 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Visual Understanding with Cognitive Attention Network
Paper and Code
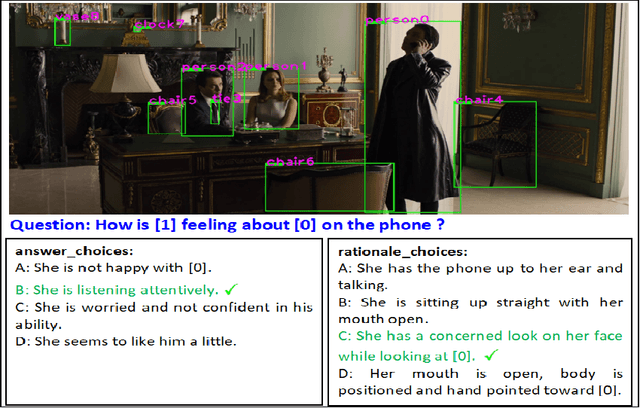
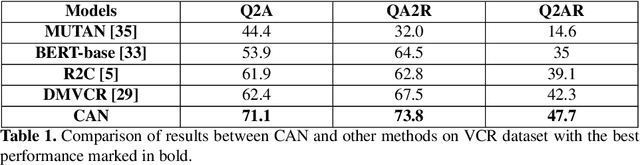
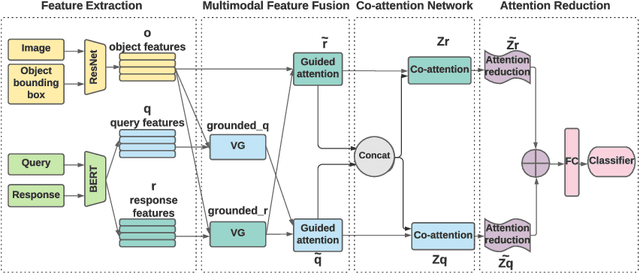
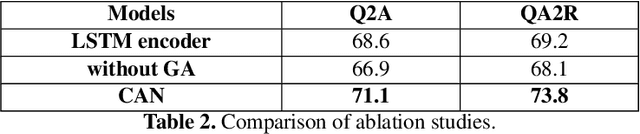
While image understanding on recognition-level has achieved remarkable advancements, reliable visual scene understanding requires comprehensive image understanding on recognition-level but also cognition-level, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge. In this paper, we propose a novel Cognitive Attention Network (CAN) for visual commonsense reasoning to achieve interpretable visual understanding. Specifically, we first introduce an image-text fusion module to fuse information from images and text collectively. Second, a novel inference module is designed to encode commonsense among image, query and response. Extensive experiments on large-scale Visual Commonsense Reasoning (VCR) benchmark dataset demonstrate the effectiveness of our approach. The implementation is publicly available at https://github.com/tanjatang/CAN