 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Prompt Selection for Large Language Models
Apr 03, 2024



Large Language Models (LLMs) can perform various natural language processing tasks with suitable instruction prompts. However, designing effective prompts manually is challenging and time-consuming. Existing methods for automatic prompt optimization either lack flexibility or efficiency. In this paper, we propose an effective approach to automatically select the optimal prompt for a given input from a finite set of synthetic candidate prompts. Our approach consists of three steps: (1) clustering the training data and generating candidate prompts for each cluster using an LLM-based prompt generator; (2) synthesizing a dataset of input-prompt-output tuples for training a prompt evaluator to rank the prompts based on their relevance to the input; (3) using the prompt evaluator to select the best prompt for a new input at test time. Our approach balances prompt generality-specificity and eliminates the need for resource-intensive training and inference. It demonstrates competitive performance on zero-shot question-answering datasets: GSM8K, MultiArith, and AQuA.
When Giant Language Brains Just Aren't Enough! Domain Pizzazz with Knowledge Sparkle Dust
May 12, 2023Large language models (LLMs) have significantly advanced the field of natural language processing, with GPT models at the forefront. While their remarkable performance spans a range of tasks, adapting LLMs for real-world business scenarios still poses challenges warranting further investigation. This paper presents an empirical analysis aimed at bridging the gap in adapting LLMs to practical use cases. To do that, we select the question answering (QA) task of insurance as a case study due to its challenge of reasoning. Based on the task we design a new model relied on LLMs which are empowered by domain-specific knowledge extracted from insurance policy rulebooks. The domain-specific knowledge helps LLMs to understand new concepts of insurance for domain adaptation. Preliminary results on real QA pairs show that knowledge enhancement from policy rulebooks significantly improves the reasoning ability of GPT-3.5 of 50.4% in terms of accuracy. The analysis also indicates that existing public knowledge bases, e.g., DBPedia is beneficial for knowledge enhancement. Our findings reveal that the inherent complexity of business scenarios often necessitates the incorporation of domain-specific knowledge and external resources for effective problem-solving.
Transfer Learning for Information Extraction with Limited Data
Mar 06, 2020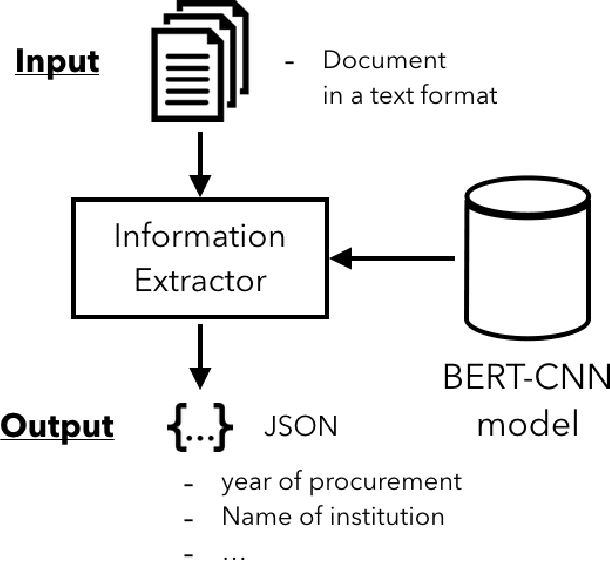
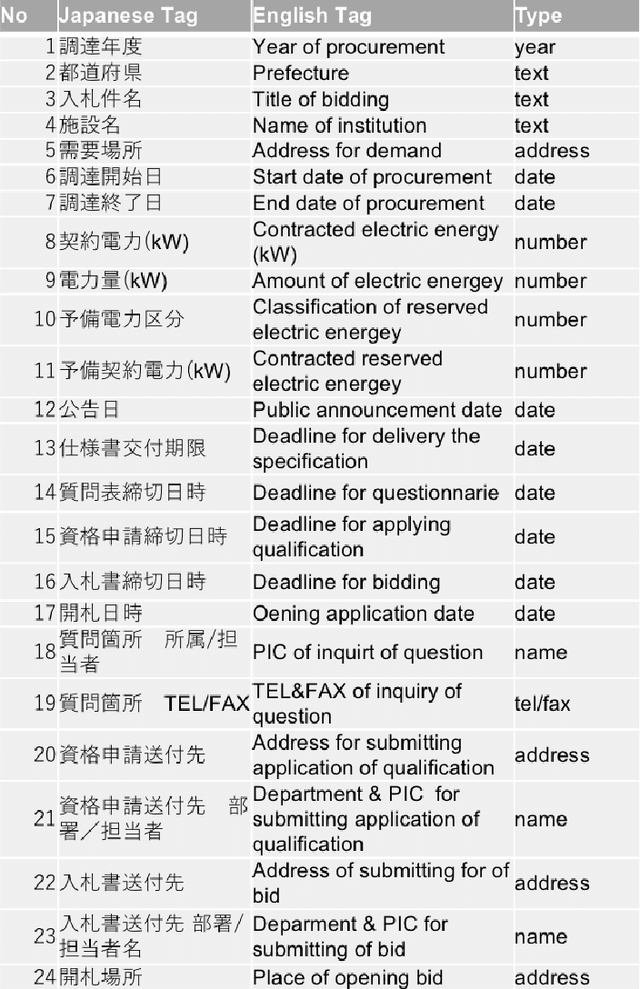

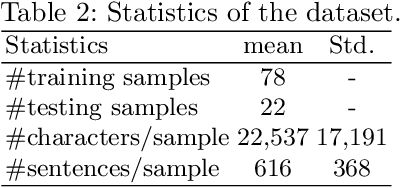
This paper presents a practical approach to fine-grained information extraction. Through plenty of experiences of authors in practically applying information extraction to business process automation, there can be found a couple of fundamental technical challenges: (i) the availability of labeled data is usually limited and (ii) highly detailed classification is required. The main idea of our proposal is to leverage the concept of transfer learning, which is to reuse the pre-trained model of deep neural networks, with a combination of common statistical classifiers to determine the class of each extracted term. To do that, we first exploit BERT to deal with the limitation of training data in real scenarios, then stack BERT with Convolutional Neural Networks to learn hidden representation for classification. To validate our approach, we applied our model to an actual case of document processing, which is a process of competitive bids for government projects in Japan. We used 100 documents for training and testing and confirmed that the model enables to extract fine-grained named entities with a detailed level of information preciseness specialized in the targeted business process, such as a department name of application receivers.