 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Complexity for Quantum Approaches in Train Load Optimization
Mar 31, 2026Efficiently planning container loads onto trains is a computationally challenging combinatorial optimization problem, central to logistics and supply chain management. A primary source of this complexity arises from the need to model and reduce rehandle operations-unproductive crane moves required to access blocked containers. Conventional mathematical formulations address this by introducing explicit binary variables and a web of logical constraints for each potential rehandle, resulting in large-scale models that are difficult to solve. This paper presents a fundamental departure from this paradigm. We introduce an innovative and compact mathematical formulation for the Train Load Optimization (TLO) problem where the rehandle cost is calculated implicitly within the objective function. This novel approach helps prevent the need for dedicated rehandle variables and their associated constraints, leading to a dramatic reduction in model size. We provide a formal comparison against a conventional model to analytically demonstrate the significant reduction in the number of variables and constraints. The efficacy of our compact formulation is assessed through a simulated annealing metaheuristic, which finds high-quality loading plans for various problem instances. The results confirm that our model is not only more parsimonious but also practically effective, offering a scalable and powerful tool for modern rail logistics.
Quantum-Secure-By-Construction (QSC): A Paradigm Shift For Post-Quantum Agentic Intelligence
Mar 12, 2026As agentic artificial intelligence systems scale across globally distributed and long lived infrastructures, secure and policy compliant communication becomes a fundamental systems challenge. This challenge grows more serious in the quantum era, where the cryptographic assumptions built into today's AI deployments may not remain valid over their operational lifetime. Here, we introduce quantum secure by construction, or QSC, as a design paradigm that treats quantum secure communication as a core architectural property of agentic AI systems rather than an upgrade added later. We realize QSC through a runtime adaptive security model that combines post quantum cryptography, quantum random number generation, and quantum key distribution to secure interactions among autonomous agents operating across heterogeneous cloud, edge, and inter organizational environments. The approach is cryptographically pluggable and guided by policy, allowing the system to adjust its security posture according to infrastructure availability, regulatory constraints, and performance needs. QSC contributes a governance aware orchestration layer that selects and combines link specific cryptographic protections across the full agent lifecycle, including session bootstrap, inter agent coordination, tool invocation, and memory access. Through system level analysis and empirical evaluation, we examine the trade offs between classical and quantum secure mechanisms and show that QSC can reduce the operational complexity and cost of introducing quantum security into deployed agentic AI systems. These results position QSC as a foundational paradigm for post quantum agentic intelligence and establish a principled pathway for designing globally interoperable, resilient, and future ready intelligent systems.
Towards Resource-Efficient Multimodal Intelligence: Learned Routing among Specialized Expert Models
Nov 09, 2025As AI moves beyond text, large language models (LLMs) increasingly power vision, audio, and document understanding; however, their high inference costs hinder real-time, scalable deployment. Conversely, smaller open-source models offer cost advantages but struggle with complex or multimodal queries. We introduce a unified, modular framework that intelligently routes each query - textual, multimodal, or complex - to the most fitting expert model, using a learned routing network that balances cost and quality. For vision tasks, we employ a two-stage open-source pipeline optimized for efficiency and reviving efficient classical vision components where they remain SOTA for sub-tasks. On benchmarks such as Massive Multitask Language Understanding (MMLU) and Visual Question Answering (VQA), we match or exceed the performance of always-premium LLM (monolithic systems with one model serving all query types) performance, yet reduce the reliance on costly models by over 67%. With its extensible, multi-agent orchestration, we deliver high-quality, resource-efficient AI at scale.
Comprehensive Study on Performance Evaluation and Optimization of Model Compression: Bridging Traditional Deep Learning and Large Language Models
Jul 22, 2024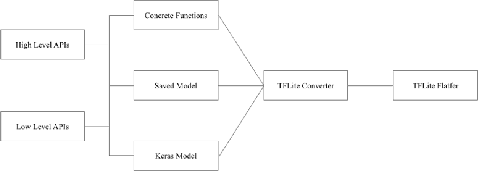
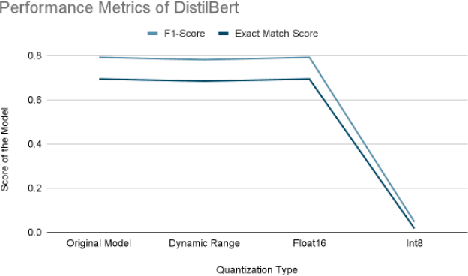
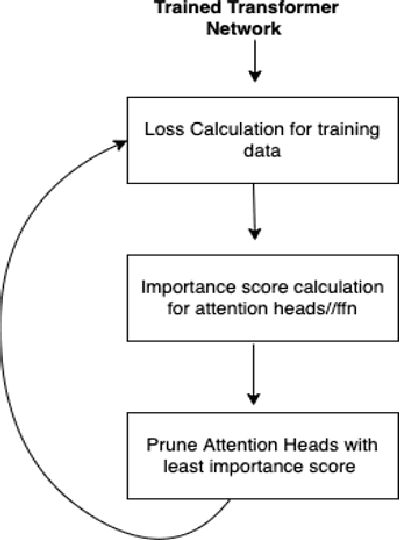
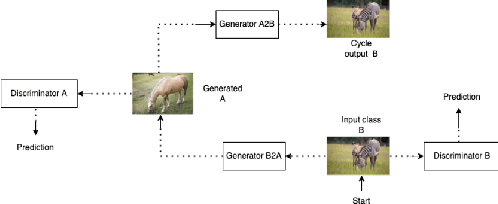
Deep learning models have achieved tremendous success in most of the industries in recent years. The evolution of these models has also led to an increase in the model size and energy requirement, making it difficult to deploy in production on low compute devices. An increase in the number of connected devices around the world warrants compressed models that can be easily deployed at the local devices with low compute capacity and power accessibility. A wide range of solutions have been proposed by different researchers to reduce the size and complexity of such models, prominent among them are, Weight Quantization, Parameter Pruning, Network Pruning, low-rank representation, weights sharing, neural architecture search, knowledge distillation etc. In this research work, we investigate the performance impacts on various trained deep learning models, compressed using quantization and pruning techniques. We implemented both, quantization and pruning, compression techniques on popular deep learning models used in the image classification, object detection, language models and generative models-based problem statements. We also explored performance of various large language models (LLMs) after quantization and low rank adaptation. We used the standard evaluation metrics (model's size, accuracy, and inference time) for all the related problem statements and concluded this paper by discussing the challenges and future work.
Investigation into the Potential of Parallel Quantum Annealing for Simultaneous Optimization of Multiple Problems: A Comprehensive Study
Mar 09, 2024Parallel Quantum Annealing is a technique to solve multiple optimization problems simultaneously. Parallel quantum annealing aims to optimize the utilization of available qubits on a quantum topology by addressing multiple independent problems in a single annealing cycle. This study provides insights into the potential and the limitations of this parallelization method. The experiments consisting of two different problems are integrated, and various problem dimensions are explored including normalization techniques using specific methods such as DWaveSampler with Default Embedding, DWaveSampler with Custom Embedding and LeapHybridSampler. This method minimizes idle qubits and holds promise for substantial speed-up, as indicated by the Time-to-Solution (TTS) metric, compared to traditional quantum annealing, which solves problems sequentially and may leave qubits unutilized.
Parts of Speech Tagging in NLP: Runtime Optimization with Quantum Formulation and ZX Calculus
Jul 19, 2020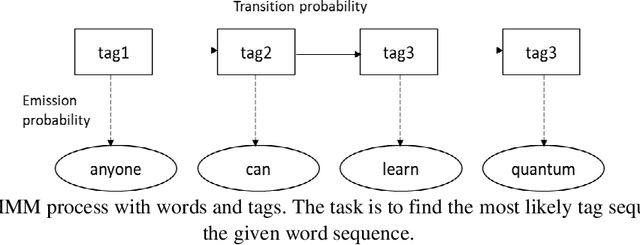
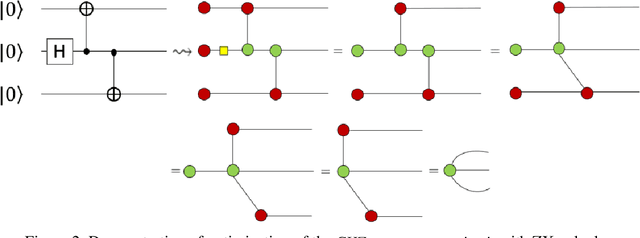
This paper proposes an optimized formulation of the parts of speech tagging in Natural Language Processing with a quantum computing approach and further demonstrates the quantum gate-level runnable optimization with ZX-calculus, keeping the implementation target in the context of Noisy Intermediate Scale Quantum Systems (NISQ). Our quantum formulation exhibits quadratic speed up over the classical counterpart and further demonstrates the implementable optimization with the help of ZX calculus postulates.
An Investigation of Quantum Deep Clustering Framework with Quantum Deep SVM & Convolutional Neural Network Feature Extractor
Sep 21, 2019In this paper, we have proposed a deep quantum SVM formulation, and further demonstrated a quantum-clustering framework based on the quantum deep SVM formulation, deep convolutional neural networks, and quantum K-Means clustering. We have investigated the run time computational complexity of the proposed quantum deep clustering framework and compared with the possible classical implementation. Our investigation shows that the proposed quantum version of deep clustering formulation demonstrates a significant performance gain (exponential speed up gains in many sections) against the possible classical implementation. The proposed theoretical quantum deep clustering framework is also interesting & novel research towards the quantum-classical machine learning formulation to articulate the maximum performance.
An All-Pair Quantum SVM Approach for Big Data Multiclass Classification
May 15, 2018
In this paper, we have discussed a quantum approach for the all-pair multiclass classification problem. We have shown that the multiclass support vector machine for big data classification with a quantum all-pair approach can be implemented in logarithm runtime complexity on a quantum computer. In an all-pair approach, there is one binary classification problem for each pair of classes, and so there are k (k-1)/2 classifiers for a k-class problem. As compared to the classical multiclass support vector machine that can be implemented with polynomial run time complexity, our approach exhibits exponential speed up in the quantum version. The quantum all-pair algorithm can be used with other classification algorithms, and a speed up gain can be achieved as compared to their classical counterparts.
Big Data Quantum Support Vector Clustering
Apr 29, 2018Clustering is a complex process in finding the relevant hidden patterns in unlabeled datasets, broadly known as unsupervised learning. Support vector clustering algorithm is a well-known clustering algorithm based on support vector machines and Gaussian kernels. In this paper, we have investigated the support vector clustering algorithm in quantum paradigm. We have developed a quantum algorithm which is based on quantum support vector machine and the quantum kernel (Gaussian kernel and polynomial kernel) formulation. The investigation exhibits approximately exponential speed up in the quantum version with respect to the classical counterpart.
Gaussian Kernel in Quantum Paradigm
Nov 04, 2017Gaussian kernel is a very popular kernel function used in many machine learning algorithms, especially in support vector machines (SVM). For nonlinear training instances in machine learning, it often outperforms polynomial kernels in model accuracy. The Gaussian kernel is heavily used in formulating nonlinear classical SVM. A very elegant quantum version of least square support vector machine which is exponentially faster than the classical counterparts was discussed in literature with quantum polynomial kernel. In this paper, we have demonstrated a quantum version of the Gaussian kernel and analyzed its complexity, which is O(\epsilon^(-1)logN) with N-dimensional instances and an accuracy \epsilon. The Gaussian kernel is not only more efficient than polynomial kernel but also has broader application range than polynomial kernel.