 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngular Steering: Behavior Control via Rotation in Activation Space
Oct 30, 2025



Controlling specific behaviors in large language models while preserving their general capabilities is a central challenge for safe and reliable artificial intelligence deployment. Current steering methods, such as vector addition and directional ablation, are constrained within a two-dimensional subspace defined by the activation and feature direction, making them sensitive to chosen parameters and potentially affecting unrelated features due to unintended interactions in activation space. We introduce Angular Steering, a novel and flexible method for behavior modulation that operates by rotating activations within a fixed two-dimensional subspace. By formulating steering as a geometric rotation toward or away from a target behavior direction, Angular Steering provides continuous, fine-grained control over behaviors such as refusal and compliance. We demonstrate this method using refusal steering emotion steering as use cases. Additionally, we propose Adaptive Angular Steering, a selective variant that rotates only activations aligned with the target feature, further enhancing stability and coherence. Angular Steering generalizes existing addition and orthogonalization techniques under a unified geometric rotation framework, simplifying parameter selection and maintaining model stability across a broader range of adjustments. Experiments across multiple model families and sizes show that Angular Steering achieves robust behavioral control while maintaining general language modeling performance, underscoring its flexibility, generalization, and robustness compared to prior approaches. Code and artifacts are available at https://github.com/lone17/angular-steering/.
Activation Steering with a Feedback Controller
Oct 05, 2025



Controlling the behaviors of large language models (LLM) is fundamental to their safety alignment and reliable deployment. However, existing steering methods are primarily driven by empirical insights and lack theoretical performance guarantees. In this work, we develop a control-theoretic foundation for activation steering by showing that popular steering methods correspond to the proportional (P) controllers, with the steering vector serving as the feedback signal. Building on this finding, we propose Proportional-Integral-Derivative (PID) Steering, a principled framework that leverages the full PID controller for activation steering in LLMs. The proportional (P) term aligns activations with target semantic directions, the integral (I) term accumulates errors to enforce persistent corrections across layers, and the derivative (D) term mitigates overshoot by counteracting rapid activation changes. This closed-loop design yields interpretable error dynamics and connects activation steering to classical stability guarantees in control theory. Moreover, PID Steering is lightweight, modular, and readily integrates with state-of-the-art steering methods. Extensive experiments across multiple LLM families and benchmarks demonstrate that PID Steering consistently outperforms existing approaches, achieving more robust and reliable behavioral control.
Inferring Properties of Graph Neural Networks
Jan 08, 2024



We propose GNNInfer, the first automatic property inference technique for GNNs. To tackle the challenge of varying input structures in GNNs, GNNInfer first identifies a set of representative influential structures that contribute significantly towards the prediction of a GNN. Using these structures, GNNInfer converts each pair of an influential structure and the GNN to their equivalent FNN and then leverages existing property inference techniques to effectively capture properties of the GNN that are specific to the influential structures. GNNINfer then generalizes the captured properties to any input graphs that contain the influential structures. Finally, GNNInfer improves the correctness of the inferred properties by building a model (either a decision tree or linear regression) that estimates the deviation of GNN output from the inferred properties given full input graphs. The learned model helps GNNInfer extend the inferred properties with constraints to the input and output of the GNN, obtaining stronger properties that hold on full input graphs. Our experiments show that GNNInfer is effective in inferring likely properties of popular real-world GNNs, and more importantly, these inferred properties help effectively defend against GNNs' backdoor attacks. In particular, out of the 13 ground truth properties, GNNInfer re-discovered 8 correct properties and discovered likely correct properties that approximate the remaining 5 ground truth properties. Using properties inferred by GNNInfer to defend against the state-of-the-art backdoor attack technique on GNNs, namely UGBA, experiments show that GNNInfer's defense success rate is up to 30 times better than existing baselines.
Improving Document Image Understanding with Reinforcement Finetuning
Sep 26, 2022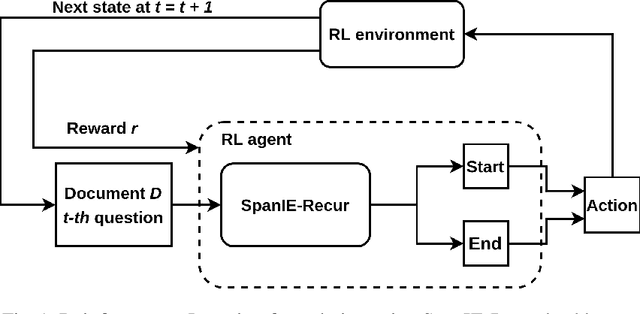
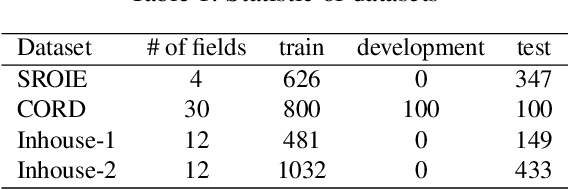
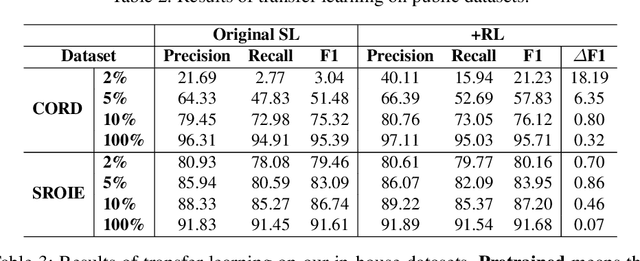
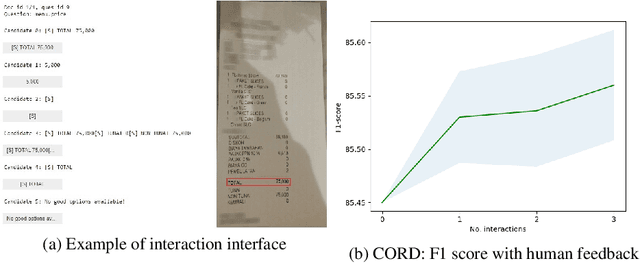
Successful Artificial Intelligence systems often require numerous labeled data to extract information from document images. In this paper, we investigate the problem of improving the performance of Artificial Intelligence systems in understanding document images, especially in cases where training data is limited. We address the problem by proposing a novel finetuning method using reinforcement learning. Our approach treats the Information Extraction model as a policy network and uses policy gradient training to update the model to maximize combined reward functions that complement the traditional cross-entropy losses. Our experiments on four datasets using labels and expert feedback demonstrate that our finetuning mechanism consistently improves the performance of a state-of-the-art information extractor, especially in the small training data regime.
Jointly Learning Span Extraction and Sequence Labeling for Information Extraction from Business Documents
May 26, 2022
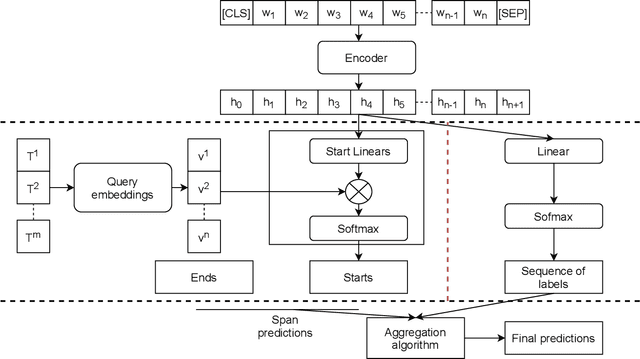
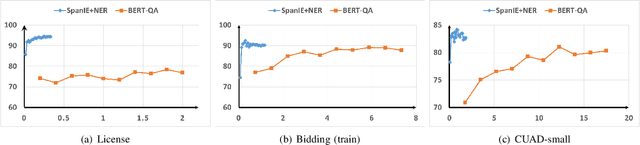
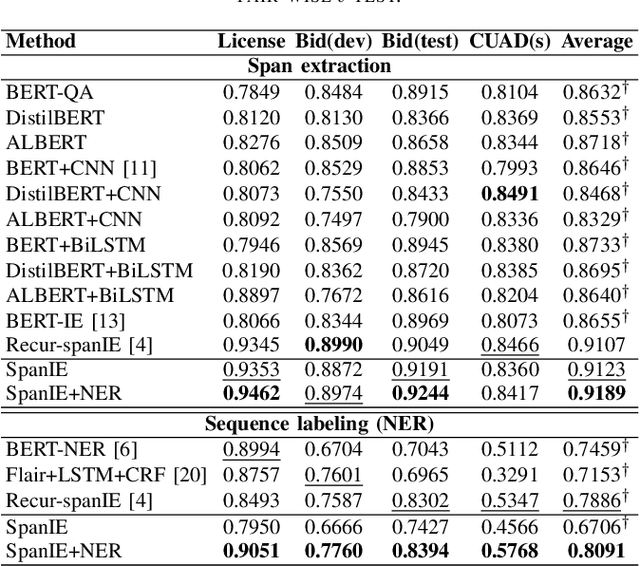
This paper introduces a new information extraction model for business documents. Different from prior studies which only base on span extraction or sequence labeling, the model takes into account advantage of both span extraction and sequence labeling. The combination allows the model to deal with long documents with sparse information (the small amount of extracted information). The model is trained end-to-end to jointly optimize the two tasks in a unified manner. Experimental results on four business datasets in English and Japanese show that the model achieves promising results and is significantly faster than the normal span-based extraction method. The code is also available.
A Span Extraction Approach for Information Extraction on Visually-Rich Documents
Jun 02, 2021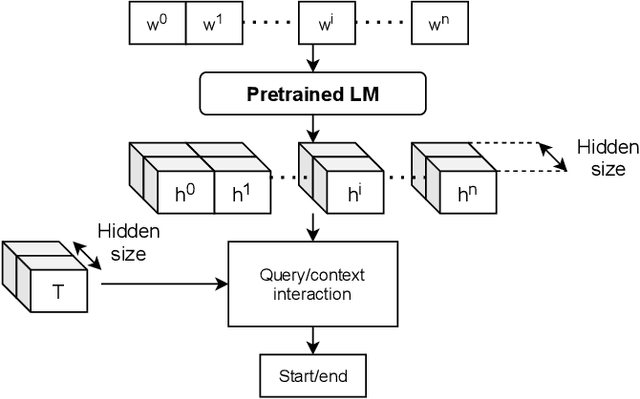

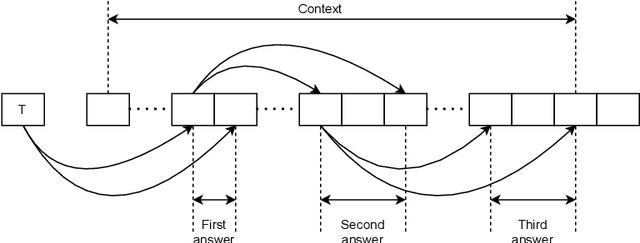

Information extraction (IE) from visually-rich documents (VRDs) has achieved SOTA performance recently thanks to the adaptation of Transformer-based language models, which demonstrates great potential of pre-training methods. In this paper, we present a new approach to improve the capability of language model pre-training on VRDs. Firstly, we introduce a new IE model that is query-based and employs the span extraction formulation instead of the commonly used sequence labelling approach. Secondly, to further extend the span extraction formulation, we propose a new training task which focuses on modelling the relationships between semantic entities within a document. This task enables the spans to be extracted recursively and can be used as both a pre-training objective as well as an IE downstream task. Evaluation on various datasets of popular business documents (invoices, receipts) shows that our proposed method can improve the performance of existing models significantly, while providing a mechanism to accumulate model knowledge from multiple downstream IE tasks.
Revising FUNSD dataset for key-value detection in document images
Oct 11, 2020
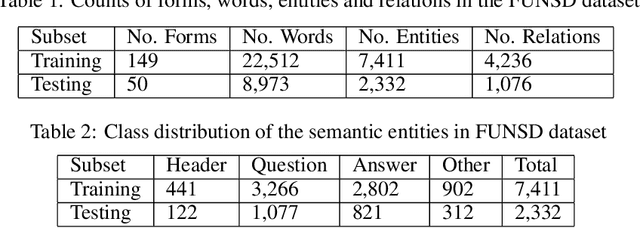
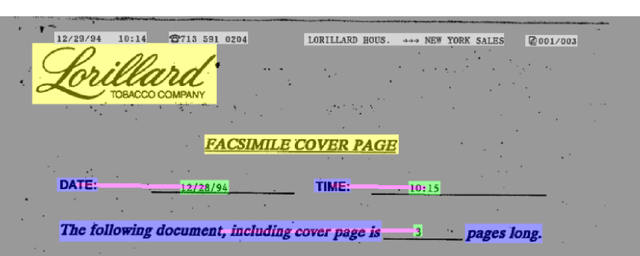

FUNSD is one of the limited publicly available datasets for information extraction from document im-ages. The information in the FUNSD dataset is defined by text areas of four categories ("key", "value", "header", "other", and "background") and connectivity between areas as key-value relations. In-specting FUNSD, we found several inconsistency in labeling, which impeded its applicability to thekey-value extraction problem. In this report, we described some labeling issues in FUNSD and therevision we made to the dataset. We also reported our implementation of for key-value detection onFUNSD using a UNet model as baseline results and an improved UNet model with Channel-InvariantDeformable Convolution.