 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayes and Biased Estimators Without Hyper-parameter Estimation: Comparable Performance to the Empirical-Bayes-Based Regularized Estimator
Mar 14, 2025Regularized system identification has become a significant complement to more classical system identification. It has been numerically shown that kernel-based regularized estimators often perform better than the maximum likelihood estimator in terms of minimizing mean squared error (MSE). However, regularized estimators often require hyper-parameter estimation. This paper focuses on ridge regression and the regularized estimator by employing the empirical Bayes hyper-parameter estimator. We utilize the excess MSE to quantify the MSE difference between the empirical-Bayes-based regularized estimator and the maximum likelihood estimator for large sample sizes. We then exploit the excess MSE expressions to develop both a family of generalized Bayes estimators and a family of closed-form biased estimators. They have the same excess MSE as the empirical-Bayes-based regularized estimator but eliminate the need for hyper-parameter estimation. Moreover, we conduct numerical simulations to show that the performance of these new estimators is comparable to the empirical-Bayes-based regularized estimator, while computationally, they are more efficient.
Robust Federated Finetuning of LLMs via Alternating Optimization of LoRA
Feb 03, 2025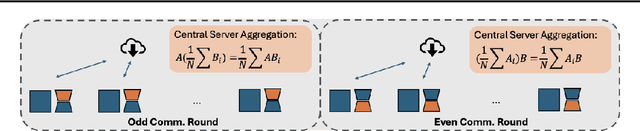
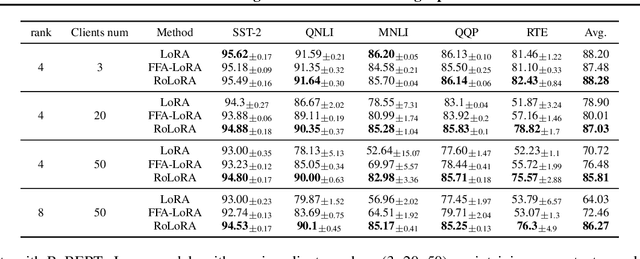
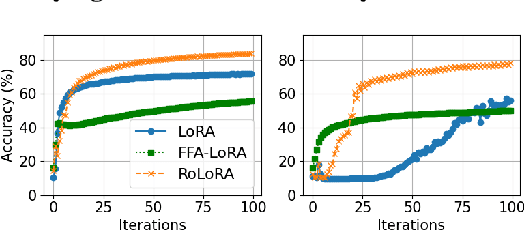

Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA) optimize federated training by reducing computational and communication costs. We propose RoLoRA, a federated framework using alternating optimization to fine-tune LoRA adapters. Our approach emphasizes the importance of learning up and down projection matrices to enhance expressiveness and robustness. We use both theoretical analysis and extensive experiments to demonstrate the advantages of RoLoRA over prior approaches that either generate imperfect model updates or limit expressiveness of the model. We present theoretical analysis on a simplified linear model to demonstrate the importance of learning both down-projection and up-projection matrices in LoRA. We provide extensive experimental evaluations on a toy neural network on MNIST as well as large language models including RoBERTa-Large, Llama-2-7B on diverse tasks to demonstrate the advantages of RoLoRA over other methods.
Robust Federated Finetuning of Foundation Models via Alternating Minimization of LoRA
Sep 04, 2024
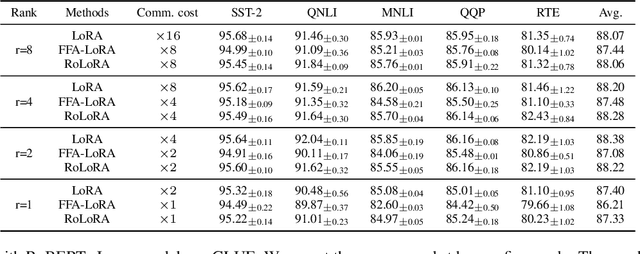
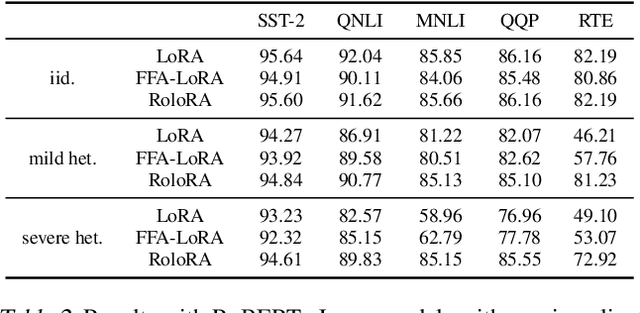

Parameter-Efficient Fine-Tuning (PEFT) has risen as an innovative training strategy that updates only a select few model parameters, significantly lowering both computational and memory demands. PEFT also helps to decrease data transfer in federated learning settings, where communication depends on the size of updates. In this work, we explore the constraints of previous studies that integrate a well-known PEFT method named LoRA with federated fine-tuning, then introduce RoLoRA, a robust federated fine-tuning framework that utilizes an alternating minimization approach for LoRA, providing greater robustness against decreasing fine-tuning parameters and increasing data heterogeneity. Our results indicate that RoLoRA not only presents the communication benefits but also substantially enhances the robustness and effectiveness in multiple federated fine-tuning scenarios.
Root Cause Analysis of Anomalies in 5G RAN Using Graph Neural Network and Transformer
Jun 21, 2024



The emergence of 5G technology marks a significant milestone in developing telecommunication networks, enabling exciting new applications such as augmented reality and self-driving vehicles. However, these improvements bring an increased management complexity and a special concern in dealing with failures, as the applications 5G intends to support heavily rely on high network performance and low latency. Thus, automatic self-healing solutions have become effective in dealing with this requirement, allowing a learning-based system to automatically detect anomalies and perform Root Cause Analysis (RCA). However, there are inherent challenges to the implementation of such intelligent systems. First, there is a lack of suitable data for anomaly detection and RCA, as labelled data for failure scenarios is uncommon. Secondly, current intelligent solutions are tailored to LTE networks and do not fully capture the spatio-temporal characteristics present in the data. Considering this, we utilize a calibrated simulator, Simu5G, and generate open-source data for normal and failure scenarios. Using this data, we propose Simba, a state-of-the-art approach for anomaly detection and root cause analysis in 5G Radio Access Networks (RANs). We leverage Graph Neural Networks to capture spatial relationships while a Transformer model is used to learn the temporal dependencies of the data. We implement a prototype of Simba and evaluate it over multiple failures. The outcomes are compared against existing solutions to confirm the superiority of Simba.
A Calibrated and Automated Simulator for Innovations in 5G
Apr 16, 2024
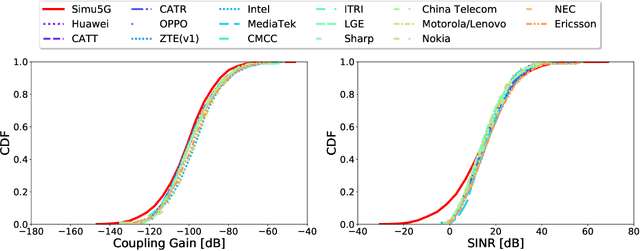
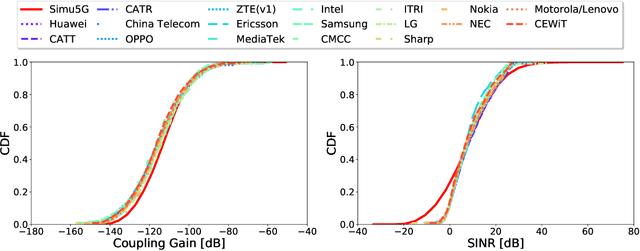
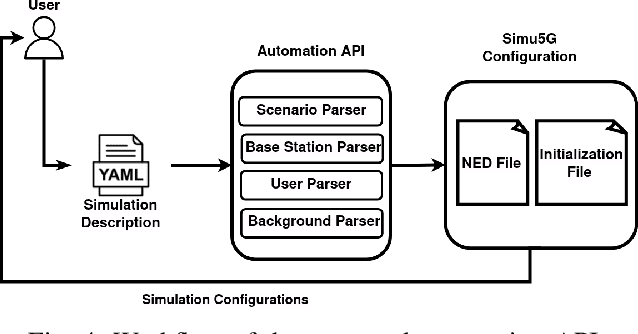
The rise of 5G deployments has created the environment for many emerging technologies to flourish. Self-driving vehicles, Augmented and Virtual Reality, and remote operations are examples of applications that leverage 5G networks' support for extremely low latency, high bandwidth, and increased throughput. However, the complex architecture of 5G hinders innovation due to the lack of accessibility to testbeds or realistic simulators with adequate 5G functionalities. Also, configuring and managing simulators are complex and time consuming. Finally, the lack of adequate representative data hinders the data-driven designs in 5G campaigns. Thus, we calibrated a system-level open-source simulator, Simu5G, following 3GPP guidelines to enable faster innovation in the 5G domain. Furthermore, we developed an API for automatic simulator configuration without knowing the underlying architectural details. Finally, we demonstrate the usage of the calibrated and automated simulator by developing an ML-based anomaly detection in a 5G Radio Access Network (RAN).
ChunkFormer: Learning Long Time Series with Multi-stage Chunked Transformer
Dec 30, 2021

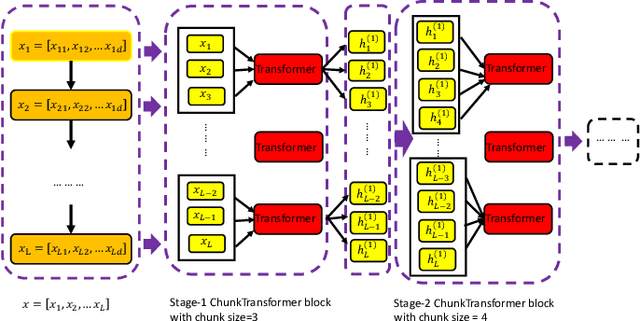
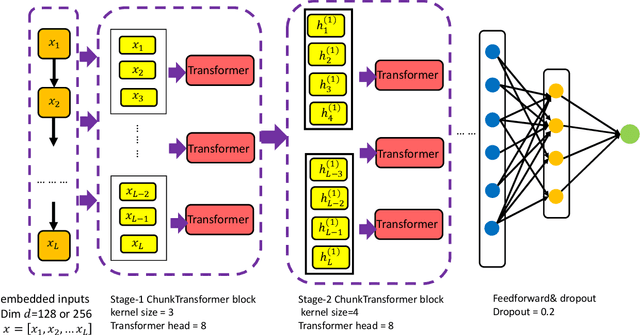
The analysis of long sequence data remains challenging in many real-world applications. We propose a novel architecture, ChunkFormer, that improves the existing Transformer framework to handle the challenges while dealing with long time series. Original Transformer-based models adopt an attention mechanism to discover global information along a sequence to leverage the contextual data. Long sequential data traps local information such as seasonality and fluctuations in short data sequences. In addition, the original Transformer consumes more resources by carrying the entire attention matrix during the training course. To overcome these challenges, ChunkFormer splits the long sequences into smaller sequence chunks for the attention calculation, progressively applying different chunk sizes in each stage. In this way, the proposed model gradually learns both local and global information without changing the total length of the input sequences. We have extensively tested the effectiveness of this new architecture on different business domains and have proved the advantage of such a model over the existing Transformer-based models.