 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalized Transformer-based Radio Link Failure Prediction Framework in 5G RANs
Jul 06, 2024



Radio link failure (RLF) prediction system in Radio Access Networks (RANs) is critical for ensuring seamless communication and meeting the stringent requirements of high data rates, low latency, and improved reliability in 5G networks. However, weather conditions such as precipitation, humidity, temperature, and wind impact these communication links. Usually, historical radio link Key Performance Indicators (KPIs) and their surrounding weather station observations are utilized for building learning-based RLF prediction models. However, such models must be capable of learning the spatial weather context in a dynamic RAN and effectively encoding time series KPIs with the weather observation data. Existing works fail to incorporate both of these essential design aspects of the prediction models. This paper fills the gap by proposing GenTrap, a novel RLF prediction framework that introduces a graph neural network (GNN)-based learnable weather effect aggregation module and employs state-of-the-art time series transformer as the temporal feature extractor for radio link failure prediction. The proposed aggregation method of GenTrap can be integrated into any existing prediction model to achieve better performance and generalizability. We evaluate GenTrap on two real-world datasets (rural and urban) with 2.6 million KPI data points and show that GenTrap offers a significantly higher F1-score (0.93 for rural and 0.79 for urban) compared to its counterparts while possessing generalization capability.
End-to-End Answer Chunk Extraction and Ranking for Reading Comprehension
Nov 02, 2016


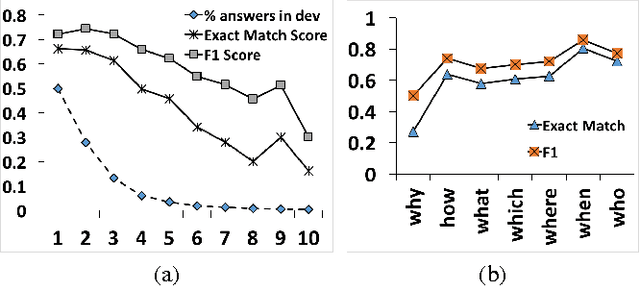
This paper proposes dynamic chunk reader (DCR), an end-to-end neural reading comprehension (RC) model that is able to extract and rank a set of answer candidates from a given document to answer questions. DCR is able to predict answers of variable lengths, whereas previous neural RC models primarily focused on predicting single tokens or entities. DCR encodes a document and an input question with recurrent neural networks, and then applies a word-by-word attention mechanism to acquire question-aware representations for the document, followed by the generation of chunk representations and a ranking module to propose the top-ranked chunk as the answer. Experimental results show that DCR achieves state-of-the-art exact match and F1 scores on the SQuAD dataset.