 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMo-HER: Robust Model-based Hindsight Experience Replay
Paper and Code
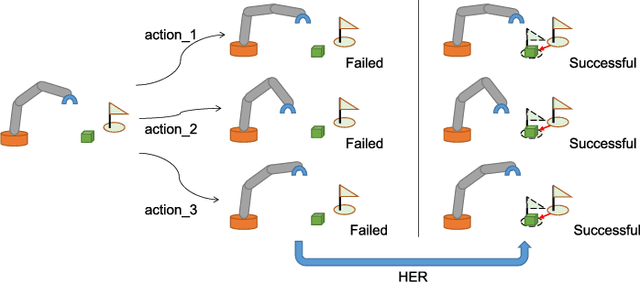
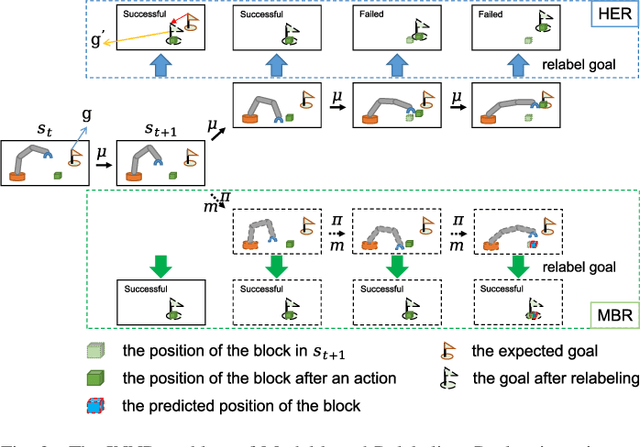
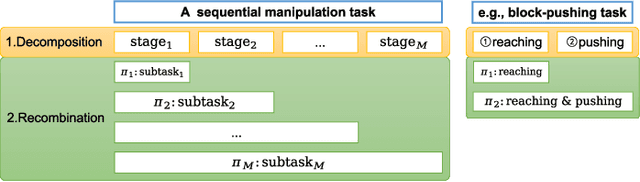
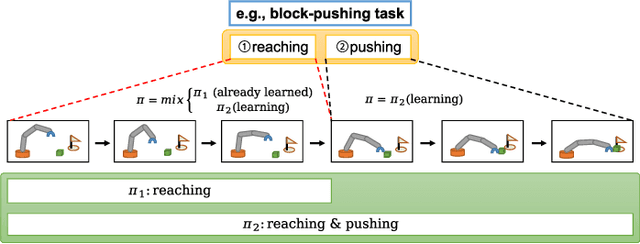
Sparse rewards are one of the factors leading to low sample efficiency in multi-goal reinforcement learning (RL). Based on Hindsight Experience Replay (HER), model-based relabeling methods have been proposed to relabel goals using virtual trajectories obtained by interacting with the trained model, which can effectively enhance the sample efficiency in accurately modelable sparse-reward environments. However, they are ineffective in robot manipulation environment. In our paper, we design a robust framework called Robust Model-based Hindsight Experience Replay (RoMo-HER) which can effectively utilize the dynamical model in robot manipulation environments to enhance the sample efficiency. RoMo-HER is built upon a dynamics model and a novel goal relabeling technique called Foresight relabeling (FR), which selects the prediction starting state with a specific strategy, predicts the future trajectory of the starting state, and then relabels the goal using the dynamics model and the latest policy to train the agent. Experimental results show that RoMo-HER has higher sample efficiency than HER and Model-based Hindsight Experience Replay in several simulated robot manipulation environments. Furthermore, we integrate RoMo-HER and Relay Hindsight Experience Replay (RHER), which currently exhibits the highest sampling efficiency in most benchmark environments, resulting in a novel approach called Robust Model-based Relay Hindsight Experience Replay (RoMo-RHER). Our experimental results demonstrate that RoMo-RHER achieves higher sample efficiency over RHER, outperforming RHER by 25% and 26% in FetchPush-v1 and FetchPickandPlace-v1, respectively.