 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Based Toolpath Planner on Diverse Graphs for 3D Printing
Aug 17, 2024



This paper presents a learning based planner for computing optimized 3D printing toolpaths on prescribed graphs, the challenges of which include the varying graph structures on different models and the large scale of nodes & edges on a graph. We adopt an on-the-fly strategy to tackle these challenges, formulating the planner as a Deep Q-Network (DQN) based optimizer to decide the next `best' node to visit. We construct the state spaces by the Local Search Graph (LSG) centered at different nodes on a graph, which is encoded by a carefully designed algorithm so that LSGs in similar configurations can be identified to re-use the earlier learned DQN priors for accelerating the computation of toolpath planning. Our method can cover different 3D printing applications by defining their corresponding reward functions. Toolpath planning problems in wire-frame printing, continuous fiber printing, and metallic printing are selected to demonstrate its generality. The performance of our planner has been verified by testing the resultant toolpaths in physical experiments. By using our planner, wire-frame models with up to 4.2k struts can be successfully printed, up to 93.3% of sharp turns on continuous fiber toolpaths can be avoided, and the thermal distortion in metallic printing can be reduced by 24.9%.
A Medical Image Fusion Method based on MDLatLRRv2
Jul 02, 2022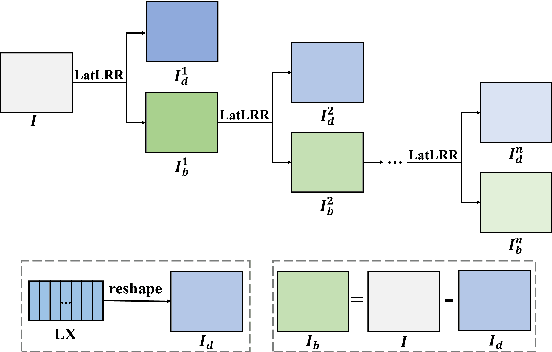
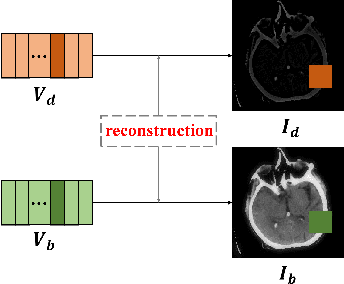
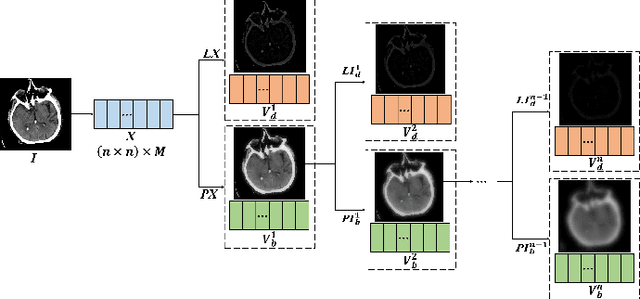
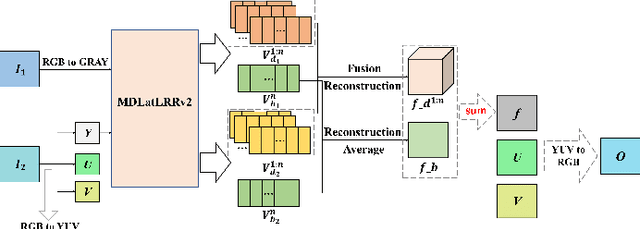
Since MDLatLRR only considers detailed parts (salient features) of input images extracted by latent low-rank representation (LatLRR), it doesn't use base parts (principal features) extracted by LatLRR effectively. Therefore, we proposed an improved multi-level decomposition method called MDLatLRRv2 which effectively analyzes and utilizes all the image features obtained by LatLRR. Then we apply MDLatLRRv2 to medical image fusion. The base parts are fused by average strategy and the detail parts are fused by nuclear-norm operation. The comparison with the existing methods demonstrates that the proposed method can achieve state-of-the-art fusion performance in objective and subjective assessment.
Res2NetFuse: A Fusion Method for Infrared and Visible Images
Dec 29, 2021

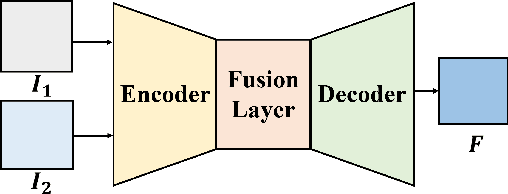
This paper presents a novel Res2Net-based fusion framework for infrared and visible images. The proposed fusion model has three parts: an encoder, a fusion layer and a decoder, respectively. The Res2Net-based encoder is used to extract multi-scale features of source images, the paper introducing a new training strategy for training a Res2Net-based encoder that uses only a single image. Then, a new fusion strategy is developed based on the attention model. Finally, the fused image is reconstructed by the decoder. The proposed approach is also analyzed in detail. Experiments show that our method achieves state-of-the-art fusion performance in objective and subjective assessment by comparing with the existing methods.