 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safer Operations: An Expert-involved Dataset of High-Pressure Gas Incidents for Preventing Future Failures
Oct 23, 2023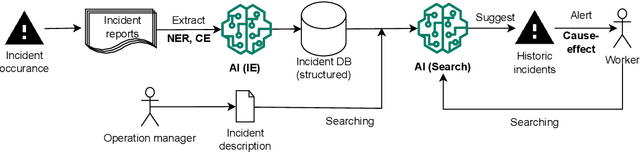

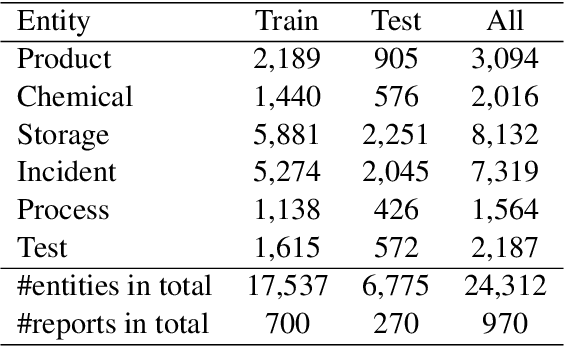

This paper introduces a new IncidentAI dataset for safety prevention. Different from prior corpora that usually contain a single task, our dataset comprises three tasks: named entity recognition, cause-effect extraction, and information retrieval. The dataset is annotated by domain experts who have at least six years of practical experience as high-pressure gas conservation managers. We validate the contribution of the dataset in the scenario of safety prevention. Preliminary results on the three tasks show that NLP techniques are beneficial for analyzing incident reports to prevent future failures. The dataset facilitates future research in NLP and incident management communities. The access to the dataset is also provided (the IncidentAI dataset is available at: https://github.com/Cinnamon/incident-ai-dataset).
Improving Document Image Understanding with Reinforcement Finetuning
Sep 26, 2022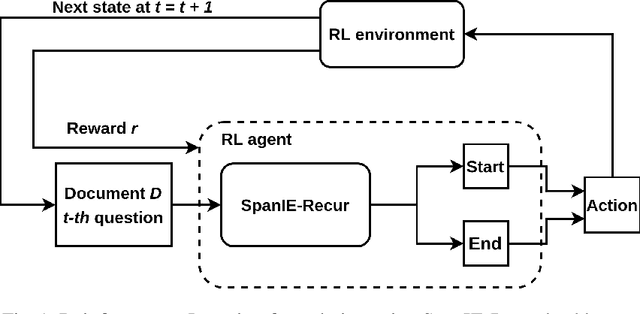
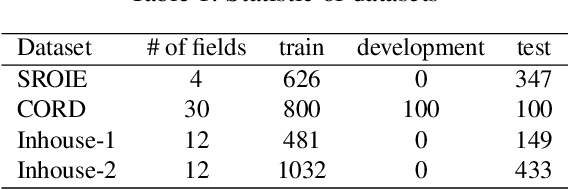
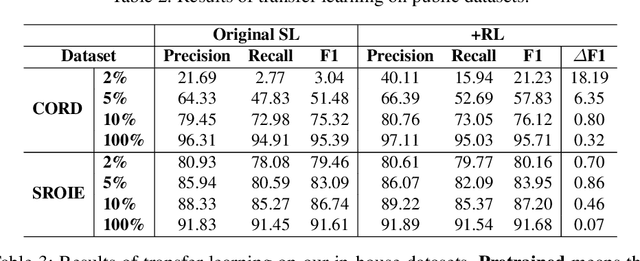
Successful Artificial Intelligence systems often require numerous labeled data to extract information from document images. In this paper, we investigate the problem of improving the performance of Artificial Intelligence systems in understanding document images, especially in cases where training data is limited. We address the problem by proposing a novel finetuning method using reinforcement learning. Our approach treats the Information Extraction model as a policy network and uses policy gradient training to update the model to maximize combined reward functions that complement the traditional cross-entropy losses. Our experiments on four datasets using labels and expert feedback demonstrate that our finetuning mechanism consistently improves the performance of a state-of-the-art information extractor, especially in the small training data regime.
Make The Most of Prior Data: A Solution for Interactive Text Summarization with Preference Feedback
Apr 12, 2022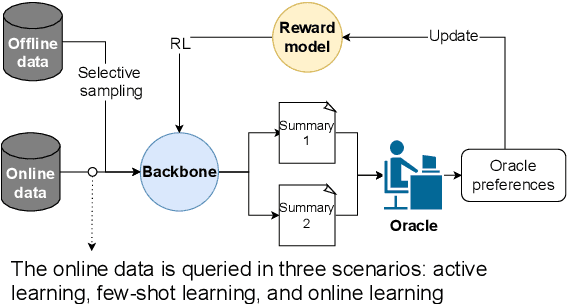

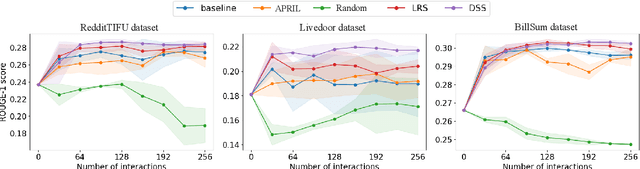

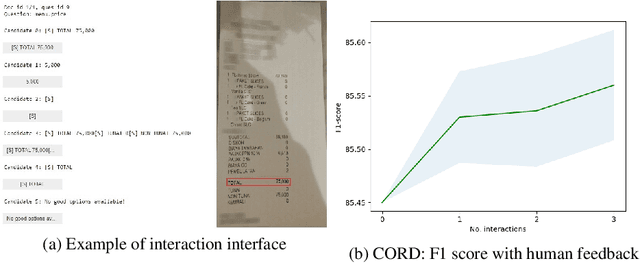
For summarization, human preference is critical to tame outputs of the summarizer in favor of human interests, as ground-truth summaries are scarce and ambiguous. Practical settings require dynamic exchanges between human and AI agent wherein feedback is provided in an online manner, a few at a time. In this paper, we introduce a new framework to train summarization models with preference feedback interactively. By properly leveraging offline data and a novel reward model, we improve the performance regarding ROUGE scores and sample-efficiency. Our experiments on three various datasets confirm the benefit of the proposed framework in active, few-shot and online settings of preference learning.
Robust Deep Reinforcement Learning for Extractive Legal Summarization
Nov 23, 2021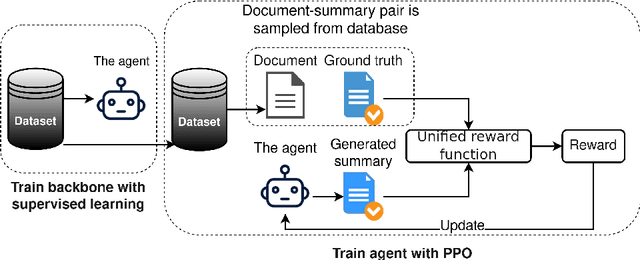
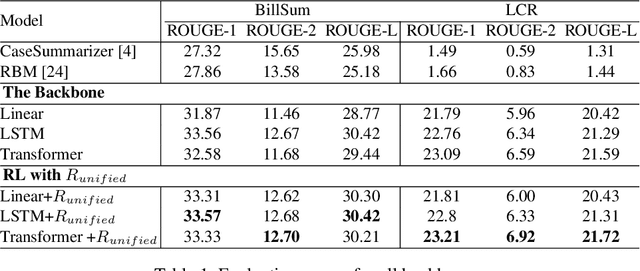
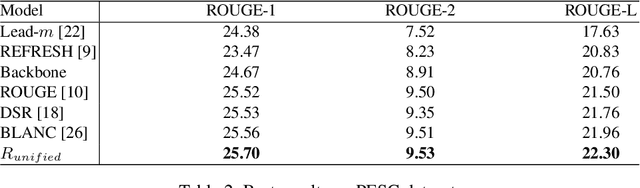

Automatic summarization of legal texts is an important and still a challenging task since legal documents are often long and complicated with unusual structures and styles. Recent advances of deep models trained end-to-end with differentiable losses can well-summarize natural text, yet when applied to legal domain, they show limited results. In this paper, we propose to use reinforcement learning to train current deep summarization models to improve their performance on the legal domain. To this end, we adopt proximal policy optimization methods and introduce novel reward functions that encourage the generation of candidate summaries satisfying both lexical and semantic criteria. We apply our method to training different summarization backbones and observe a consistent and significant performance gain across 3 public legal datasets.
Sentence Compression as Deletion with Contextual Embeddings
Jun 05, 2020


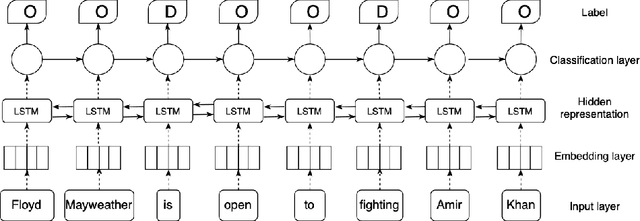
Sentence compression is the task of creating a shorter version of an input sentence while keeping important information. In this paper, we extend the task of compression by deletion with the use of contextual embeddings. Different from prior work usually using non-contextual embeddings (Glove or Word2Vec), we exploit contextual embeddings that enable our model capturing the context of inputs. More precisely, we utilize contextual embeddings stacked by bidirectional Long-short Term Memory and Conditional Random Fields for dealing with sequence labeling. Experimental results on a benchmark Google dataset show that by utilizing contextual embeddings, our model achieves a new state-of-the-art F-score compared to strong methods reported on the leader board.