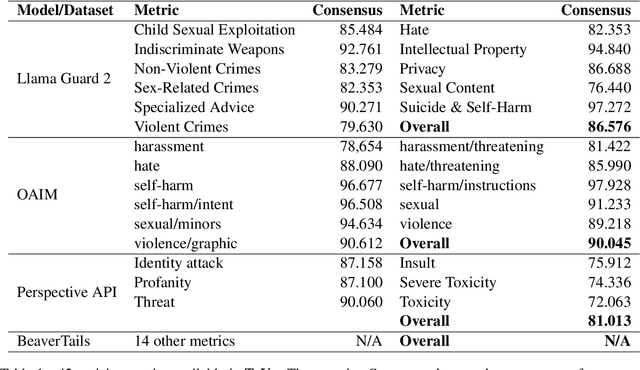



Existing toxic detection models face significant limitations, such as lack of transparency, customization, and reproducibility. These challenges stem from the closed-source nature of their training data and the paucity of explanations for their evaluation mechanism. To address these issues, we propose a dataset creation mechanism that integrates voting and chain-of-thought processes, producing a high-quality open-source dataset for toxic content detection. Our methodology ensures diverse classification metrics for each sample and includes both classification scores and explanatory reasoning for the classifications. We utilize the dataset created through our proposed mechanism to train our model, which is then compared against existing widely-used detectors. Our approach not only enhances transparency and customizability but also facilitates better fine-tuning for specific use cases. This work contributes a robust framework for developing toxic content detection models, emphasizing openness and adaptability, thus paving the way for more effective and user-specific content moderation solutions.
Revising FUNSD dataset for key-value detection in document images
Oct 11, 2020
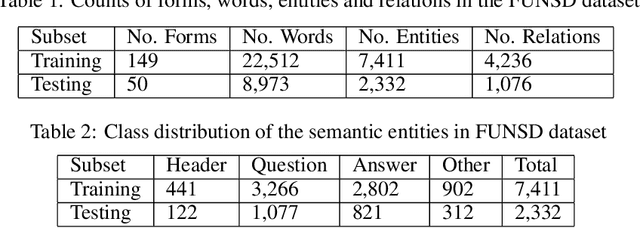
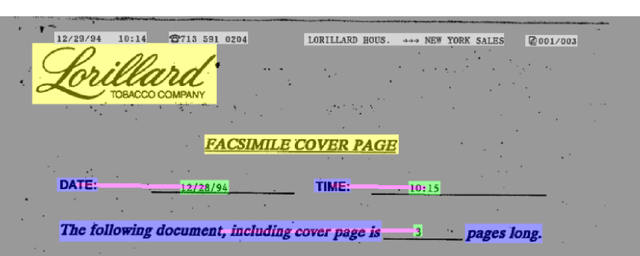

FUNSD is one of the limited publicly available datasets for information extraction from document im-ages. The information in the FUNSD dataset is defined by text areas of four categories ("key", "value", "header", "other", and "background") and connectivity between areas as key-value relations. In-specting FUNSD, we found several inconsistency in labeling, which impeded its applicability to thekey-value extraction problem. In this report, we described some labeling issues in FUNSD and therevision we made to the dataset. We also reported our implementation of for key-value detection onFUNSD using a UNet model as baseline results and an improved UNet model with Channel-InvariantDeformable Convolution.