 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Prompt Selection for Large Language Models
Apr 03, 2024



Large Language Models (LLMs) can perform various natural language processing tasks with suitable instruction prompts. However, designing effective prompts manually is challenging and time-consuming. Existing methods for automatic prompt optimization either lack flexibility or efficiency. In this paper, we propose an effective approach to automatically select the optimal prompt for a given input from a finite set of synthetic candidate prompts. Our approach consists of three steps: (1) clustering the training data and generating candidate prompts for each cluster using an LLM-based prompt generator; (2) synthesizing a dataset of input-prompt-output tuples for training a prompt evaluator to rank the prompts based on their relevance to the input; (3) using the prompt evaluator to select the best prompt for a new input at test time. Our approach balances prompt generality-specificity and eliminates the need for resource-intensive training and inference. It demonstrates competitive performance on zero-shot question-answering datasets: GSM8K, MultiArith, and AQuA.
VLSP 2023 -- LTER: A Summary of the Challenge on Legal Textual Entailment Recognition
Mar 06, 2024
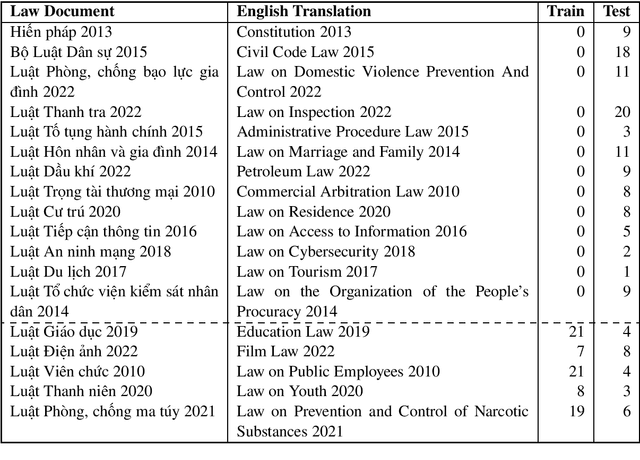


In this new era of rapid AI development, especially in language processing, the demand for AI in the legal domain is increasingly critical. In the context where research in other languages such as English, Japanese, and Chinese has been well-established, we introduce the first fundamental research for the Vietnamese language in the legal domain: legal textual entailment recognition through the Vietnamese Language and Speech Processing workshop. In analyzing participants' results, we discuss certain linguistic aspects critical in the legal domain that pose challenges that need to be addressed.
Towards Safer Operations: An Expert-involved Dataset of High-Pressure Gas Incidents for Preventing Future Failures
Oct 23, 2023This paper introduces a new IncidentAI dataset for safety prevention. Different from prior corpora that usually contain a single task, our dataset comprises three tasks: named entity recognition, cause-effect extraction, and information retrieval. The dataset is annotated by domain experts who have at least six years of practical experience as high-pressure gas conservation managers. We validate the contribution of the dataset in the scenario of safety prevention. Preliminary results on the three tasks show that NLP techniques are beneficial for analyzing incident reports to prevent future failures. The dataset facilitates future research in NLP and incident management communities. The access to the dataset is also provided (the IncidentAI dataset is available at: https://github.com/Cinnamon/incident-ai-dataset).
When Giant Language Brains Just Aren't Enough! Domain Pizzazz with Knowledge Sparkle Dust
May 12, 2023Large language models (LLMs) have significantly advanced the field of natural language processing, with GPT models at the forefront. While their remarkable performance spans a range of tasks, adapting LLMs for real-world business scenarios still poses challenges warranting further investigation. This paper presents an empirical analysis aimed at bridging the gap in adapting LLMs to practical use cases. To do that, we select the question answering (QA) task of insurance as a case study due to its challenge of reasoning. Based on the task we design a new model relied on LLMs which are empowered by domain-specific knowledge extracted from insurance policy rulebooks. The domain-specific knowledge helps LLMs to understand new concepts of insurance for domain adaptation. Preliminary results on real QA pairs show that knowledge enhancement from policy rulebooks significantly improves the reasoning ability of GPT-3.5 of 50.4% in terms of accuracy. The analysis also indicates that existing public knowledge bases, e.g., DBPedia is beneficial for knowledge enhancement. Our findings reveal that the inherent complexity of business scenarios often necessitates the incorporation of domain-specific knowledge and external resources for effective problem-solving.
Emotion-Cause Pair Extraction as Question Answering
Jan 06, 2023The task of Emotion-Cause Pair Extraction (ECPE) aims to extract all potential emotion-cause pairs of a document without any annotation of emotion or cause clauses. Previous approaches on ECPE have tried to improve conventional two-step processing schemes by using complex architectures for modeling emotion-cause interaction. In this paper, we cast the ECPE task to the question answering (QA) problem and propose simple yet effective BERT-based solutions to tackle it. Given a document, our Guided-QA model first predicts the best emotion clause using a fixed question. Then the predicted emotion is used as a question to predict the most potential cause for the emotion. We evaluate our model on a standard ECPE corpus. The experimental results show that despite its simplicity, our Guided-QA achieves promising results and is easy to reproduce. The code of Guided-QA is also provided.
Learning to Generate Questions by Enhancing Text Generation with Sentence Selection
Dec 23, 2022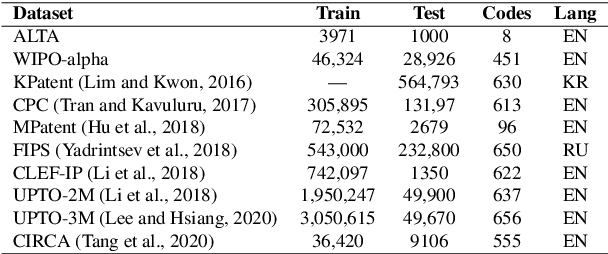
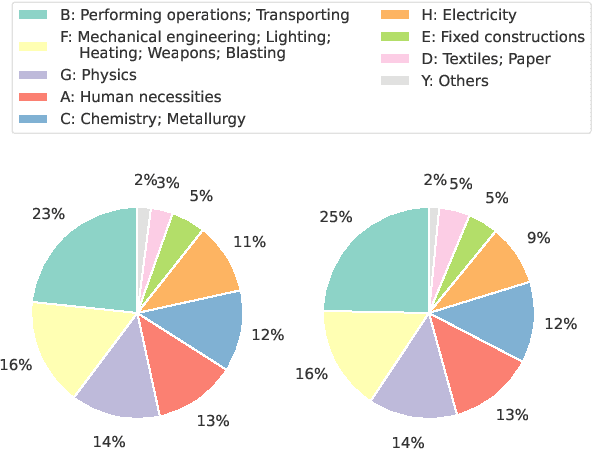
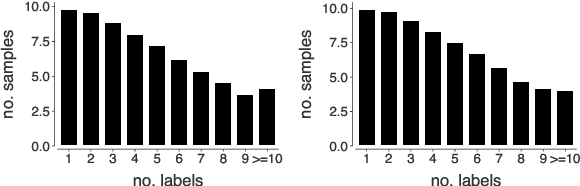
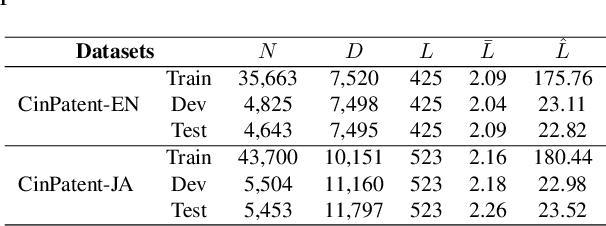
We introduce an approach for the answer-aware question generation problem. Instead of only relying on the capability of strong pre-trained language models, we observe that the information of answers and questions can be found in some relevant sentences in the context. Based on that, we design a model which includes two modules: a selector and a generator. The selector forces the model to more focus on relevant sentences regarding an answer to provide implicit local information. The generator generates questions by implicitly combining local information from the selector and global information from the whole context encoded by the encoder. The model is trained jointly to take advantage of latent interactions between the two modules. Experimental results on two benchmark datasets show that our model is better than strong pre-trained models for the question generation task. The code is also available (shorturl.at/lV567).
Meeting Decision Tracker: Making Meeting Minutes with De-Contextualized Utterances
Oct 20, 2022
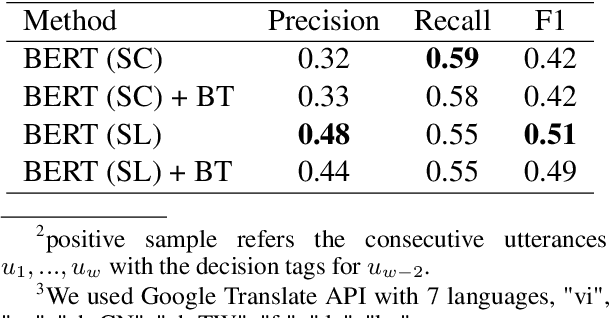

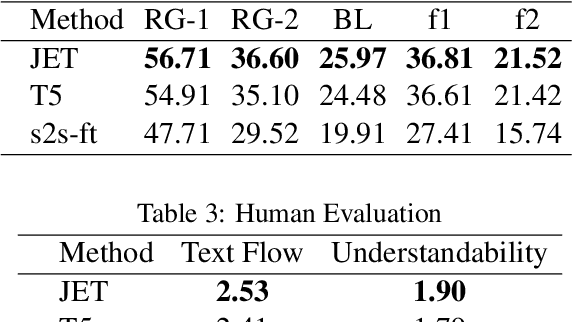
Meetings are a universal process to make decisions in business and project collaboration. The capability to automatically itemize the decisions in daily meetings allows for extensive tracking of past discussions. To that end, we developed Meeting Decision Tracker, a prototype system to construct decision items comprising decision utterance detector (DUD) and decision utterance rewriter (DUR). We show that DUR makes a sizable contribution to improving the user experience by dealing with utterance collapse in natural conversation. An introduction video of our system is also available at https://youtu.be/TG1pJJo0Iqo.
Improving Document Image Understanding with Reinforcement Finetuning
Sep 26, 2022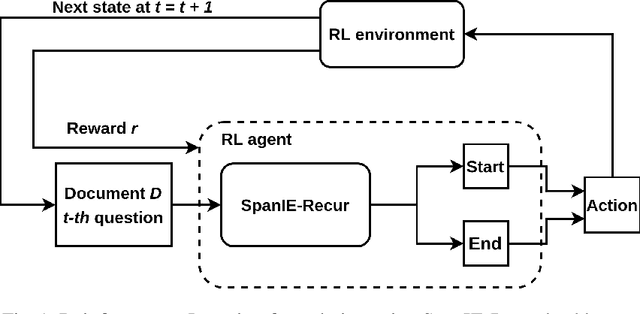
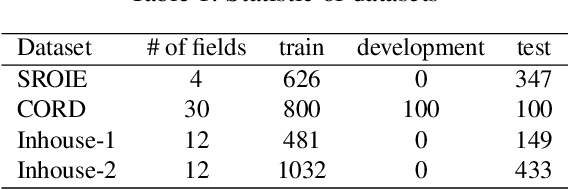
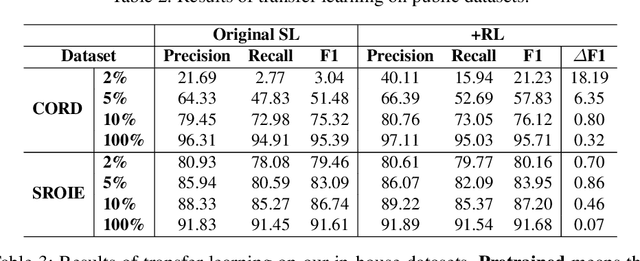
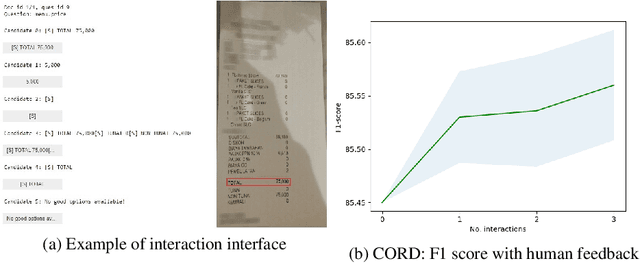
Successful Artificial Intelligence systems often require numerous labeled data to extract information from document images. In this paper, we investigate the problem of improving the performance of Artificial Intelligence systems in understanding document images, especially in cases where training data is limited. We address the problem by proposing a novel finetuning method using reinforcement learning. Our approach treats the Information Extraction model as a policy network and uses policy gradient training to update the model to maximize combined reward functions that complement the traditional cross-entropy losses. Our experiments on four datasets using labels and expert feedback demonstrate that our finetuning mechanism consistently improves the performance of a state-of-the-art information extractor, especially in the small training data regime.
Jointly Learning Span Extraction and Sequence Labeling for Information Extraction from Business Documents
May 26, 2022
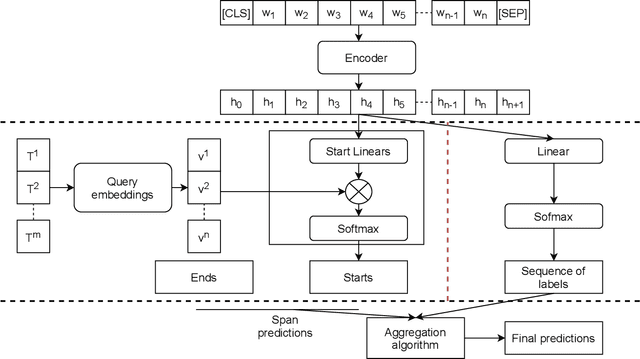
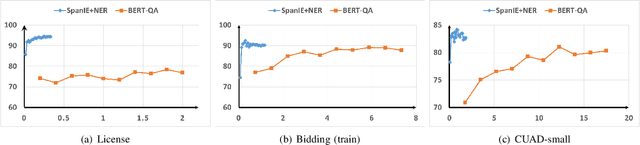
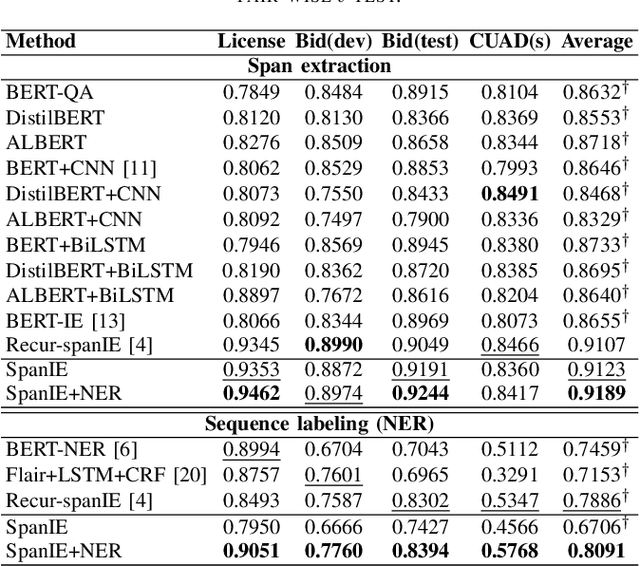
This paper introduces a new information extraction model for business documents. Different from prior studies which only base on span extraction or sequence labeling, the model takes into account advantage of both span extraction and sequence labeling. The combination allows the model to deal with long documents with sparse information (the small amount of extracted information). The model is trained end-to-end to jointly optimize the two tasks in a unified manner. Experimental results on four business datasets in English and Japanese show that the model achieves promising results and is significantly faster than the normal span-based extraction method. The code is also available.
Make The Most of Prior Data: A Solution for Interactive Text Summarization with Preference Feedback
Apr 12, 2022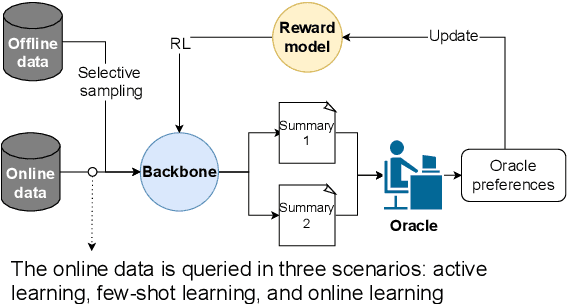

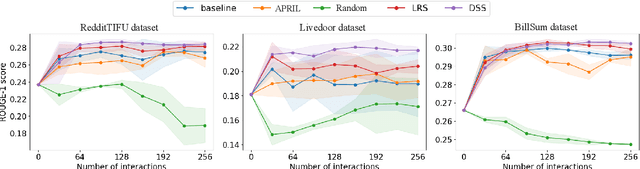

For summarization, human preference is critical to tame outputs of the summarizer in favor of human interests, as ground-truth summaries are scarce and ambiguous. Practical settings require dynamic exchanges between human and AI agent wherein feedback is provided in an online manner, a few at a time. In this paper, we introduce a new framework to train summarization models with preference feedback interactively. By properly leveraging offline data and a novel reward model, we improve the performance regarding ROUGE scores and sample-efficiency. Our experiments on three various datasets confirm the benefit of the proposed framework in active, few-shot and online settings of preference learning.