Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRes2NetFuse: A Fusion Method for Infrared and Visible Images
Paper and Code
Dec 29, 2021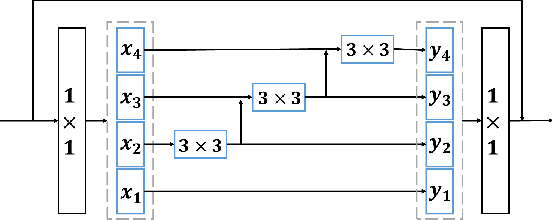
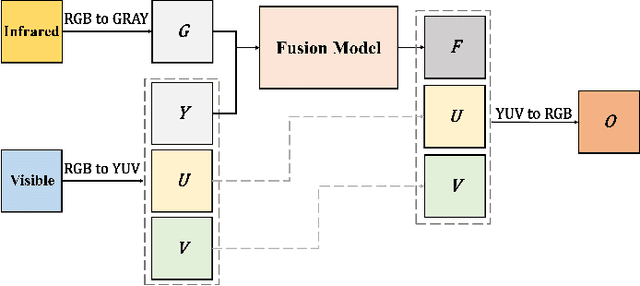

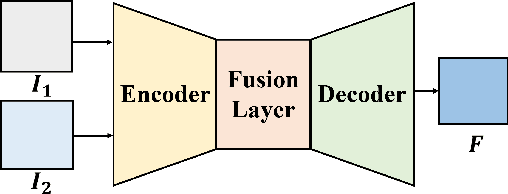
This paper presents a novel Res2Net-based fusion framework for infrared and visible images. The proposed fusion model has three parts: an encoder, a fusion layer and a decoder, respectively. The Res2Net-based encoder is used to extract multi-scale features of source images, the paper introducing a new training strategy for training a Res2Net-based encoder that uses only a single image. Then, a new fusion strategy is developed based on the attention model. Finally, the fused image is reconstructed by the decoder. The proposed approach is also analyzed in detail. Experiments show that our method achieves state-of-the-art fusion performance in objective and subjective assessment by comparing with the existing methods.
View paper on