 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing and Augmenting Feature Representations in Correctional Inverse Reinforcement Learning
Apr 13, 2023



Robots have been increasingly better at doing tasks for humans by learning from their feedback, but still often suffer from model misalignment due to missing or incorrectly learned features. When the features the robot needs to learn to perform its task are missing or do not generalize well to new settings, the robot will not be able to learn the task the human wants and, even worse, may learn a completely different and undesired behavior. Prior work shows how the robot can detect when its representation is missing some feature and can, thus, ask the human to be taught about the new feature; however, these works do not differentiate between features that are completely missing and those that exist but do not generalize to new environments. In the latter case, the robot would detect misalignment and simply learn a new feature, leading to an arbitrarily growing feature representation that can, in turn, lead to spurious correlations and incorrect learning down the line. In this work, we propose separating the two sources of misalignment: we propose a framework for determining whether a feature the robot needs is incorrectly learned and does not generalize to new environment setups vs. is entirely missing from the robot's representation. Once we detect the source of error, we show how the human can initiate the realignment process for the model: if the feature is missing, we follow prior work for learning new features; however, if the feature exists but does not generalize, we use data augmentation to expand its training and, thus, complete the correction. We demonstrate the proposed approach in experiments with a simulated 7DoF robot manipulator and physical human corrections.
A teacher-student framework for online correctional learning
Nov 15, 2021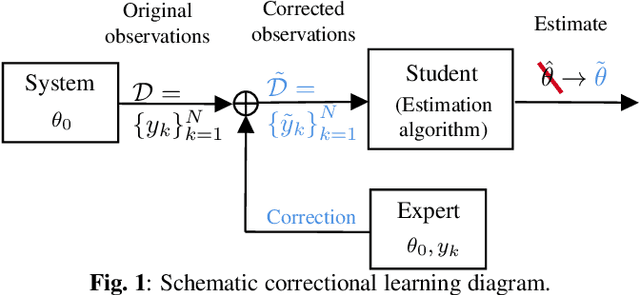
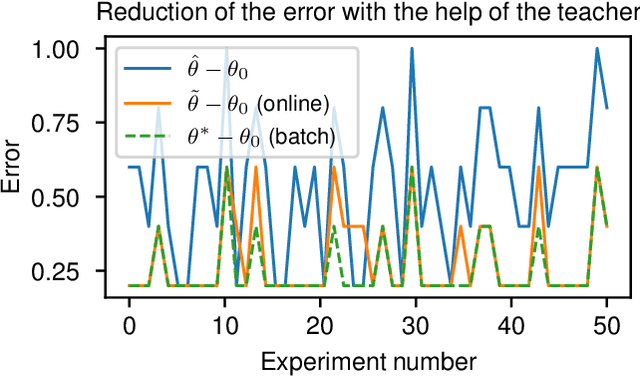
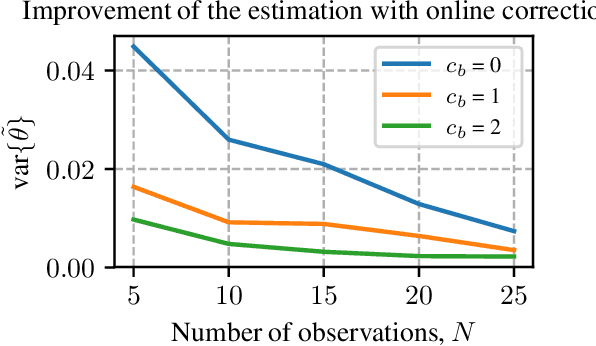
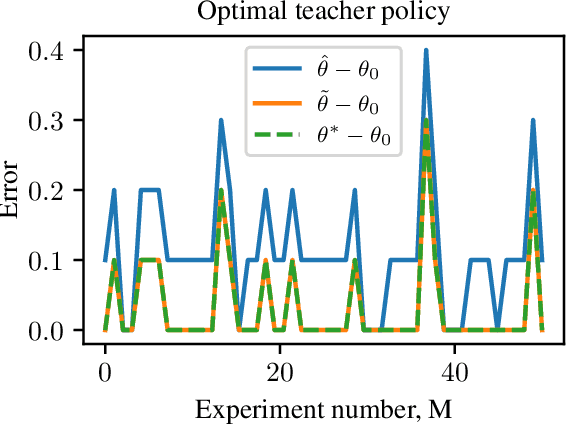
A classical learning setting is one in which a student collects data, or observations, about a system, and estimates a certain quantity of interest about it. Correctional learning is a type of cooperative teacher-student framework where a teacher, who has knowledge about the system, has the possibility to observe and alter (correct) the observations received by the student in order to improve its estimation. In this paper, we show that the variance of the estimate of the student is reduced with the help of the teacher. We further formulate the online problem - where the teacher has to decide at each time instant whether or not to change the observations - as a Markov decision process, from which the optimal policy is derived using dynamic programming. We validate the framework in numerical experiments, and compare the optimal online policy with the one from the batch setting.
Teaching robots to perceive time -- A reinforcement learning approach (Extended version)
Dec 20, 2019
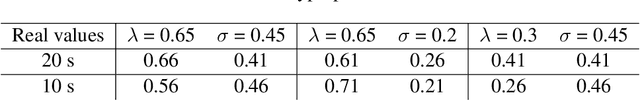
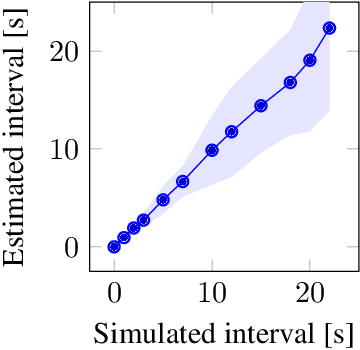
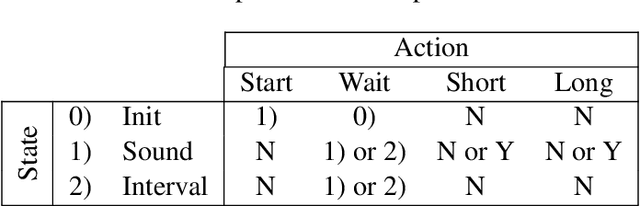
Time perception is the phenomenological experience of time by an individual. In this paper, we study how to replicate neural mechanisms involved in time perception, allowing robots to take a step towards temporal cognition. Our framework follows a twofold biologically inspired approach. The first step consists of estimating the passage of time from sensor measurements, since environmental stimuli influence the perception of time. Sensor data is modeled as Gaussian processes that represent the second-order statistics of the natural environment. The estimated elapsed time between two events is computed from the maximum likelihood estimate of the joint distribution of the data collected between them. Moreover, exactly how time is encoded in the brain remains unknown, but there is strong evidence of the involvement of dopaminergic neurons in timing mechanisms. Since their phasic activity has a similar behavior to the reward prediction error of temporal-difference learning models, the latter are used to replicate this behavior. The second step of this approach consists therefore of applying the agent's estimate of the elapsed time in a reinforcement learning problem, where a feature representation called Microstimuli is used. We validate our framework by applying it to an experiment that was originally conducted with mice, and conclude that a robot using this framework is able to reproduce the timing mechanisms of the animal's brain.