 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Disentangled Representation Learning for Generalizable Authorship Attribution in the Era of Generative AI
Apr 23, 2026Learning robust representations of authorial style is crucial for authorship attribution and AI-generated text detection. However, existing methods often struggle with content-style entanglement, where models learn spurious correlations between authors' writing styles and topics, leading to poor generalization across domains. To address this challenge, we propose Explainable Authorship Variational Autoencoder (EAVAE), a novel framework that explicitly disentangles style from content through architectural separation-by-design. EAVAE first pretrains style encoders using supervised contrastive learning on diverse authorship data, then finetunes with a Variational Autoencoder (VEA) architecture using separate encoders for style and content representations. Disentanglement is enforced through a novel discriminator that not only distinguishes whether pairs of style/content representations belong to the same or different authors/content sources, but also generates natural language explanation for their decision, simultaneously mitigating confounding information and enhancing interpretability. Extensive experiments demonstrate the effectiveness of EAVAE. On authorship attribution, we achieve state-of-the-art performance on various datasets, including Amazon Reviews, PAN21, and HRS. For AI-generated text detection, EAVAE excels in few-shot learning over the M4 dataset. Code and data repositories are available online\footnote{https://github.com/hieum98/avae} \footnote{https://huggingface.co/collections/Hieuman/document-level-authorship-datasets}.
AccurateRAG: A Framework for Building Accurate Retrieval-Augmented Question-Answering Applications
Oct 02, 2025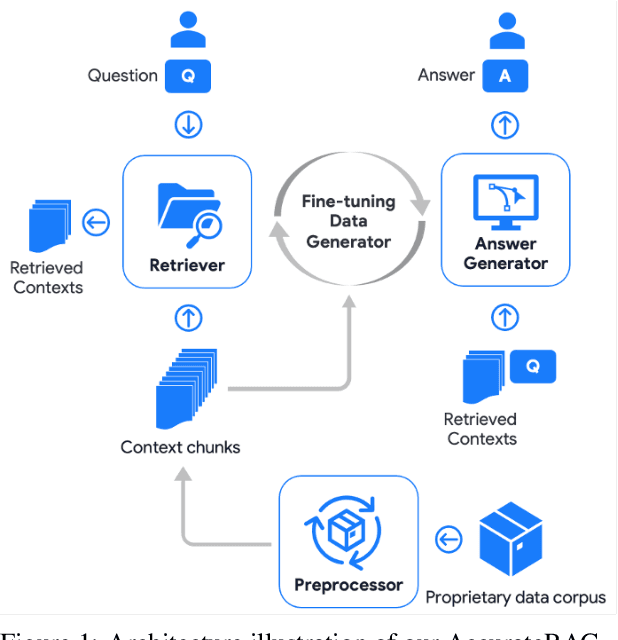

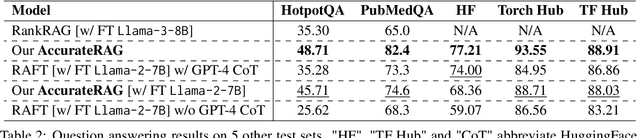
We introduce AccurateRAG -- a novel framework for constructing high-performance question-answering applications based on retrieval-augmented generation (RAG). Our framework offers a pipeline for development efficiency with tools for raw dataset processing, fine-tuning data generation, text embedding & LLM fine-tuning, output evaluation, and building RAG systems locally. Experimental results show that our framework outperforms previous strong baselines and obtains new state-of-the-art question-answering performance on benchmark datasets.
Lifelong Event Detection via Optimal Transport
Oct 11, 2024



Continual Event Detection (CED) poses a formidable challenge due to the catastrophic forgetting phenomenon, where learning new tasks (with new coming event types) hampers performance on previous ones. In this paper, we introduce a novel approach, Lifelong Event Detection via Optimal Transport (LEDOT), that leverages optimal transport principles to align the optimization of our classification module with the intrinsic nature of each class, as defined by their pre-trained language modeling. Our method integrates replay sets, prototype latent representations, and an innovative Optimal Transport component. Extensive experiments on MAVEN and ACE datasets demonstrate LEDOT's superior performance, consistently outperforming state-of-the-art baselines. The results underscore LEDOT as a pioneering solution in continual event detection, offering a more effective and nuanced approach to addressing catastrophic forgetting in evolving environments.
Householder Pseudo-Rotation: A Novel Approach to Activation Editing in LLMs with Direction-Magnitude Perspective
Sep 16, 2024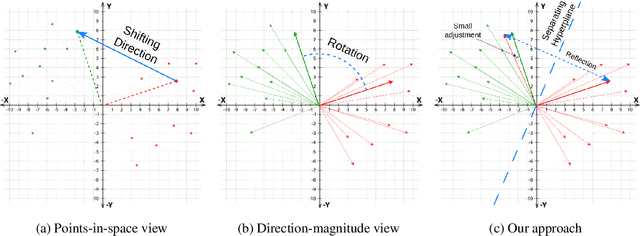
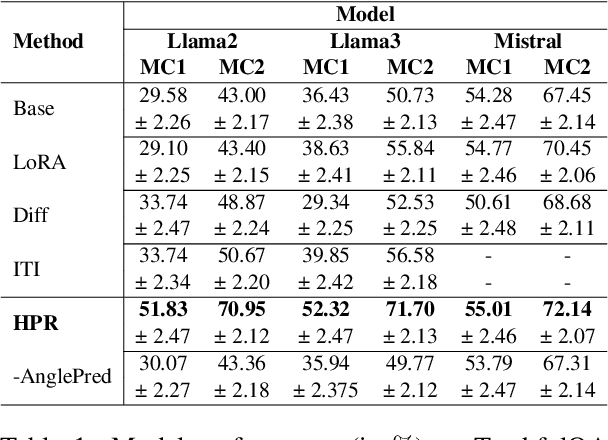
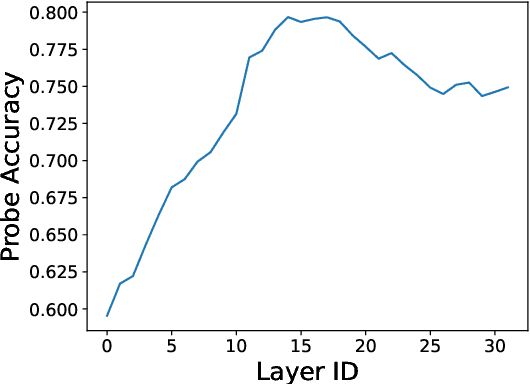
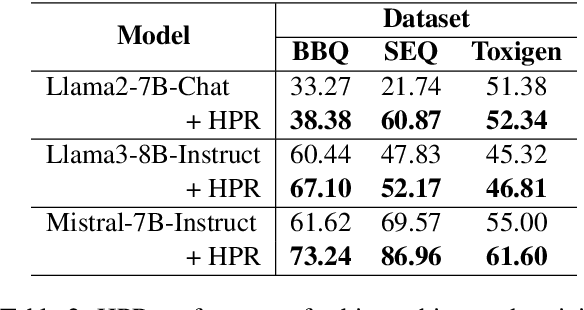
Activation Editing, which involves directly editting the internal representations of large language models (LLMs) to alter their behaviors and achieve desired properties, has emerged as a promising area of research. Existing works primarily treat LLMs' activations as points in space and modify them by adding steering vectors. However, this approach is limited in its ability to achieve greater performance improvement while maintaining the necessary consistency of activation magnitudes. To overcome these issues, we propose a novel editing method that views activations in terms of their directions and magnitudes. Our method, named Householder Pseudo-Rotation (HPR), mimics the rotation transformation, thus preserving activation norms and resulting in an improved performance on various safety benchmarks.
Transformer-Based Deep Learning Detector for Dual-Mode Index Modulation 3D-OFDM
Sep 09, 2023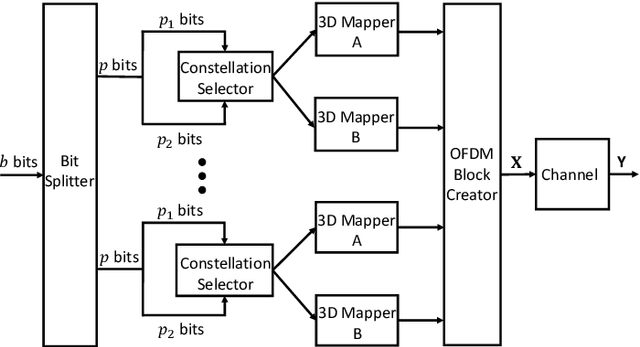
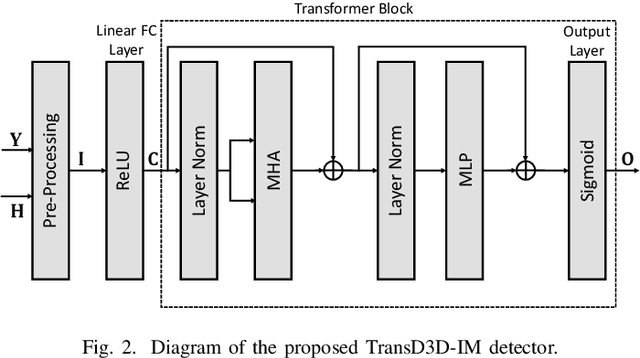
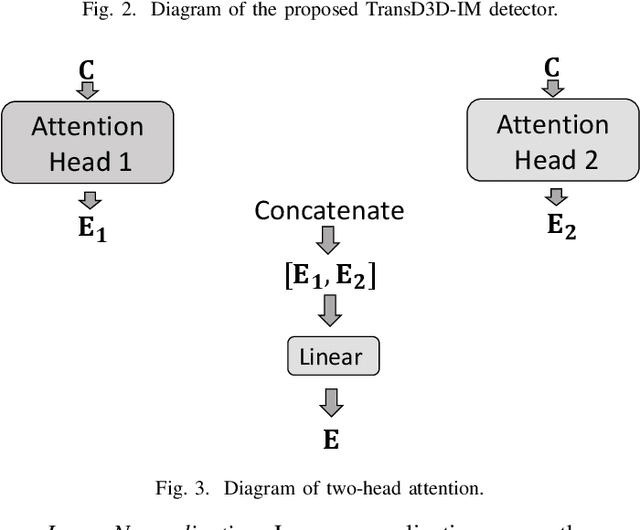
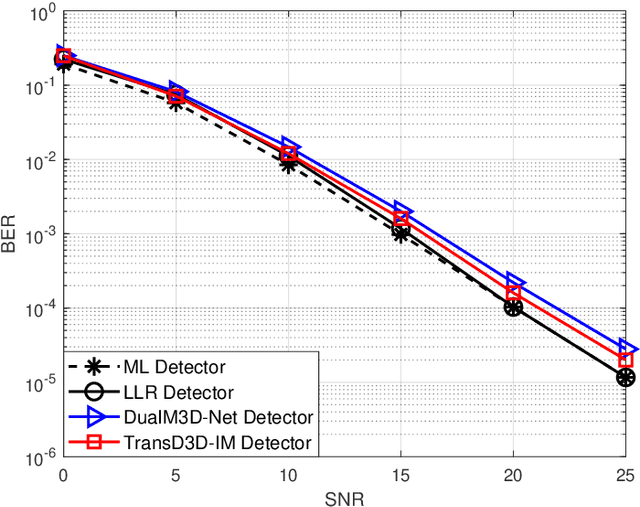
In this paper, we propose a deep learning-based signal detector called TransD3D-IM, which employs the Transformer framework for signal detection in the Dual-mode index modulation-aided three-dimensional (3D) orthogonal frequency division multiplexing (DM-IM-3D-OFDM) system. In this system, the data bits are conveyed using dual-mode 3D constellation symbols and active subcarrier indices. As a result, this method exhibits significantly higher transmission reliability than current IM-based models with traditional maximum likelihood (ML) detection. Nevertheless, the ML detector suffers from high computational complexity, particularly when the parameters of the system are large. Even the complexity of the Log-Likelihood Ratio algorithm, known as a low-complexity detector for signal detection in the DM-IM-3D-OFDM system, is also not impressive enough. To overcome this limitation, our proposal applies a deep neural network at the receiver, utilizing the Transformer framework for signal detection of DM-IM-3D-OFDM system in Rayleigh fading channel. Simulation results demonstrate that our detector attains to approach performance compared to the model-based receiver. Furthermore, TransD3D-IM exhibits more robustness than the existing deep learning-based detector while considerably reducing runtime complexity in comparison with the benchmarks.