 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunkFormer: Learning Long Time Series with Multi-stage Chunked Transformer
Dec 30, 2021

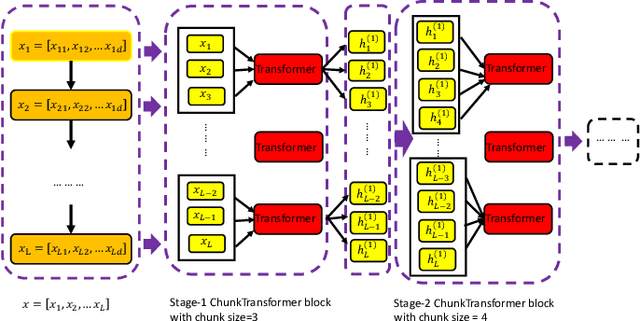
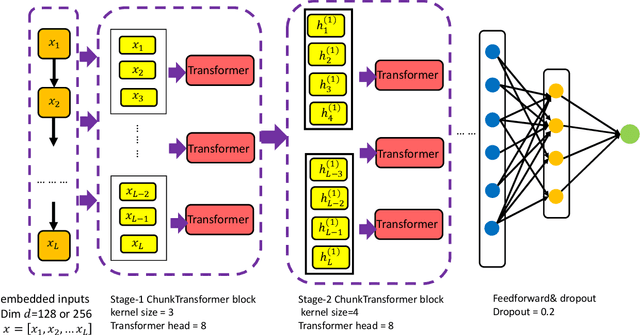
The analysis of long sequence data remains challenging in many real-world applications. We propose a novel architecture, ChunkFormer, that improves the existing Transformer framework to handle the challenges while dealing with long time series. Original Transformer-based models adopt an attention mechanism to discover global information along a sequence to leverage the contextual data. Long sequential data traps local information such as seasonality and fluctuations in short data sequences. In addition, the original Transformer consumes more resources by carrying the entire attention matrix during the training course. To overcome these challenges, ChunkFormer splits the long sequences into smaller sequence chunks for the attention calculation, progressively applying different chunk sizes in each stage. In this way, the proposed model gradually learns both local and global information without changing the total length of the input sequences. We have extensively tested the effectiveness of this new architecture on different business domains and have proved the advantage of such a model over the existing Transformer-based models.
A GRU-based Mixture Density Network for Data-Driven Dynamic Stochastic Programming
Jun 26, 2020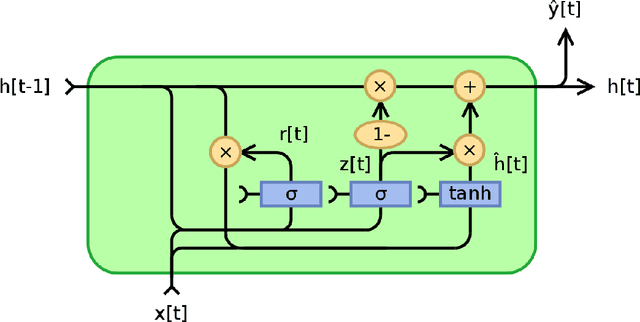

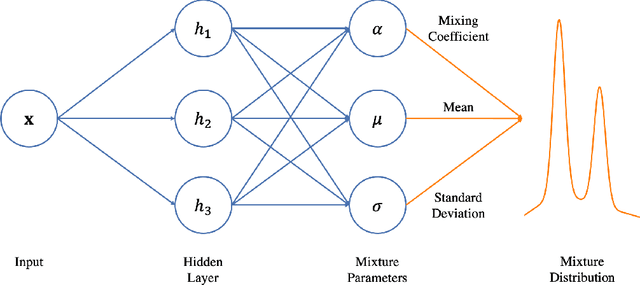

The conventional deep learning approaches for solving time-series problem such as long-short term memory (LSTM) and gated recurrent unit (GRU) both consider the time-series data sequence as the input with one single unit as the output (predicted time-series result). Those deep learning approaches have made tremendous success in many time-series related problems, however, this cannot be applied in data-driven stochastic programming problems since the output of either LSTM or GRU is a scalar rather than probability distribution which is required by stochastic programming model. To fill the gap, in this work, we propose an innovative data-driven dynamic stochastic programming (DD-DSP) framework for time-series decision-making problem, which involves three components: GRU, Gaussian Mixture Model (GMM) and SP. Specifically, we devise the deep neural network that integrates GRU and GMM which is called GRU-based Mixture Density Network (MDN), where GRU is used to predict the time-series outcomes based on the recent historical data, and GMM is used to extract the corresponding probability distribution of predicted outcomes, then the results will be input as the parameters for SP. To validate our approach, we apply the framework on the car-sharing relocation problem. The experiment validations show that our framework is superior to data-driven optimization based on LSTM with the vehicle average moving lower than LSTM.