 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the generation of hierarchical attack models from cybersecurity vulnerabilities using language models
Oct 07, 2024



This paper investigates the use of a pre-trained language model and siamese network to discern sibling relationships between text-based cybersecurity vulnerability data. The ultimate purpose of the approach presented in this paper is towards the construction of hierarchical attack models based on a set of text descriptions characterising potential/observed vulnerabilities in a given system. Due to the nature of the data, and the uncertainty sensitive environment in which the problem is presented, a practically oriented soft computing approach is necessary. Therefore, a key focus of this work is to investigate practical questions surrounding the reliability of predicted links towards the construction of such models, to which end conceptual and practical challenges and solutions associated with the proposed approach are outlined, such as dataset complexity and stability of predictions. Accordingly, the contributions of this paper focus on producing neural networks using a pre-trained language model for predicting sibling relationships between cybersecurity vulnerabilities, then outlining how to apply this capability towards the generation of hierarchical attack models. In addition, two data sampling mechanisms for tackling data complexity, and a consensus mechanism for reducing the amount of false positive predictions are outlined. Each of these approaches is compared and contrasted using empirical results from three sets of cybersecurity data to determine their effectiveness.
Analyzing and controlling diversity in quantum-behaved particle swarm optimization
Aug 09, 2023



This paper addresses the issues of controlling and analyzing the population diversity in quantum-behaved particle swarm optimization (QPSO), which is an optimization approach motivated by concepts in quantum mechanics and PSO. In order to gain an in-depth understanding of the role the diversity plays in the evolving process, we first define the genotype diversity by the distance to the average point of the particles' positions and the phenotype diversity by the fitness values for the QPSO. Then, the correlations between the two types of diversities and the search performance are tested and analyzed on several benchmark functions, and the distance-to-average-point diversity is showed to have stronger association with the search performance during the evolving processes. Finally, in the light of the performed diversity analyses, two strategies for controlling the distance-to-average-point diversities are proposed for the purpose of improving the search ability of the QPSO algorithm. Empirical studies on the QPSO with the introduced diversity control methods are performed on a set of benchmark functions from the CEC 2005 benchmark suite. The performance of the proposed methods are evaluated and compared with the original QPSO and other PSO variants.
R-WhONet: Recalibrated Wheel Odometry Neural Network for Vehicular Positioning using Transfer Learning
Sep 13, 2022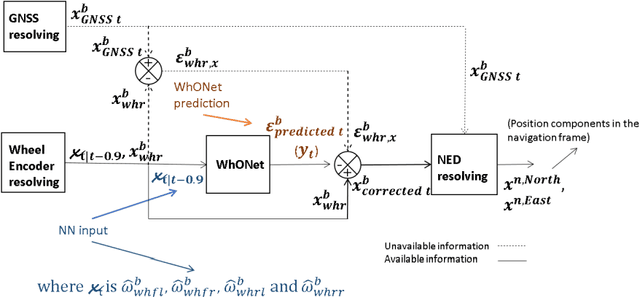
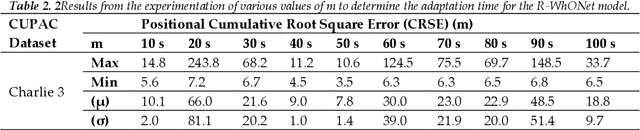
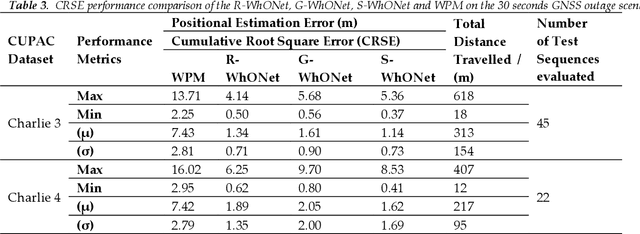
This paper proposes a transfer learning approach to recalibrate our previously developed Wheel Odometry Neural Network (WhONet) for vehicle positioning in environments where Global Navigation Satellite Systems (GNSS) are unavailable. The WhONet has been shown to possess the capability to learn the uncertainties in the wheel speed measurements needed for correction and accurate positioning of vehicles. These uncertainties may be manifested as tyre pressure changes from driving on muddy and uneven terrains or wheel slips. However, a common cause for concern for data-driven approaches, such as the WhONet model, is usually the inability to generalise the models to a new vehicle. In scenarios where machine learning models are trained in a specific domain but deployed in another domain, the model's performance degrades. In real-life scenarios, several factors are influential to this degradation, from changes to the dynamics of the vehicle to new pattern distributions of the sensor's noise, and bias will make the test sensor data vary from training data. Therefore, the challenge is to explore techniques that allow the trained machine learning models to spontaneously adjust to new vehicle domains. As such, we propose the Recalibrated-Wheel Odometry neural Network (R-WhONet), that adapts the WhONet model from its source domain (a vehicle and environment on which the model is initially trained) to the target domain (a new vehicle on which the trained model is to be deployed). Through a performance evaluation on several GNSS outage scenarios - short-term complex driving scenarios, and on longer-term GNSS outage scenarios. We demonstrate that a model trained in the source domain does not generalise well to a new vehicle in the target domain. However, we show that our new proposed framework improves the generalisation of the WhONet model to new vehicles in the target domains by up to 32%.
Attention Mechanism based Cognition-level Scene Understanding
Apr 19, 2022
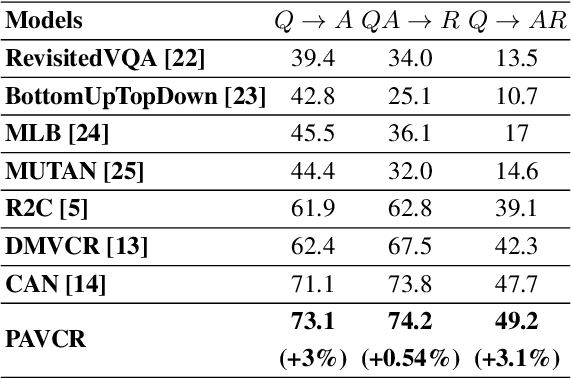
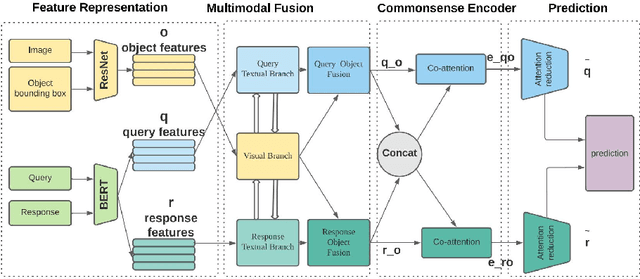

Given a question-image input, the Visual Commonsense Reasoning (VCR) model can predict an answer with the corresponding rationale, which requires inference ability from the real world. The VCR task, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge, is a cognition-level scene understanding task. The VCR task has aroused researchers' interest due to its wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and losing information in long sequences. In this paper, we propose a parallel attention-based cognitive VCR network PAVCR, which fuses visual-textual information efficiently and encodes semantic information in parallel to enable the model to capture rich information for cognition-level inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning.
Res2NetFuse: A Fusion Method for Infrared and Visible Images
Dec 29, 2021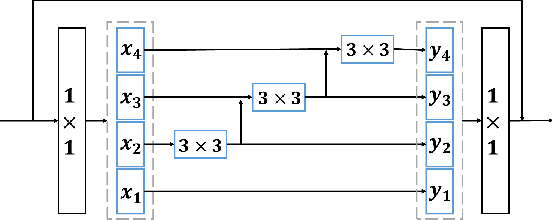
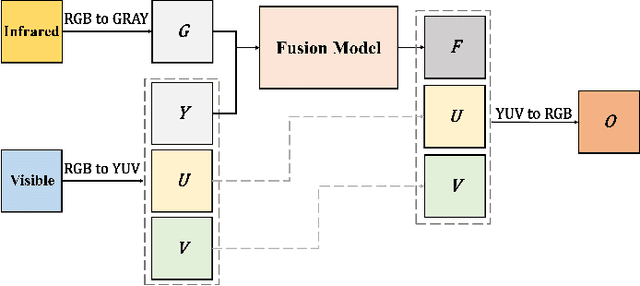

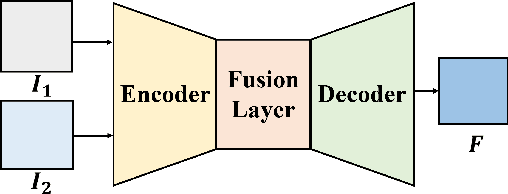
This paper presents a novel Res2Net-based fusion framework for infrared and visible images. The proposed fusion model has three parts: an encoder, a fusion layer and a decoder, respectively. The Res2Net-based encoder is used to extract multi-scale features of source images, the paper introducing a new training strategy for training a Res2Net-based encoder that uses only a single image. Then, a new fusion strategy is developed based on the attention model. Finally, the fused image is reconstructed by the decoder. The proposed approach is also analyzed in detail. Experiments show that our method achieves state-of-the-art fusion performance in objective and subjective assessment by comparing with the existing methods.
WhONet: Wheel Odometry Neural Network for Vehicular Localisation in GNSS-Deprived Environments
Apr 06, 2021
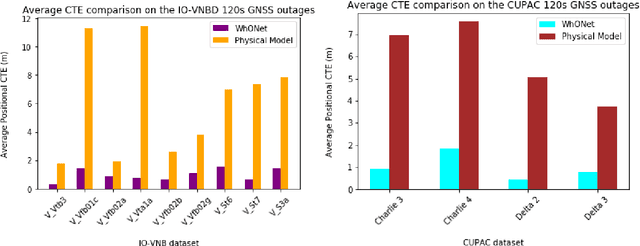
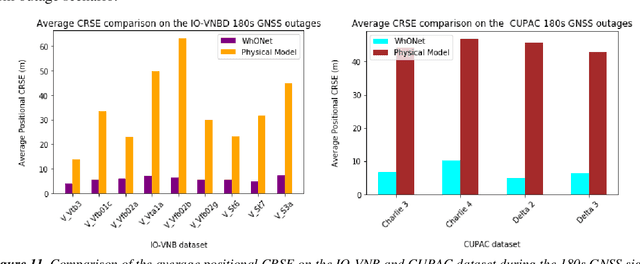
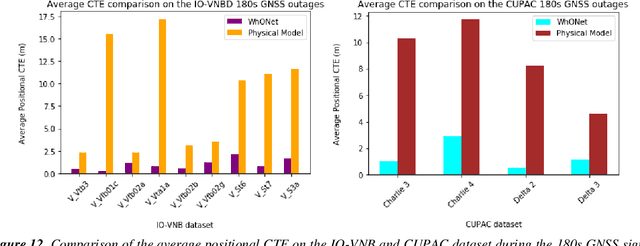
In this paper, a deep learning approach is proposed to accurately position wheeled vehicles in Global Navigation Satellite Systems (GNSS) deprived environments. In the absence of GNSS signals, information on the speed of the wheels of a vehicle (or other robots alike), recorded from the wheel encoder, can be used to provide continuous positioning information for the vehicle, through the integration of the vehicle's linear velocity to displacement. However, the displacement estimation from the wheel speed measurements are characterised by uncertainties, which could be manifested as wheel slips or/and changes to the tyre size or pressure, from wet and muddy road drives or tyres wearing out. As such, we exploit recent advances in deep learning to propose the Wheel Odometry neural Network (WhONet) to learn the uncertainties in the wheel speed measurements needed for correction and accurate positioning. The performance of the proposed WhONet is first evaluated on several challenging driving scenarios, such as on roundabouts, sharp cornering, hard-brake and wet roads (drifts). WhONet's performance is then further and extensively evaluated on longer-term GNSS outage scenarios of 30s, 60s, 120s and 180s duration, respectively over a total distance of 493 km. The experimental results obtained show that the proposed method is able to accurately position the vehicle with up to 93% reduction in the positioning error of its original counterpart after any 180s of travel. WhONet's implementation can be found at https://github.com/onyekpeu/WhONet.
Self-Supervised Transformers for Activity Classification using Ambient Sensors
Nov 22, 2020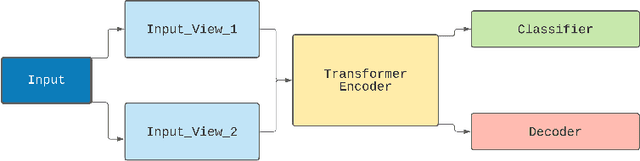
Providing care for ageing populations is an onerous task, and as life expectancy estimates continue to rise, the number of people that require senior care is growing rapidly. This paper proposes a methodology based on Transformer Neural Networks to classify the activities of a resident within an ambient sensor based environment. We also propose a methodology to pre-train Transformers in a self-supervised manner, as a hybrid autoencoder-classifier model instead of using contrastive loss. The social impact of the research is considered with wider benefits of the approach and next steps for identifying transitions in human behaviour. In recent years there has been an increasing drive for integrating sensor based technologies within care facilities for data collection. This allows for employing machine learning for many aspects including activity recognition and anomaly detection. Due to the sensitivity of healthcare environments, some methods of data collection used in current research are considered to be intrusive within the senior care industry, including cameras for image based activity recognition, and wearables for activity tracking, but recent studies have shown that using these methods commonly result in poor data quality due to the lack of resident interest in participating in data gathering. This has led to a focus on ambient sensors, such as binary PIR motion, connected domestic appliances, and electricity and water metering. By having consistency in ambient data collection, the quality of data is considerably more reliable, presenting the opportunity to perform classification with enhanced accuracy. Therefore, in this research we looked to find an optimal way of using deep learning to classify human activity with ambient sensor data.
Generative Adversarial Stacked Autoencoders
Nov 22, 2020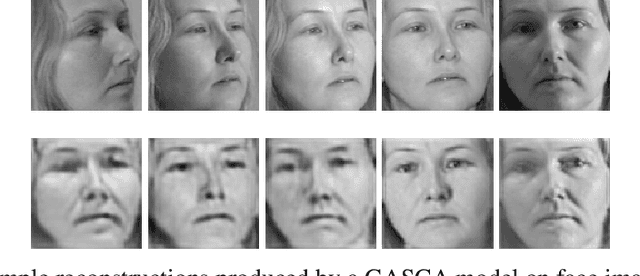
Generative Adversarial Networks (GANs) have become predominant in image generation tasks. Their success is attributed to the training regime which employs two models: a generator G and discriminator D that compete in a minimax zero sum game. Nonetheless, GANs are difficult to train due to their sensitivity to hyperparameter and parameter initialisation, which often leads to vanishing gradients, non-convergence, or mode collapse, where the generator is unable to create samples with different variations. In this work, we propose a novel Generative Adversarial Stacked Convolutional Autoencoder(GASCA) model and a generative adversarial gradual greedy layer-wise learning algorithm de-signed to train Adversarial Autoencoders in an efficient and incremental manner. Our training approach produces images with significantly lower reconstruction error than vanilla joint training.
* arXiv admin note: text overlap with arXiv:2007.09790
Parts of Speech Tagging in NLP: Runtime Optimization with Quantum Formulation and ZX Calculus
Jul 19, 2020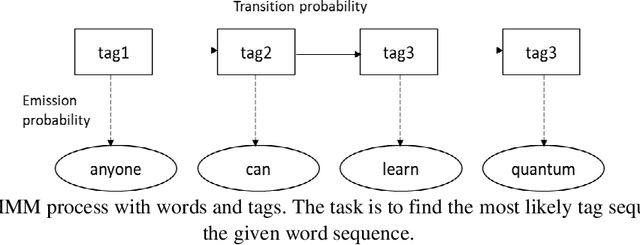
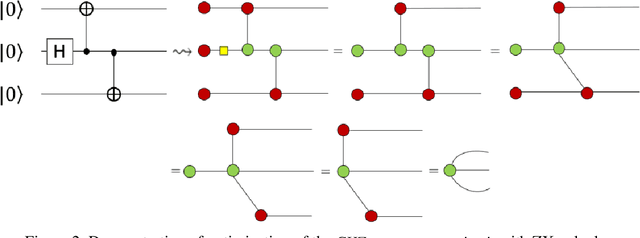
This paper proposes an optimized formulation of the parts of speech tagging in Natural Language Processing with a quantum computing approach and further demonstrates the quantum gate-level runnable optimization with ZX-calculus, keeping the implementation target in the context of Noisy Intermediate Scale Quantum Systems (NISQ). Our quantum formulation exhibits quadratic speed up over the classical counterpart and further demonstrates the implementable optimization with the help of ZX calculus postulates.
Generative Adversarial Stacked Autoencoders for Facial Pose Normalization and Emotion Recognition
Jul 19, 2020
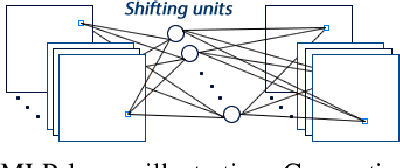
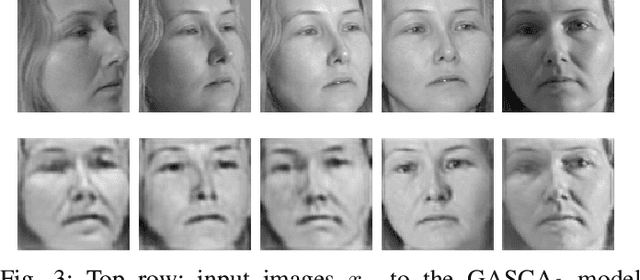

In this work, we propose a novel Generative Adversarial Stacked Autoencoder that learns to map facial expressions, with up to plus or minus 60 degrees, to an illumination invariant facial representation of 0 degrees. We accomplish this by using a novel convolutional layer that exploits both local and global spatial information, and a convolutional layer with a reduced number of parameters that exploits facial symmetry. Furthermore, we introduce a generative adversarial gradual greedy layer-wise learning algorithm designed to train Adversarial Autoencoders in an efficient and incremental manner. We demonstrate the efficiency of our method and report state-of-the-art performance on several facial emotion recognition corpora, including one collected in the wild.