 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Prompting for Continual Relation Extraction: A Within-Task Variance Perspective
Dec 12, 2024



To address catastrophic forgetting in Continual Relation Extraction (CRE), many current approaches rely on memory buffers to rehearse previously learned knowledge while acquiring new tasks. Recently, prompt-based methods have emerged as potent alternatives to rehearsal-based strategies, demonstrating strong empirical performance. However, upon analyzing existing prompt-based approaches for CRE, we identified several critical limitations, such as inaccurate prompt selection, inadequate mechanisms for mitigating forgetting in shared parameters, and suboptimal handling of cross-task and within-task variances. To overcome these challenges, we draw inspiration from the relationship between prefix-tuning and mixture of experts, proposing a novel approach that employs a prompt pool for each task, capturing variations within each task while enhancing cross-task variances. Furthermore, we incorporate a generative model to consolidate prior knowledge within shared parameters, eliminating the need for explicit data storage. Extensive experiments validate the efficacy of our approach, demonstrating superior performance over state-of-the-art prompt-based and rehearsal-free methods in continual relation extraction.
Tracking Software Security Topics
Sep 27, 2024Software security incidents occur everyday and thousands of software security reports are announced each month. Thus, it is difficult for software security researchers, engineers, and other stakeholders to follow software security topics of their interests in real-time. In this paper, we propose, SOSK, a novel tool for this problem. SOSK allows a user to import a collection of software security reports. It pre-processes and extracts the most important keywords from the textual description of the reports. Based on the similarity of embedding vectors of keywords, SOSK can expand and/or refine a keyword set from a much smaller set of user-provided keywords. Thus, SOSK allows users to define any topic of their interests and retrieve security reports relevant to that topic effectively. Our preliminary evaluation shows that SOSK can expand keywords and retrieve reports relevant to user requests.
Defect Prediction with Content-based Features
Sep 27, 2024



Traditional defect prediction approaches often use metrics that measure the complexity of the design or implementing code of a software system, such as the number of lines of code in a source file. In this paper, we explore a different approach based on content of source code. Our key assumption is that source code of a software system contains information about its technical aspects and those aspects might have different levels of defect-proneness. Thus, content-based features such as words, topics, data types, and package names extracted from a source code file could be used to predict its defects. We have performed an extensive empirical evaluation and found that: i) such content-based features have higher predictive power than code complexity metrics and ii) the use of feature selection, reduction, and combination further improves the prediction performance.
Mining User Opinions in Mobile App Reviews: A Keyword-based Approach
Oct 26, 2015
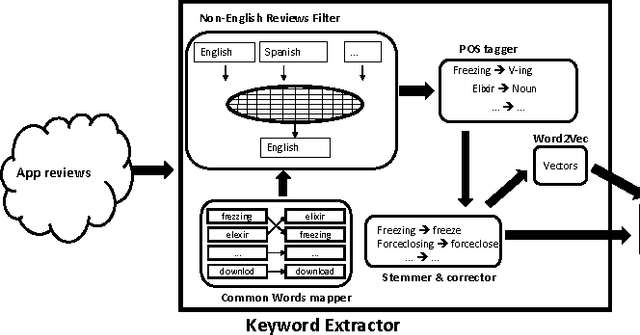
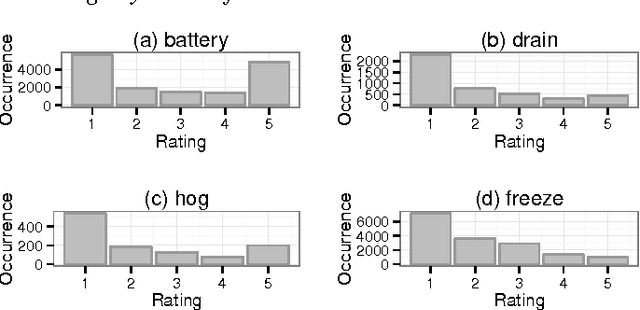

User reviews of mobile apps often contain complaints or suggestions which are valuable for app developers to improve user experience and satisfaction. However, due to the large volume and noisy-nature of those reviews, manually analyzing them for useful opinions is inherently challenging. To address this problem, we propose MARK, a keyword-based framework for semi-automated review analysis. MARK allows an analyst describing his interests in one or some mobile apps by a set of keywords. It then finds and lists the reviews most relevant to those keywords for further analysis. It can also draw the trends over time of those keywords and detect their sudden changes, which might indicate the occurrences of serious issues. To help analysts describe their interests more effectively, MARK can automatically extract keywords from raw reviews and rank them by their associations with negative reviews. In addition, based on a vector-based semantic representation of keywords, MARK can divide a large set of keywords into more cohesive subsets, or suggest keywords similar to the selected ones.