 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Document Image Understanding with Reinforcement Finetuning
Paper and Code
Sep 26, 2022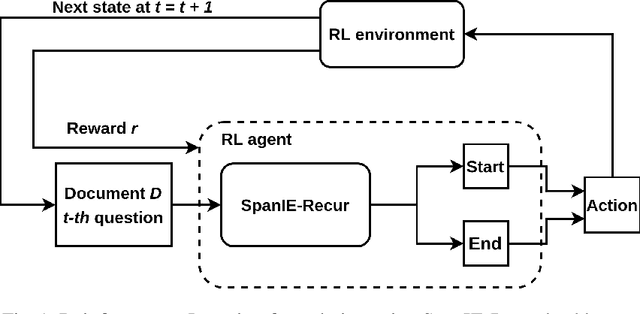
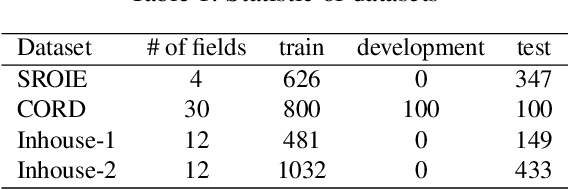
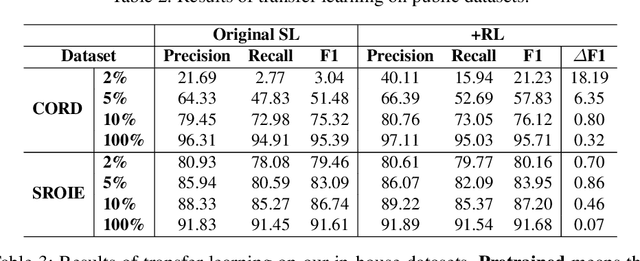
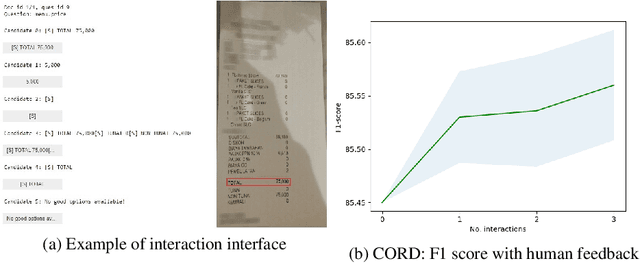
Successful Artificial Intelligence systems often require numerous labeled data to extract information from document images. In this paper, we investigate the problem of improving the performance of Artificial Intelligence systems in understanding document images, especially in cases where training data is limited. We address the problem by proposing a novel finetuning method using reinforcement learning. Our approach treats the Information Extraction model as a policy network and uses policy gradient training to update the model to maximize combined reward functions that complement the traditional cross-entropy losses. Our experiments on four datasets using labels and expert feedback demonstrate that our finetuning mechanism consistently improves the performance of a state-of-the-art information extractor, especially in the small training data regime.