 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Federated Finetuning of LLMs via Alternating Optimization of LoRA
Feb 03, 2025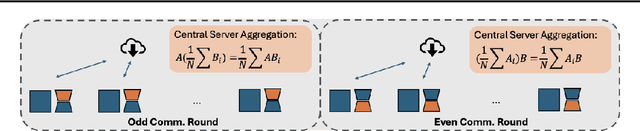
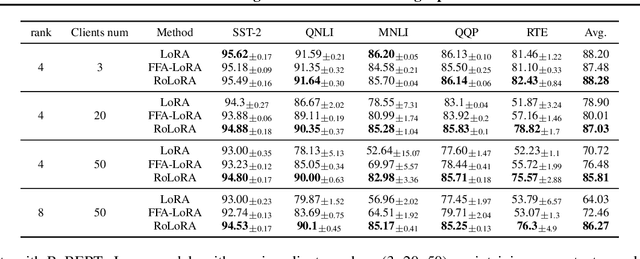
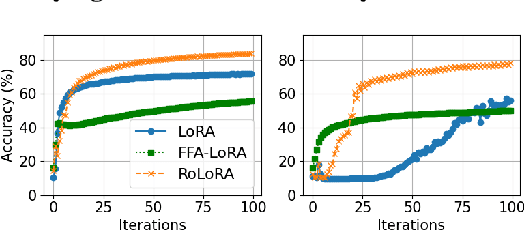

Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA) optimize federated training by reducing computational and communication costs. We propose RoLoRA, a federated framework using alternating optimization to fine-tune LoRA adapters. Our approach emphasizes the importance of learning up and down projection matrices to enhance expressiveness and robustness. We use both theoretical analysis and extensive experiments to demonstrate the advantages of RoLoRA over prior approaches that either generate imperfect model updates or limit expressiveness of the model. We present theoretical analysis on a simplified linear model to demonstrate the importance of learning both down-projection and up-projection matrices in LoRA. We provide extensive experimental evaluations on a toy neural network on MNIST as well as large language models including RoBERTa-Large, Llama-2-7B on diverse tasks to demonstrate the advantages of RoLoRA over other methods.
Robust Federated Finetuning of Foundation Models via Alternating Minimization of LoRA
Sep 04, 2024
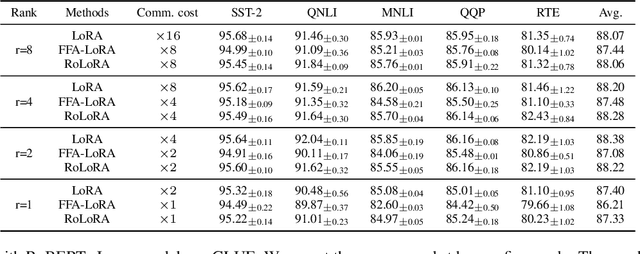
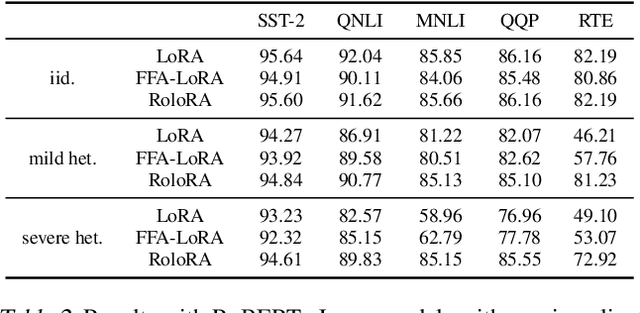

Parameter-Efficient Fine-Tuning (PEFT) has risen as an innovative training strategy that updates only a select few model parameters, significantly lowering both computational and memory demands. PEFT also helps to decrease data transfer in federated learning settings, where communication depends on the size of updates. In this work, we explore the constraints of previous studies that integrate a well-known PEFT method named LoRA with federated fine-tuning, then introduce RoLoRA, a robust federated fine-tuning framework that utilizes an alternating minimization approach for LoRA, providing greater robustness against decreasing fine-tuning parameters and increasing data heterogeneity. Our results indicate that RoLoRA not only presents the communication benefits but also substantially enhances the robustness and effectiveness in multiple federated fine-tuning scenarios.
Quadratic Functional Encryption for Secure Training in Vertical Federated Learning
May 15, 2023


Vertical federated learning (VFL) enables the collaborative training of machine learning (ML) models in settings where the data is distributed amongst multiple parties who wish to protect the privacy of their individual data. Notably, in VFL, the labels are available to a single party and the complete feature set is formed only when data from all parties is combined. Recently, Xu et al. proposed a new framework called FedV for secure gradient computation for VFL using multi-input functional encryption. In this work, we explain how some of the information leakage in Xu et al. can be avoided by using Quadratic functional encryption when training generalized linear models for vertical federated learning.