 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Compression as Deletion with Contextual Embeddings
Paper and Code
Jun 05, 2020


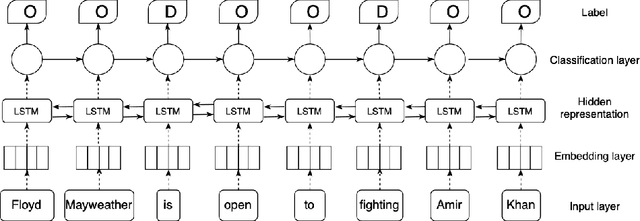
Sentence compression is the task of creating a shorter version of an input sentence while keeping important information. In this paper, we extend the task of compression by deletion with the use of contextual embeddings. Different from prior work usually using non-contextual embeddings (Glove or Word2Vec), we exploit contextual embeddings that enable our model capturing the context of inputs. More precisely, we utilize contextual embeddings stacked by bidirectional Long-short Term Memory and Conditional Random Fields for dealing with sequence labeling. Experimental results on a benchmark Google dataset show that by utilizing contextual embeddings, our model achieves a new state-of-the-art F-score compared to strong methods reported on the leader board.