 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayes and Biased Estimators Without Hyper-parameter Estimation: Comparable Performance to the Empirical-Bayes-Based Regularized Estimator
Mar 14, 2025Regularized system identification has become a significant complement to more classical system identification. It has been numerically shown that kernel-based regularized estimators often perform better than the maximum likelihood estimator in terms of minimizing mean squared error (MSE). However, regularized estimators often require hyper-parameter estimation. This paper focuses on ridge regression and the regularized estimator by employing the empirical Bayes hyper-parameter estimator. We utilize the excess MSE to quantify the MSE difference between the empirical-Bayes-based regularized estimator and the maximum likelihood estimator for large sample sizes. We then exploit the excess MSE expressions to develop both a family of generalized Bayes estimators and a family of closed-form biased estimators. They have the same excess MSE as the empirical-Bayes-based regularized estimator but eliminate the need for hyper-parameter estimation. Moreover, we conduct numerical simulations to show that the performance of these new estimators is comparable to the empirical-Bayes-based regularized estimator, while computationally, they are more efficient.
Meta-Learning Augmented MPC for Disturbance-Aware Motion Planning and Control of Quadrotors
Oct 08, 2024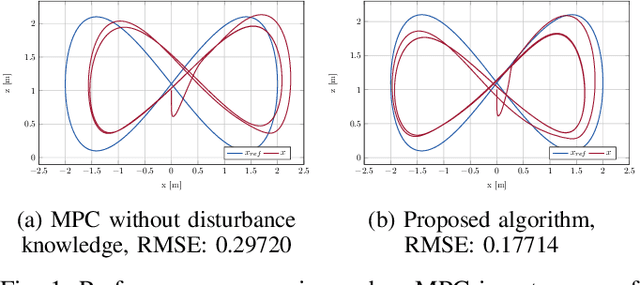
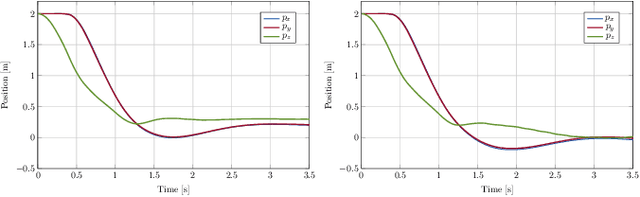
A major challenge in autonomous flights is unknown disturbances, which can jeopardize safety and lead to collisions, especially in obstacle-rich environments. This paper presents a disturbance-aware motion planning and control framework designed for autonomous aerial flights. The framework is composed of two key components: a disturbance-aware motion planner and a tracking controller. The disturbance-aware motion planner consists of a predictive control scheme and a learned model of disturbances that is adapted online. The tracking controller is designed using contraction control methods to provide safety bounds on the quadrotor behaviour in the vicinity of the obstacles with respect to the disturbance-aware motion plan. Finally, the algorithm is tested in simulation scenarios with a quadrotor facing strong crosswind and ground-induced disturbances.
Kinodynamic Motion Planning via Funnel Control for Underactuated Unmanned Surface Vehicles
Jul 31, 2023
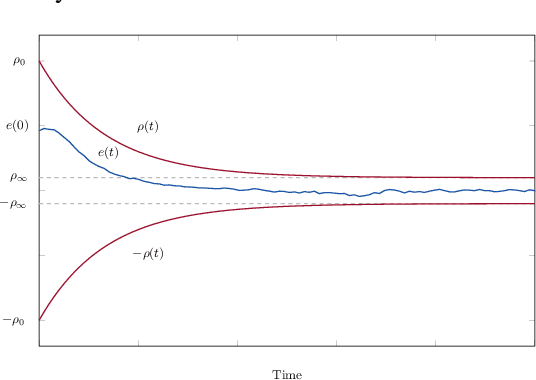
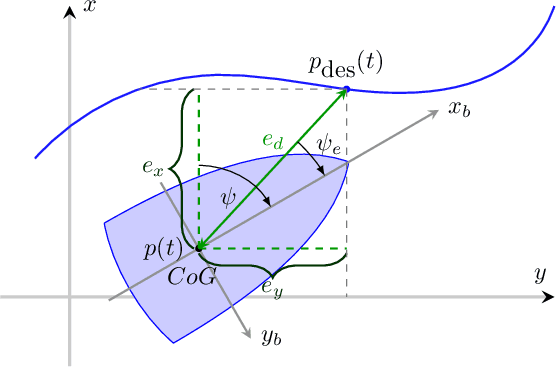
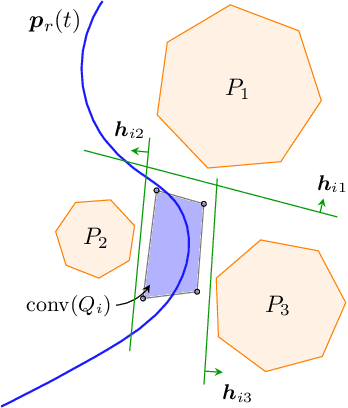
We develop an algorithm to control an underactuated unmanned surface vehicle (USV) using kinodynamic motion planning with funnel control (KDF). KDF has two key components: motion planning used to generate trajectories with respect to kinodynamic constraints, and funnel control, also referred to as prescribed performance control, which enables trajectory tracking in the presence of uncertain dynamics and disturbances. We extend prescribed performance control to address the challenges posed by underactuation and control-input saturation present on the USV. The proposed scheme guarantees stability under user-defined prescribed performance functions where model parameters and exogenous disturbances are unknown. Furthermore, we present an optimization problem to obtain smooth, collision-free trajectories while respecting kinodynamic constraints. We deploy the algorithm on a USV and verify its efficiency in real-world open-water experiments.
Diagnosing and Augmenting Feature Representations in Correctional Inverse Reinforcement Learning
Apr 13, 2023



Robots have been increasingly better at doing tasks for humans by learning from their feedback, but still often suffer from model misalignment due to missing or incorrectly learned features. When the features the robot needs to learn to perform its task are missing or do not generalize well to new settings, the robot will not be able to learn the task the human wants and, even worse, may learn a completely different and undesired behavior. Prior work shows how the robot can detect when its representation is missing some feature and can, thus, ask the human to be taught about the new feature; however, these works do not differentiate between features that are completely missing and those that exist but do not generalize to new environments. In the latter case, the robot would detect misalignment and simply learn a new feature, leading to an arbitrarily growing feature representation that can, in turn, lead to spurious correlations and incorrect learning down the line. In this work, we propose separating the two sources of misalignment: we propose a framework for determining whether a feature the robot needs is incorrectly learned and does not generalize to new environment setups vs. is entirely missing from the robot's representation. Once we detect the source of error, we show how the human can initiate the realignment process for the model: if the feature is missing, we follow prior work for learning new features; however, if the feature exists but does not generalize, we use data augmentation to expand its training and, thus, complete the correction. We demonstrate the proposed approach in experiments with a simulated 7DoF robot manipulator and physical human corrections.
Optimal Transport for Correctional Learning
Apr 04, 2023


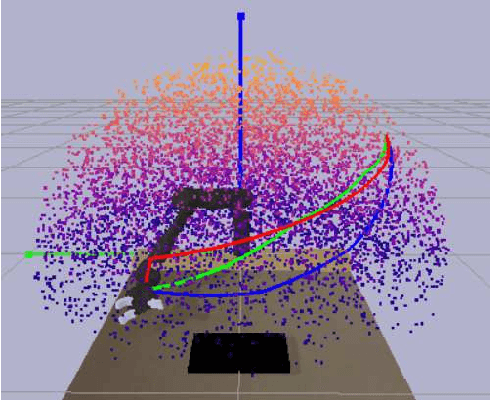
The contribution of this paper is a generalized formulation of correctional learning using optimal transport, which is about how to optimally transport one mass distribution to another. Correctional learning is a framework developed to enhance the accuracy of parameter estimation processes by means of a teacher-student approach. In this framework, an expert agent, referred to as the teacher, modifies the data used by a learning agent, known as the student, to improve its estimation process. The objective of the teacher is to alter the data such that the student's estimation error is minimized, subject to a fixed intervention budget. Compared to existing formulations of correctional learning, our novel optimal transport approach provides several benefits. It allows for the estimation of more complex characteristics as well as the consideration of multiple intervention policies for the teacher. We evaluate our approach on two theoretical examples, and on a human-robot interaction application in which the teacher's role is to improve the robots performance in an inverse reinforcement learning setting.
Prediction-Based Leader-Follower Rendezvous Model Predictive Control with Robustness to Communication Losses
Apr 03, 2023



In this paper we propose a novel distributed model predictive control (DMPC) based algorithm with a trajectory predictor for a scenario of landing of unmanned aerial vehicles (UAVs) on a moving unmanned surface vehicle (USV). The algorithm is executing DMPC with exchange of trajectories between the agents at a sufficient rate. In the case of loss of communication, and given the sensor setup, agents are predicting the trajectories of other agents based on the available measurements and prior information. The predictions are then used as the reference inputs to DMPC. During the landing, the followers are tasked with avoidance of USV-dependent obstacles and inter-agent collisions. In the proposed distributed algorithm, all agents solve their local optimization problem in parallel and we prove the convergence of the proposed algorithm. Finally, the simulation results support the theoretical findings.
Interaction and Decision Making-aware Motion Planning using Branch Model Predictive Control
Jan 31, 2023



Motion planning for autonomous vehicles sharing the road with human drivers remains challenging. The difficulty arises from three challenging aspects: human drivers are 1) multi-modal, 2) interacting with the autonomous vehicle, and 3) actively making decisions based on the current state of the traffic scene. We propose a motion planning framework based on Branch Model Predictive Control to deal with these challenges. The multi-modality is addressed by considering multiple future outcomes associated with different decisions taken by the human driver. The interactive nature of humans is considered by modeling them as reactive agents impacted by the actions of the autonomous vehicle. Finally, we consider a model developed in human neuroscience studies as a possible way of encoding the decision making process of human drivers. We present simulation results in various scenarios, showing the advantages of the proposed method and its ability to plan assertive maneuvers that convey intent to humans.
A teacher-student framework for online correctional learning
Nov 15, 2021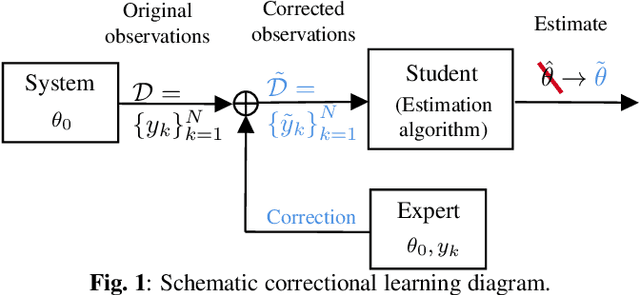
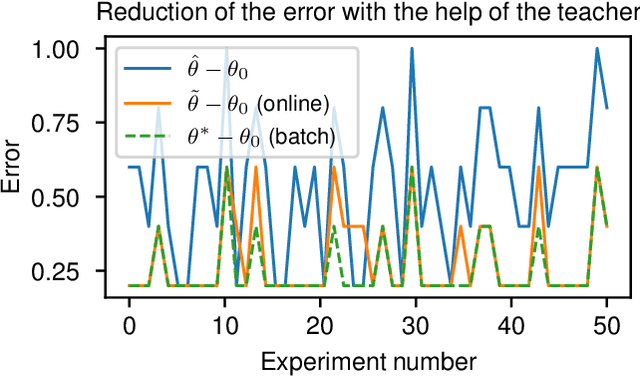
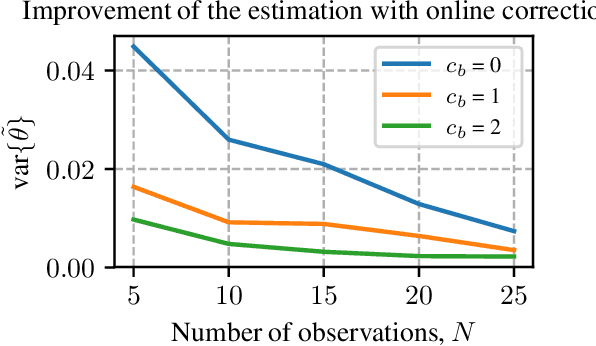
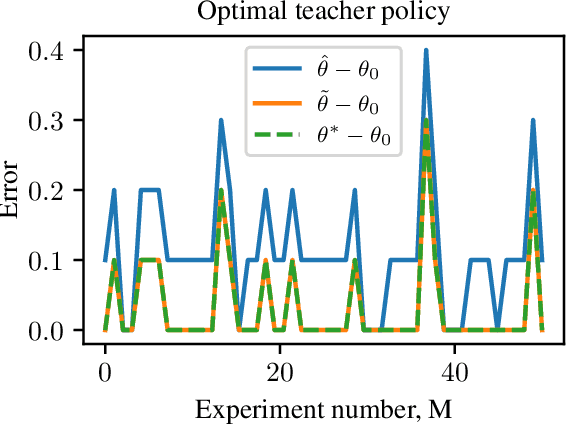
A classical learning setting is one in which a student collects data, or observations, about a system, and estimates a certain quantity of interest about it. Correctional learning is a type of cooperative teacher-student framework where a teacher, who has knowledge about the system, has the possibility to observe and alter (correct) the observations received by the student in order to improve its estimation. In this paper, we show that the variance of the estimate of the student is reduced with the help of the teacher. We further formulate the online problem - where the teacher has to decide at each time instant whether or not to change the observations - as a Markov decision process, from which the optimal policy is derived using dynamic programming. We validate the framework in numerical experiments, and compare the optimal online policy with the one from the batch setting.
A Geometric Approach to On-road Motion Planning for Long and Multi-Body Heavy-Duty Vehicles
Oct 15, 2020
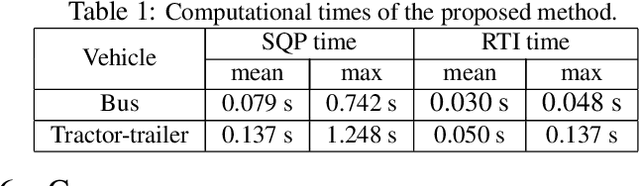
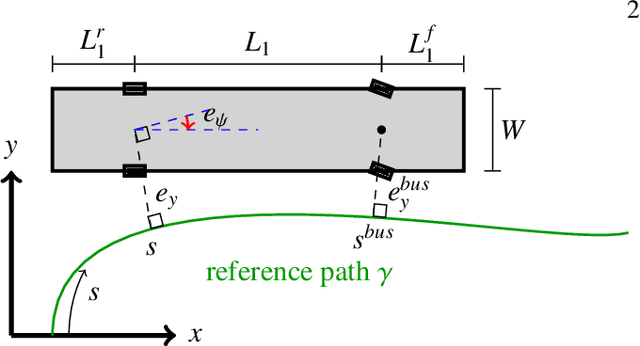
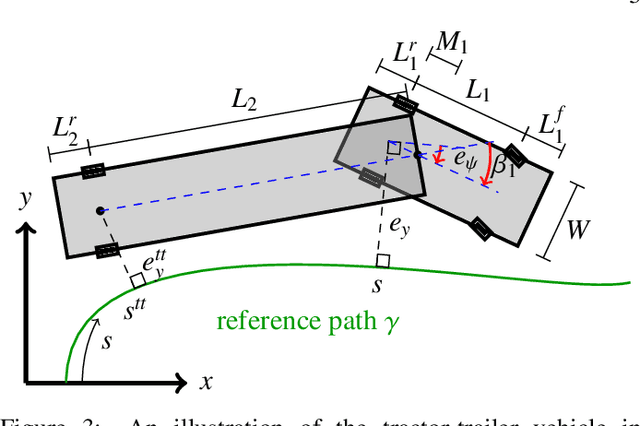
Driving heavy-duty vehicles, such as buses and tractor-trailer vehicles, is a difficult task in comparison to passenger cars. Most research on motion planning for autonomous vehicles has focused on passenger vehicles, and many unique challenges associated with heavy-duty vehicles remain open. However, recent works have started to tackle the particular difficulties related to on-road motion planning for buses and tractor-trailer vehicles using numerical optimization approaches. In this work, we propose a framework to design an optimization objective to be used in motion planners. Based on geometric derivations, the method finds the optimal trade-off between the conflicting objectives of centering different axles of the vehicle in the lane. For the buses, we consider the front and rear axles trade-off, whereas for articulated vehicles, we consider the tractor and trailer rear axles trade-off. Our results show that the proposed design strategy results in planned paths that considerably improve the behavior of heavy-duty vehicles by keeping the whole vehicle body in the center of the lane.
Learning the Step-size Policy for the Limited-Memory Broyden-Fletcher-Goldfarb-Shanno Algorithm
Oct 03, 2020
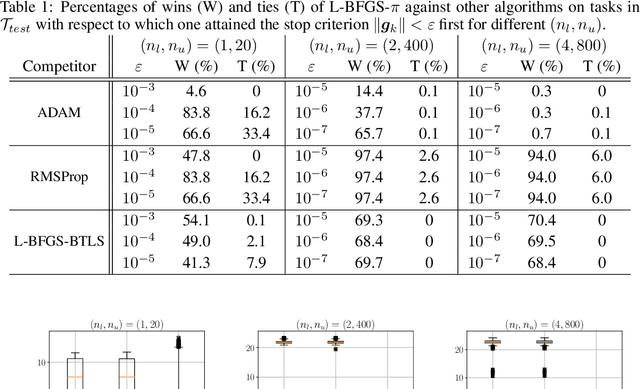
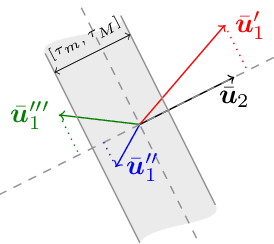
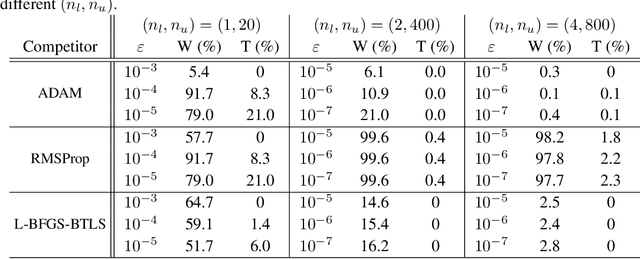
We consider the problem of how to learn a step-size policy for the Limited-Memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) algorithm. This is a limited computational memory quasi-Newton method widely used for deterministic unconstrained optimization but currently avoided in large-scale problems for requiring step sizes to be provided at each iteration. Existing methodologies for the step size selection for L-BFGS use heuristic tuning of design parameters and massive re-evaluations of the objective function and gradient to find appropriate step-lengths. We propose a neural network architecture with local information of the current iterate as the input. The step-length policy is learned from data of similar optimization problems, avoids additional evaluations of the objective function, and guarantees that the output step remains inside a pre-defined interval. The corresponding training procedure is formulated as a stochastic optimization problem using the backpropagation through time algorithm. The performance of the proposed method is evaluated on the MNIST database for handwritten digits. The results show that the proposed algorithm outperforms heuristically tuned optimizers such as ADAM and RMSprop in terms of computational time. It performs comparably to more computationally demanding L-BFGS with backtracking line search. The numerical results also show that the learned policy generalizes better to high-dimensional problems as compared to ADAM and RMSprop, highlighting its potential use in large-scale optimization.