 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Co-Optimization of Structural Topology, Manufacturable Layers, and Path Orientations for Fiber-Reinforced Composites
Apr 30, 2025We propose a neural network-based computational framework for the simultaneous optimization of structural topology, curved layers, and path orientations to achieve strong anisotropic strength in fiber-reinforced thermoplastic composites while ensuring manufacturability. Our framework employs three implicit neural fields to represent geometric shape, layer sequence, and fiber orientation. This enables the direct formulation of both design and manufacturability objectives - such as anisotropic strength, structural volume, machine motion control, layer curvature, and layer thickness - into an integrated and differentiable optimization process. By incorporating these objectives as loss functions, the framework ensures that the resultant composites exhibit optimized mechanical strength while remaining its manufacturability for filament-based multi-axis 3D printing across diverse hardware platforms. Physical experiments demonstrate that the composites generated by our co-optimization method can achieve an improvement of up to 33.1% in failure loads compared to composites with sequentially optimized structures and manufacturing sequences.
SafeCast: Risk-Responsive Motion Forecasting for Autonomous Vehicles
Mar 28, 2025Accurate motion forecasting is essential for the safety and reliability of autonomous driving (AD) systems. While existing methods have made significant progress, they often overlook explicit safety constraints and struggle to capture the complex interactions among traffic agents, environmental factors, and motion dynamics. To address these challenges, we present SafeCast, a risk-responsive motion forecasting model that integrates safety-aware decision-making with uncertainty-aware adaptability. SafeCast is the first to incorporate the Responsibility-Sensitive Safety (RSS) framework into motion forecasting, encoding interpretable safety rules--such as safe distances and collision avoidance--based on traffic norms and physical principles. To further enhance robustness, we introduce the Graph Uncertainty Feature (GUF), a graph-based module that injects learnable noise into Graph Attention Networks, capturing real-world uncertainties and enhancing generalization across diverse scenarios. We evaluate SafeCast on four real-world benchmark datasets--Next Generation Simulation (NGSIM), Highway Drone (HighD), ApolloScape, and the Macao Connected Autonomous Driving (MoCAD)--covering highway, urban, and mixed-autonomy traffic environments. Our model achieves state-of-the-art (SOTA) accuracy while maintaining a lightweight architecture and low inference latency, underscoring its potential for real-time deployment in safety-critical AD systems.
3D Distance-color-coded Assessment of PCI Stent Apposition via Deep-learning-based Three-dimensional Multi-object Segmentation
Oct 26, 2024Coronary artery disease poses a significant global health challenge, often necessitating percutaneous coronary intervention (PCI) with stent implantation. Assessing stent apposition holds pivotal importance in averting and identifying PCI complications that lead to in-stent restenosis. Here we proposed a novel three-dimensional (3D) distance-color-coded assessment (DccA)for PCI stent apposition via deep-learning-based 3D multi-object segmentation in intravascular optical coherence tomography (IV-OCT). Our proposed 3D DccA accurately segments 3D vessel lumens and stents in IV-OCT images, using a spatial matching network and dual-layer training with style transfer. It quantifies and maps stent-lumen distances into a 3D color space, facilitating 3D visual assessment of PCI stent apposition. Achieving over 95% segmentation precision, our proposed DccA enhances clinical evaluation of PCI stent deployment and supports personalized treatment planning.
Learning Based Toolpath Planner on Diverse Graphs for 3D Printing
Aug 17, 2024



This paper presents a learning based planner for computing optimized 3D printing toolpaths on prescribed graphs, the challenges of which include the varying graph structures on different models and the large scale of nodes & edges on a graph. We adopt an on-the-fly strategy to tackle these challenges, formulating the planner as a Deep Q-Network (DQN) based optimizer to decide the next `best' node to visit. We construct the state spaces by the Local Search Graph (LSG) centered at different nodes on a graph, which is encoded by a carefully designed algorithm so that LSGs in similar configurations can be identified to re-use the earlier learned DQN priors for accelerating the computation of toolpath planning. Our method can cover different 3D printing applications by defining their corresponding reward functions. Toolpath planning problems in wire-frame printing, continuous fiber printing, and metallic printing are selected to demonstrate its generality. The performance of our planner has been verified by testing the resultant toolpaths in physical experiments. By using our planner, wire-frame models with up to 4.2k struts can be successfully printed, up to 93.3% of sharp turns on continuous fiber toolpaths can be avoided, and the thermal distortion in metallic printing can be reduced by 24.9%.
Less is More: Efficient Brain-Inspired Learning for Autonomous Driving Trajectory Prediction
Jul 09, 2024Accurately and safely predicting the trajectories of surrounding vehicles is essential for fully realizing autonomous driving (AD). This paper presents the Human-Like Trajectory Prediction model (HLTP++), which emulates human cognitive processes to improve trajectory prediction in AD. HLTP++ incorporates a novel teacher-student knowledge distillation framework. The "teacher" model equipped with an adaptive visual sector, mimics the dynamic allocation of attention human drivers exhibit based on factors like spatial orientation, proximity, and driving speed. On the other hand, the "student" model focuses on real-time interaction and human decision-making, drawing parallels to the human memory storage mechanism. Furthermore, we improve the model's efficiency by introducing a new Fourier Adaptive Spike Neural Network (FA-SNN), allowing for faster and more precise predictions with fewer parameters. Evaluated using the NGSIM, HighD, and MoCAD benchmarks, HLTP++ demonstrates superior performance compared to existing models, which reduces the predicted trajectory error with over 11% on the NGSIM dataset and 25% on the HighD datasets. Moreover, HLTP++ demonstrates strong adaptability in challenging environments with incomplete input data. This marks a significant stride in the journey towards fully AD systems.
Image Super-resolution Reconstruction Network based on Enhanced Swin Transformer via Alternating Aggregation of Local-Global Features
Jan 16, 2024



The Swin Transformer image super-resolution reconstruction network only relies on the long-range relationship of window attention and shifted window attention to explore features. This mechanism has two limitations. On the one hand, it only focuses on global features while ignoring local features. On the other hand, it is only concerned with spatial feature interactions while ignoring channel features and channel interactions, thus limiting its non-linear mapping ability. To address the above limitations, this paper proposes enhanced Swin Transformer modules via alternating aggregation of local-global features. In the local feature aggregation stage, we introduce a shift convolution to realize the interaction between local spatial information and channel information. Then, a block sparse global perception module is introduced in the global feature aggregation stage. In this module, we reorganize the spatial information first, then send the recombination information into a multi-layer perceptron unit to implement the global perception. After that, a multi-scale self-attention module and a low-parameter residual channel attention module are introduced to realize information aggregation at different scales. Finally, the proposed network is validated on five publicly available datasets. The experimental results show that the proposed network outperforms the other state-of-the-art super-resolution networks.
RoMo-HER: Robust Model-based Hindsight Experience Replay
Jun 28, 2023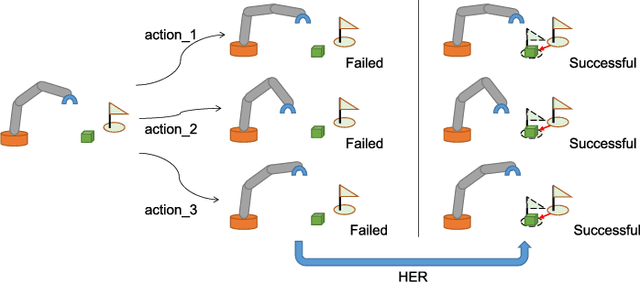
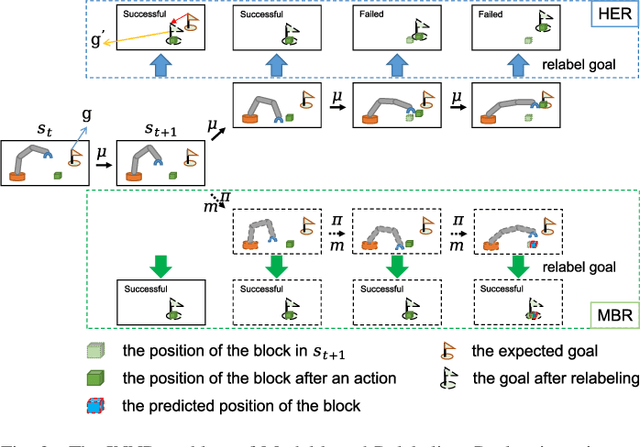
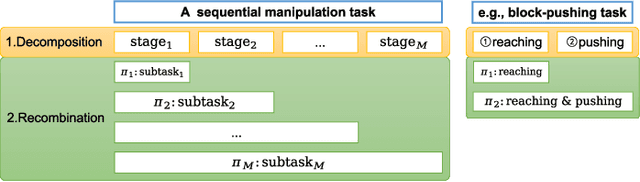
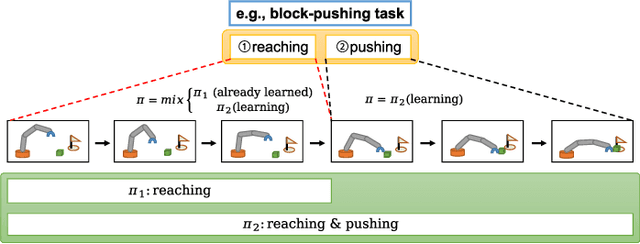
Sparse rewards are one of the factors leading to low sample efficiency in multi-goal reinforcement learning (RL). Based on Hindsight Experience Replay (HER), model-based relabeling methods have been proposed to relabel goals using virtual trajectories obtained by interacting with the trained model, which can effectively enhance the sample efficiency in accurately modelable sparse-reward environments. However, they are ineffective in robot manipulation environment. In our paper, we design a robust framework called Robust Model-based Hindsight Experience Replay (RoMo-HER) which can effectively utilize the dynamical model in robot manipulation environments to enhance the sample efficiency. RoMo-HER is built upon a dynamics model and a novel goal relabeling technique called Foresight relabeling (FR), which selects the prediction starting state with a specific strategy, predicts the future trajectory of the starting state, and then relabels the goal using the dynamics model and the latest policy to train the agent. Experimental results show that RoMo-HER has higher sample efficiency than HER and Model-based Hindsight Experience Replay in several simulated robot manipulation environments. Furthermore, we integrate RoMo-HER and Relay Hindsight Experience Replay (RHER), which currently exhibits the highest sampling efficiency in most benchmark environments, resulting in a novel approach called Robust Model-based Relay Hindsight Experience Replay (RoMo-RHER). Our experimental results demonstrate that RoMo-RHER achieves higher sample efficiency over RHER, outperforming RHER by 25% and 26% in FetchPush-v1 and FetchPickandPlace-v1, respectively.
Why semantics matters: A deep study on semantic particle-filtering localization in a LiDAR semantic pole-map
May 23, 2023



In most urban and suburban areas, pole-like structures such as tree trunks or utility poles are ubiquitous. These structural landmarks are very useful for the localization of autonomous vehicles given their geometrical locations in maps and measurements from sensors. In this work, we aim at creating an accurate map for autonomous vehicles or robots with pole-like structures as the dominant localization landmarks, hence called pole-map. In contrast to the previous pole-based mapping or localization methods, we exploit the semantics of pole-like structures. Specifically, semantic segmentation is achieved by a new mask-range transformer network in a mask-classfication paradigm. With the semantics extracted for the pole-like structures in each frame, a multi-layer semantic pole-map is created by aggregating the detected pole-like structures from all frames. Given the semantic pole-map, we propose a semantic particle-filtering localization scheme for vehicle localization. Theoretically, we have analyzed why the semantic information can benefit the particle-filter localization, and empirically it is validated on the public SemanticKITTI dataset that the particle-filtering localization with semantics achieves much better performance than the counterpart without semantics when each particle's odometry prediction and/or the online observation is subject to uncertainties at significant levels.
Support Generation for Robot-Assisted 3D Printing with Curved Layers
Feb 10, 2023



Robot-assisted 3D printing has drawn a lot of attention by its capability to fabricate curved layers that are optimized according to different objectives. However, the support generation algorithm based on a fixed printing direction for planar layers cannot be directly applied for curved layers as the orientation of material accumulation is dynamically varied. In this paper, we propose a skeleton-based support generation method for robot-assisted 3D printing with curved layers. The support is represented as an implicit solid so that the problems of numerical robustness can be effectively avoided. The effectiveness of our algorithm is verified on a dual-material printing platform that consists of a robotic arm and a newly designed dual-material extruder. Experiments have been successfully conducted on our system to fabricate a variety of freeform models.
MaskRange: A Mask-classification Model for Range-view based LiDAR Segmentation
Jun 24, 2022
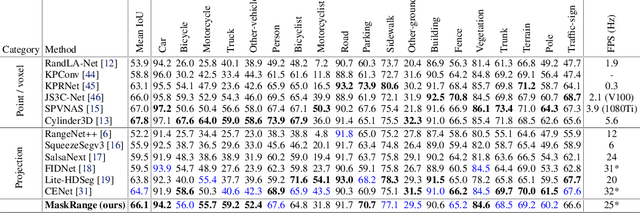


Range-view based LiDAR segmentation methods are attractive for practical applications due to their direct inheritance from efficient 2D CNN architectures. In literature, most range-view based methods follow the per-pixel classification paradigm. Recently, in the image segmentation domain, another paradigm formulates segmentation as a mask-classification problem and has achieved remarkable performance. This raises an interesting question: can the mask-classification paradigm benefit the range-view based LiDAR segmentation and achieve better performance than the counterpart per-pixel paradigm? To answer this question, we propose a unified mask-classification model, MaskRange, for the range-view based LiDAR semantic and panoptic segmentation. Along with the new paradigm, we also propose a novel data augmentation method to deal with overfitting, context-reliance, and class-imbalance problems. Extensive experiments are conducted on the SemanticKITTI benchmark. Among all published range-view based methods, our MaskRange achieves state-of-the-art performance with $66.10$ mIoU on semantic segmentation and promising results with $53.10$ PQ on panoptic segmentation with high efficiency. Our code will be released.