 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Questions by Enhancing Text Generation with Sentence Selection
Dec 23, 2022
We introduce an approach for the answer-aware question generation problem. Instead of only relying on the capability of strong pre-trained language models, we observe that the information of answers and questions can be found in some relevant sentences in the context. Based on that, we design a model which includes two modules: a selector and a generator. The selector forces the model to more focus on relevant sentences regarding an answer to provide implicit local information. The generator generates questions by implicitly combining local information from the selector and global information from the whole context encoded by the encoder. The model is trained jointly to take advantage of latent interactions between the two modules. Experimental results on two benchmark datasets show that our model is better than strong pre-trained models for the question generation task. The code is also available (shorturl.at/lV567).
Jointly Learning Span Extraction and Sequence Labeling for Information Extraction from Business Documents
May 26, 2022
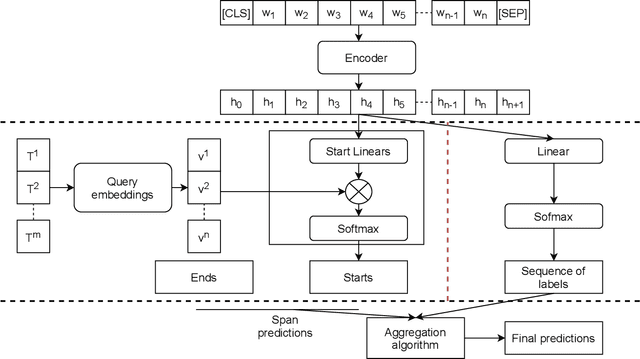
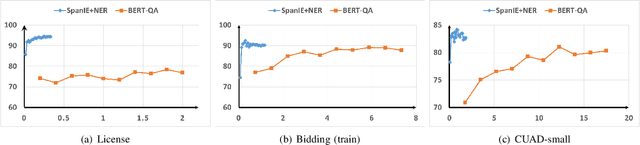
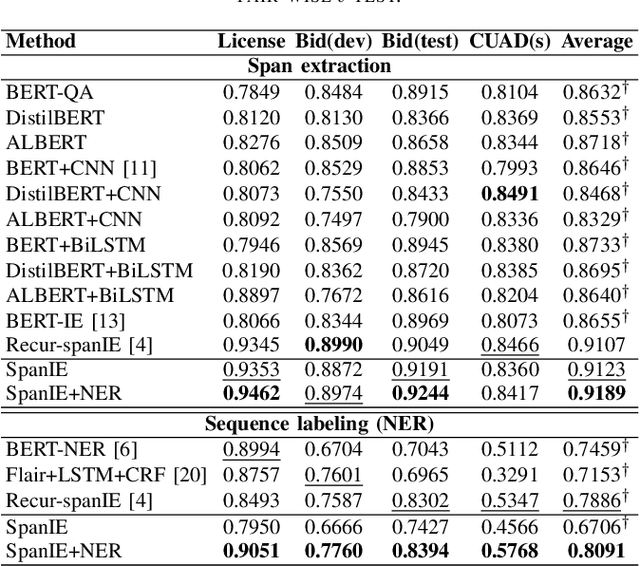
This paper introduces a new information extraction model for business documents. Different from prior studies which only base on span extraction or sequence labeling, the model takes into account advantage of both span extraction and sequence labeling. The combination allows the model to deal with long documents with sparse information (the small amount of extracted information). The model is trained end-to-end to jointly optimize the two tasks in a unified manner. Experimental results on four business datasets in English and Japanese show that the model achieves promising results and is significantly faster than the normal span-based extraction method. The code is also available.
Enhance Incomplete Utterance Restoration by Joint Learning Token Extraction and Text Generation
Apr 08, 2022
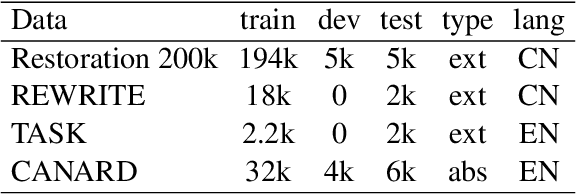
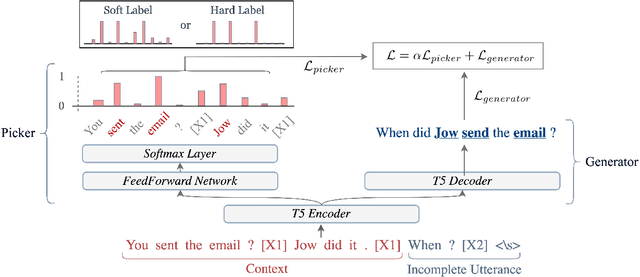
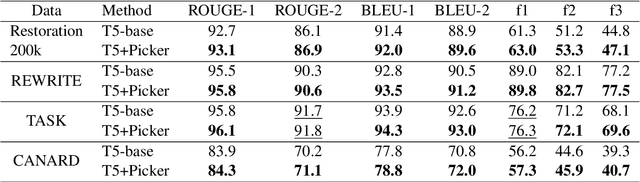
This paper introduces a model for incomplete utterance restoration (IUR). Different from prior studies that only work on extraction or abstraction datasets, we design a simple but effective model, working for both scenarios of IUR. Our design simulates the nature of IUR, where omitted tokens from the context contribute to restoration. From this, we construct a Picker that identifies the omitted tokens. To support the picker, we design two label creation methods (soft and hard labels), which can work in cases of no annotation of the omitted tokens. The restoration is done by using a Generator with the help of the Picker on joint learning. Promising results on four benchmark datasets in extraction and abstraction scenarios show that our model is better than the pretrained T5 and non-generative language model methods in both rich and limited training data settings. The code will be also available.
A Span Extraction Approach for Information Extraction on Visually-Rich Documents
Jun 02, 2021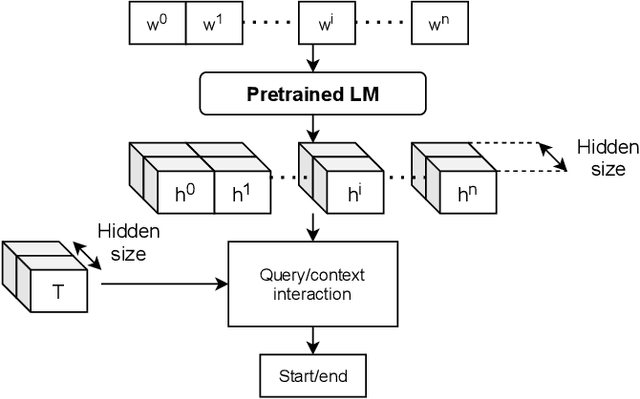

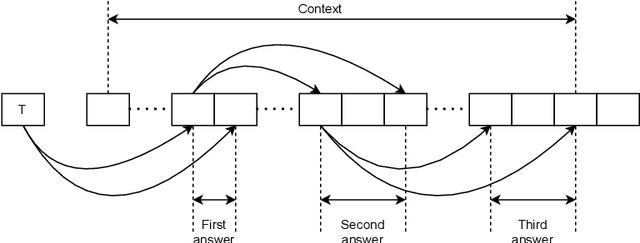

Information extraction (IE) from visually-rich documents (VRDs) has achieved SOTA performance recently thanks to the adaptation of Transformer-based language models, which demonstrates great potential of pre-training methods. In this paper, we present a new approach to improve the capability of language model pre-training on VRDs. Firstly, we introduce a new IE model that is query-based and employs the span extraction formulation instead of the commonly used sequence labelling approach. Secondly, to further extend the span extraction formulation, we propose a new training task which focuses on modelling the relationships between semantic entities within a document. This task enables the spans to be extracted recursively and can be used as both a pre-training objective as well as an IE downstream task. Evaluation on various datasets of popular business documents (invoices, receipts) shows that our proposed method can improve the performance of existing models significantly, while providing a mechanism to accumulate model knowledge from multiple downstream IE tasks.
Transfer Learning for Information Extraction with Limited Data
Mar 06, 2020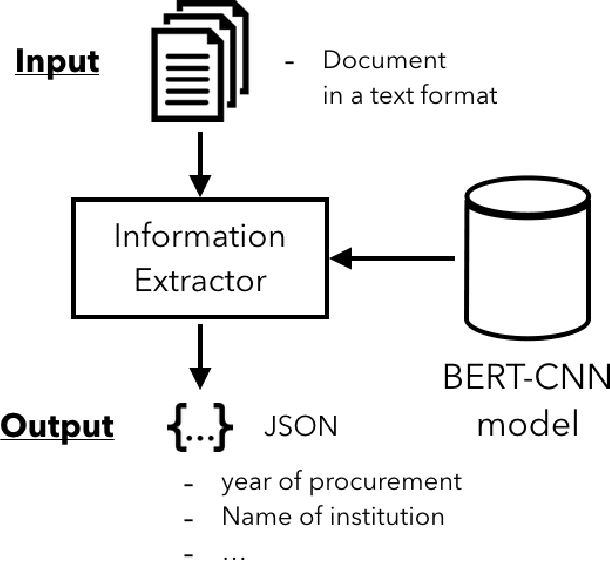

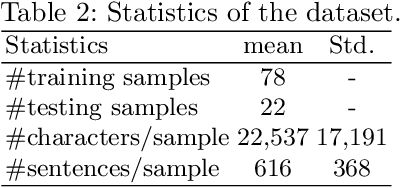
This paper presents a practical approach to fine-grained information extraction. Through plenty of experiences of authors in practically applying information extraction to business process automation, there can be found a couple of fundamental technical challenges: (i) the availability of labeled data is usually limited and (ii) highly detailed classification is required. The main idea of our proposal is to leverage the concept of transfer learning, which is to reuse the pre-trained model of deep neural networks, with a combination of common statistical classifiers to determine the class of each extracted term. To do that, we first exploit BERT to deal with the limitation of training data in real scenarios, then stack BERT with Convolutional Neural Networks to learn hidden representation for classification. To validate our approach, we applied our model to an actual case of document processing, which is a process of competitive bids for government projects in Japan. We used 100 documents for training and testing and confirmed that the model enables to extract fine-grained named entities with a detailed level of information preciseness specialized in the targeted business process, such as a department name of application receivers.