 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Discriminatory Decision-making in Evolving Data Streams
Feb 16, 2023
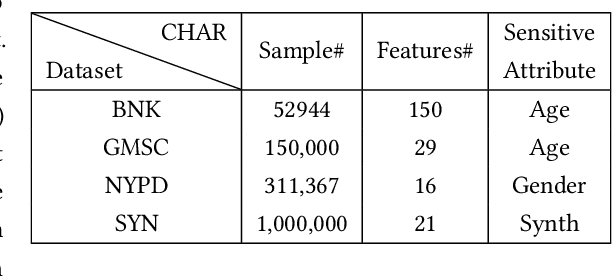


Bias in machine learning has rightly received significant attention over the last decade. However, most fair machine learning (fair-ML) work to address bias in decision-making systems has focused solely on the offline setting. Despite the wide prevalence of online systems in the real world, work on identifying and correcting bias in the online setting is severely lacking. The unique challenges of the online environment make addressing bias more difficult than in the offline setting. First, Streaming Machine Learning (SML) algorithms must deal with the constantly evolving real-time data stream. Second, they need to adapt to changing data distributions (concept drift) to make accurate predictions on new incoming data. Adding fairness constraints to this already complicated task is not straightforward. In this work, we focus on the challenges of achieving fairness in biased data streams while accounting for the presence of concept drift, accessing one sample at a time. We present Fair Sampling over Stream ($FS^2$), a novel fair rebalancing approach capable of being integrated with SML classification algorithms. Furthermore, we devise the first unified performance-fairness metric, Fairness Bonded Utility (FBU), to evaluate and compare the trade-off between performance and fairness of different bias mitigation methods efficiently. FBU simplifies the comparison of fairness-performance trade-offs of multiple techniques through one unified and intuitive evaluation, allowing model designers to easily choose a technique. Overall, extensive evaluations show our measures surpass those of other fair online techniques previously reported in the literature.
A Survey on Bias and Fairness in Machine Learning
Sep 17, 2019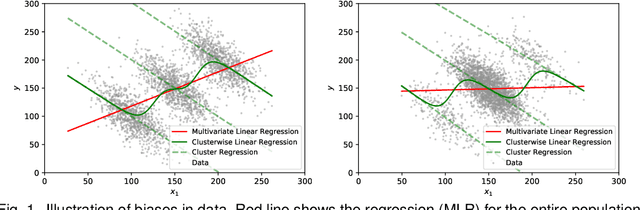

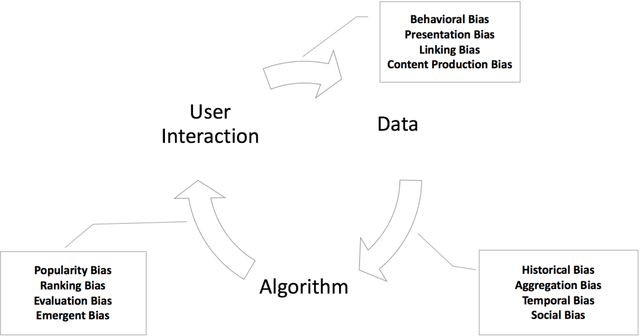

With the widespread use of AI systems and applications in our everyday lives, it is important to take fairness issues into consideration while designing and engineering these types of systems. Such systems can be used in many sensitive environments to make important and life-changing decisions; thus, it is crucial to ensure that the decisions do not reflect discriminatory behavior toward certain groups or populations. We have recently seen work in machine learning, natural language processing, and deep learning that addresses such challenges in different subdomains. With the commercialization of these systems, researchers are becoming aware of the biases that these applications can contain and have attempted to address them. In this survey we investigated different real-world applications that have shown biases in various ways, and we listed different sources of biases that can affect AI applications. We then created a taxonomy for fairness definitions that machine learning researchers have defined in order to avoid the existing bias in AI systems. In addition to that, we examined different domains and subdomains in AI showing what researchers have observed with regard to unfair outcomes in the state-of-the-art methods and how they have tried to address them. There are still many future directions and solutions that can be taken to mitigate the problem of bias in AI systems. We are hoping that this survey will motivate researchers to tackle these issues in the near future by observing existing work in their respective fields.
How Do Fairness Definitions Fare? Examining Public Attitudes Towards Algorithmic Definitions of Fairness
Nov 08, 2018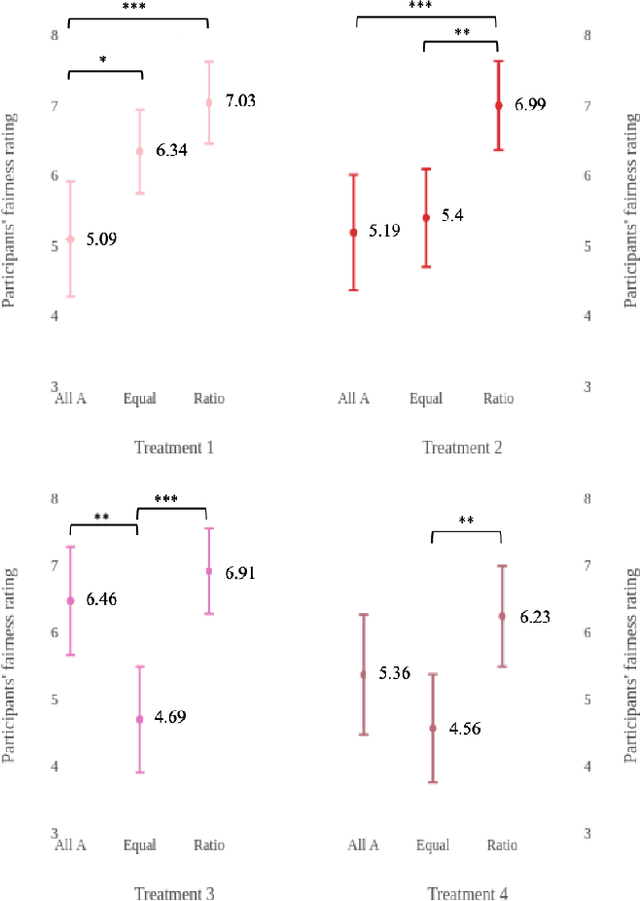
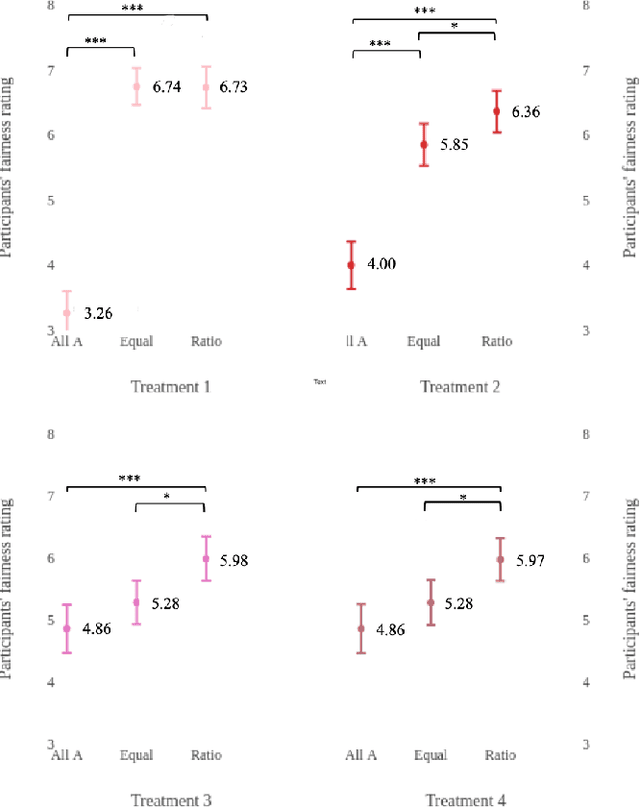
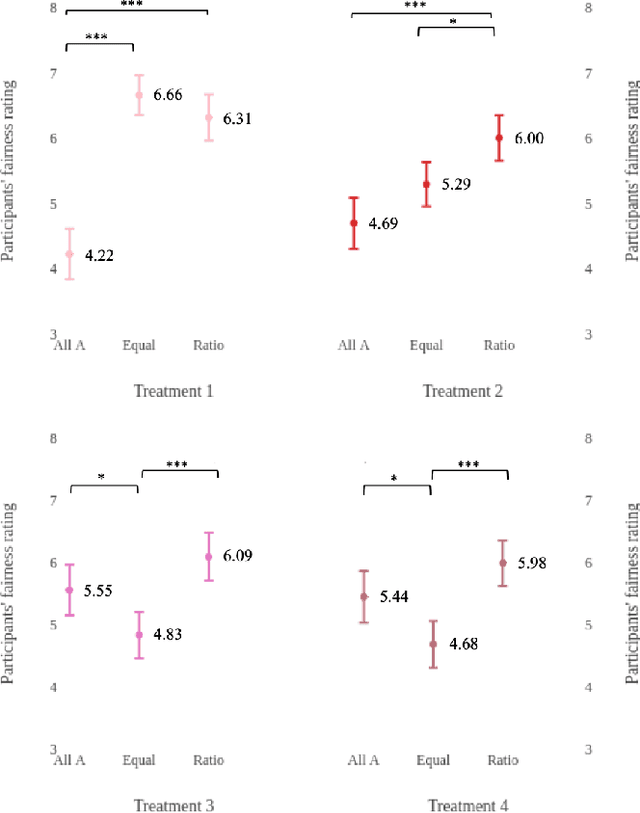

What is the best way to define algorithmic fairness? There has been much recent debate on algorithmic fairness. While many definitions of fairness have been proposed in the computer science literature, there is no clear agreement over a particular definition. In this work, we investigate ordinary people's perceptions of three of these fairness definitions. Across two online experiments, we test which definitions people perceive to be the fairest in the context of loan decisions, and whether those fairness perceptions change with the addition of sensitive information (i.e., race of the loan applicants). We find a clear preference for one definition, and the general results seem to align with the principle of affirmative action.