Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevising FUNSD dataset for key-value detection in document images
Paper and Code

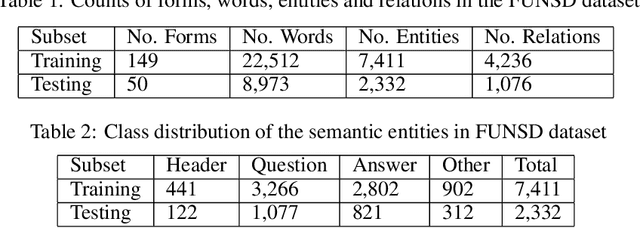
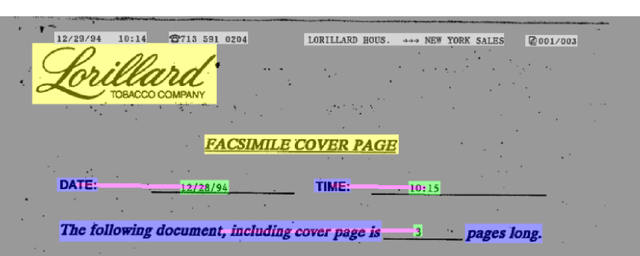

FUNSD is one of the limited publicly available datasets for information extraction from document im-ages. The information in the FUNSD dataset is defined by text areas of four categories ("key", "value", "header", "other", and "background") and connectivity between areas as key-value relations. In-specting FUNSD, we found several inconsistency in labeling, which impeded its applicability to thekey-value extraction problem. In this report, we described some labeling issues in FUNSD and therevision we made to the dataset. We also reported our implementation of for key-value detection onFUNSD using a UNet model as baseline results and an improved UNet model with Channel-InvariantDeformable Convolution.
View paper on