 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHouseholder Pseudo-Rotation: A Novel Approach to Activation Editing in LLMs with Direction-Magnitude Perspective
Paper and Code
Sep 16, 2024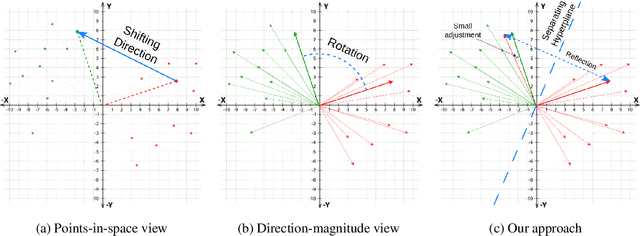
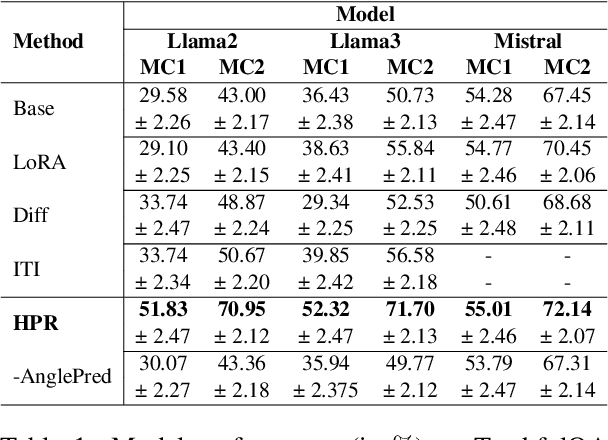
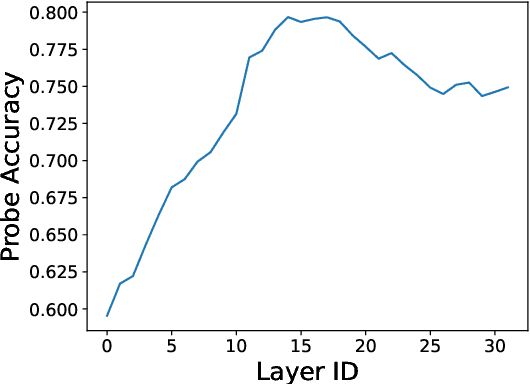
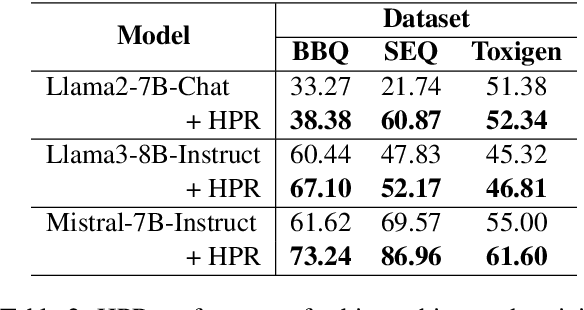
Activation Editing, which involves directly editting the internal representations of large language models (LLMs) to alter their behaviors and achieve desired properties, has emerged as a promising area of research. Existing works primarily treat LLMs' activations as points in space and modify them by adding steering vectors. However, this approach is limited in its ability to achieve greater performance improvement while maintaining the necessary consistency of activation magnitudes. To overcome these issues, we propose a novel editing method that views activations in terms of their directions and magnitudes. Our method, named Householder Pseudo-Rotation (HPR), mimics the rotation transformation, thus preserving activation norms and resulting in an improved performance on various safety benchmarks.