 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Disparity-Accuracy Trade-offs in Face Recognition Systems: The Role of Datasets, Architectures, and Loss Functions
Mar 18, 2025Automated Face Recognition Systems (FRSs), developed using deep learning models, are deployed worldwide for identity verification and facial attribute analysis. The performance of these models is determined by a complex interdependence among the model architecture, optimization/loss function and datasets. Although FRSs have surpassed human-level accuracy, they continue to be disparate against certain demographics. Due to the ubiquity of applications, it is extremely important to understand the impact of the three components -- model architecture, loss function and face image dataset on the accuracy-disparity trade-off to design better, unbiased platforms. In this work, we perform an in-depth analysis of three FRSs for the task of gender prediction, with various architectural modifications resulting in ten deep-learning models coupled with four loss functions and benchmark them on seven face datasets across 266 evaluation configurations. Our results show that all three components have an individual as well as a combined impact on both accuracy and disparity. We identify that datasets have an inherent property that causes them to perform similarly across models, independent of the choice of loss functions. Moreover, the choice of dataset determines the model's perceived bias -- the same model reports bias in opposite directions for three gender-balanced datasets of ``in-the-wild'' face images of popular individuals. Studying the facial embeddings shows that the models are unable to generalize a uniform definition of what constitutes a ``female face'' as opposed to a ``male face'', due to dataset diversity. We provide recommendations to model developers on using our study as a blueprint for model development and subsequent deployment.
Recommendation Fairness in Social Networks Over Time
Feb 05, 2024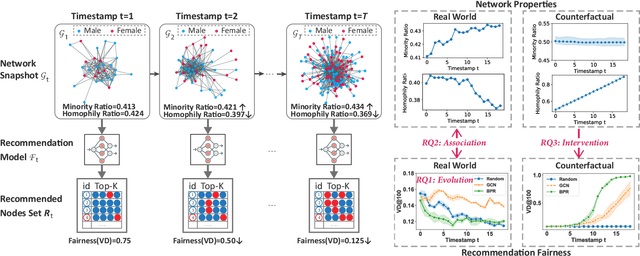
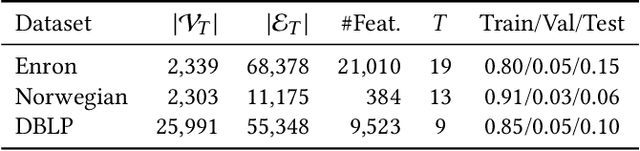
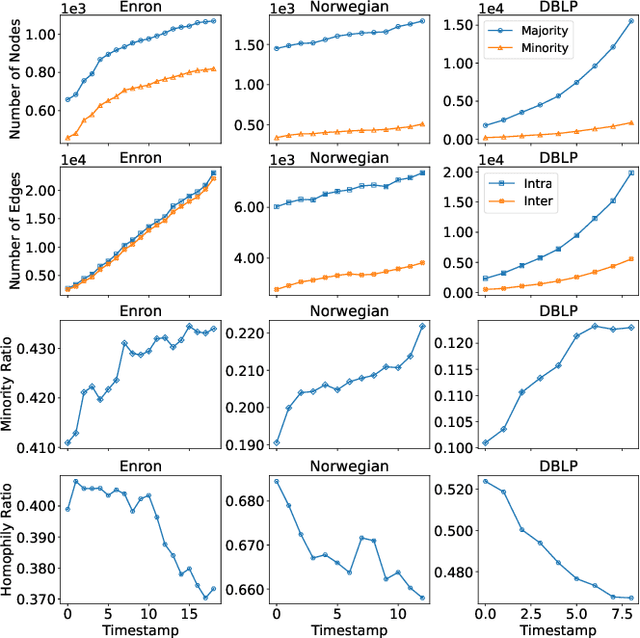
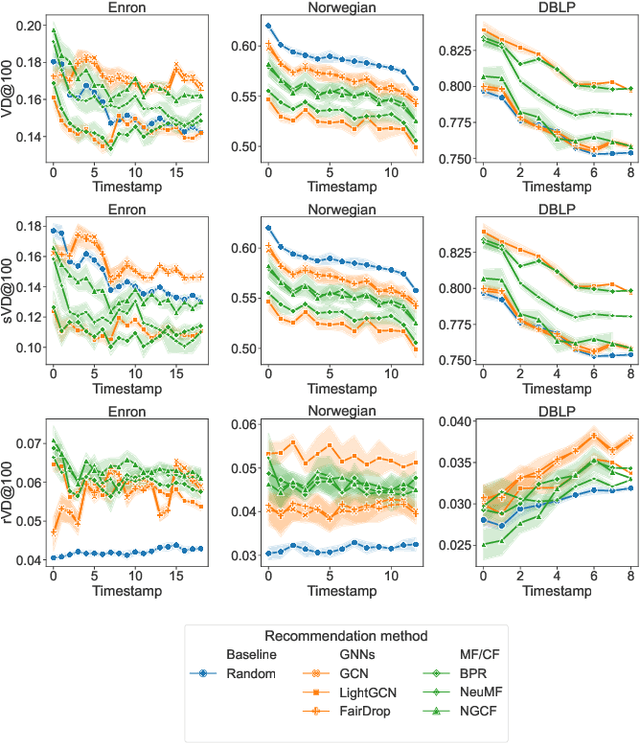
In social recommender systems, it is crucial that the recommendation models provide equitable visibility for different demographic groups, such as gender or race. Most existing research has addressed this problem by only studying individual static snapshots of networks that typically change over time. To address this gap, we study the evolution of recommendation fairness over time and its relation to dynamic network properties. We examine three real-world dynamic networks by evaluating the fairness of six recommendation algorithms and analyzing the association between fairness and network properties over time. We further study how interventions on network properties influence fairness by examining counterfactual scenarios with alternative evolution outcomes and differing network properties. Our results on empirical datasets suggest that recommendation fairness improves over time, regardless of the recommendation method. We also find that two network properties, minority ratio, and homophily ratio, exhibit stable correlations with fairness over time. Our counterfactual study further suggests that an extreme homophily ratio potentially contributes to unfair recommendations even with a balanced minority ratio. Our work provides insights into the evolution of fairness within dynamic networks in social science. We believe that our findings will help system operators and policymakers to better comprehend the implications of temporal changes and interventions targeting fairness in social networks.
IVP-VAE: Modeling EHR Time Series with Initial Value Problem Solvers
May 11, 2023Continuous-time models such as Neural ODEs and Neural Flows have shown promising results in analyzing irregularly sampled time series frequently encountered in electronic health records. Based on these models, time series are typically processed with a hybrid of an initial value problem (IVP) solver and a recurrent neural network within the variational autoencoder architecture. Sequentially solving IVPs makes such models computationally less efficient. In this paper, we propose to model time series purely with continuous processes whose state evolution can be approximated directly by IVPs. This eliminates the need for recurrent computation and enables multiple states to evolve in parallel. We further fuse the encoder and decoder with one IVP solver based on its invertibility, which leads to fewer parameters and faster convergence. Experiments on three real-world datasets show that the proposed approach achieves comparable extrapolation and classification performance while gaining more than one order of magnitude speedup over other continuous-time counterparts.
A Review of the Role of Causality in Developing Trustworthy AI Systems
Feb 14, 2023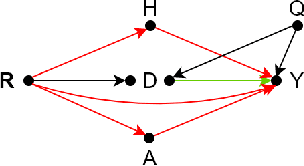
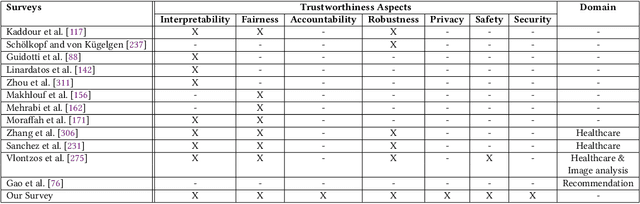
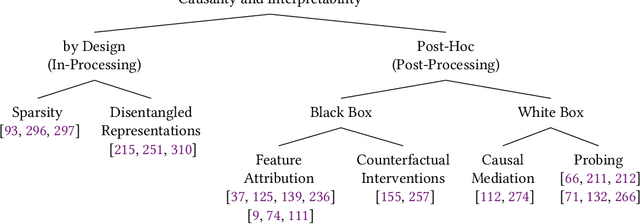
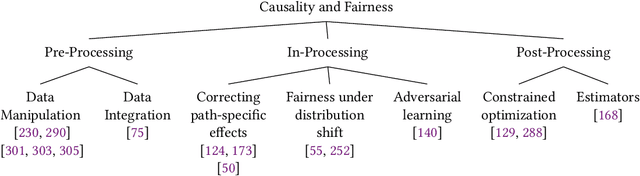
State-of-the-art AI models largely lack an understanding of the cause-effect relationship that governs human understanding of the real world. Consequently, these models do not generalize to unseen data, often produce unfair results, and are difficult to interpret. This has led to efforts to improve the trustworthiness aspects of AI models. Recently, causal modeling and inference methods have emerged as powerful tools. This review aims to provide the reader with an overview of causal methods that have been developed to improve the trustworthiness of AI models. We hope that our contribution will motivate future research on causality-based solutions for trustworthy AI.
SensePOLAR: Word sense aware interpretability for pre-trained contextual word embeddings
Jan 11, 2023Adding interpretability to word embeddings represents an area of active research in text representation. Recent work has explored thepotential of embedding words via so-called polar dimensions (e.g. good vs. bad, correct vs. wrong). Examples of such recent approaches include SemAxis, POLAR, FrameAxis, and BiImp. Although these approaches provide interpretable dimensions for words, they have not been designed to deal with polysemy, i.e. they can not easily distinguish between different senses of words. To address this limitation, we present SensePOLAR, an extension of the original POLAR framework that enables word-sense aware interpretability for pre-trained contextual word embeddings. The resulting interpretable word embeddings achieve a level of performance that is comparable to original contextual word embeddings across a variety of natural language processing tasks including the GLUE and SQuAD benchmarks. Our work removes a fundamental limitation of existing approaches by offering users sense aware interpretations for contextual word embeddings.
Properties of Group Fairness Metrics for Rankings
Dec 29, 2022In recent years, several metrics have been developed for evaluating group fairness of rankings. Given that these metrics were developed with different application contexts and ranking algorithms in mind, it is not straightforward which metric to choose for a given scenario. In this paper, we perform a comprehensive comparative analysis of existing group fairness metrics developed in the context of fair ranking. By virtue of their diverse application contexts, we argue that such a comparative analysis is not straightforward. Hence, we take an axiomatic approach whereby we design a set of thirteen properties for group fairness metrics that consider different ranking settings. A metric can then be selected depending on whether it satisfies all or a subset of these properties. We apply these properties on eleven existing group fairness metrics, and through both empirical and theoretical results we demonstrate that most of these metrics only satisfy a small subset of the proposed properties. These findings highlight limitations of existing metrics, and provide insights into how to evaluate and interpret different fairness metrics in practical deployment. The proposed properties can also assist practitioners in selecting appropriate metrics for evaluating fairness in a specific application.
Adversarial Inter-Group Link Injection Degrades the Fairness of Graph Neural Networks
Sep 13, 2022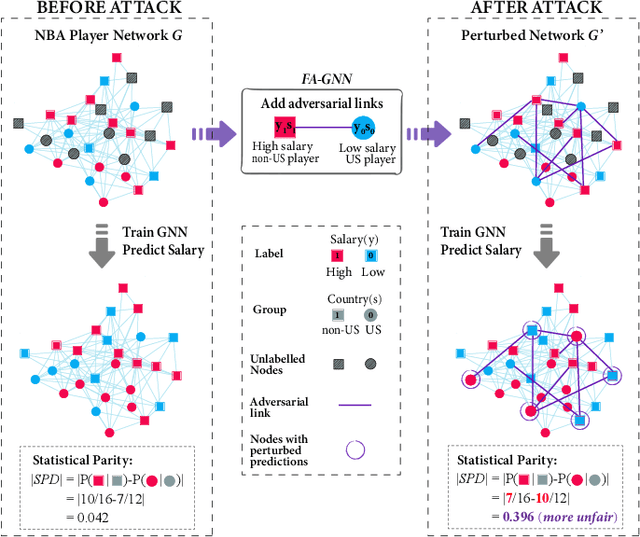
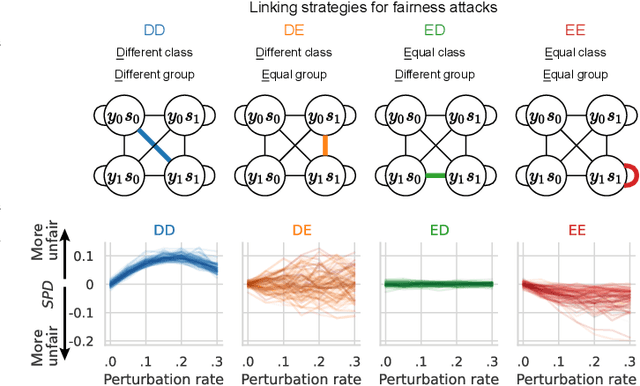
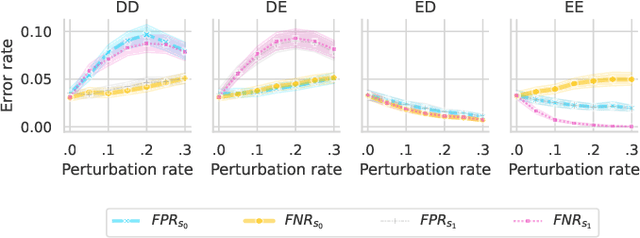
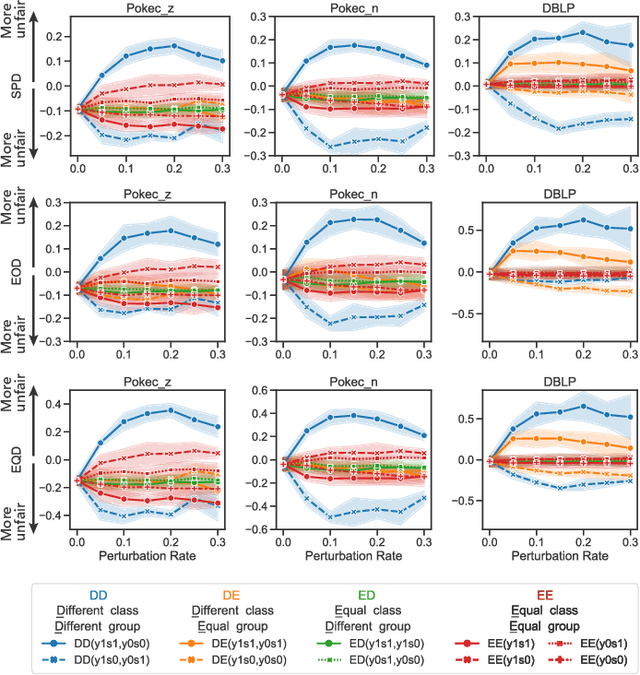
We present evidence for the existence and effectiveness of adversarial attacks on graph neural networks (GNNs) that aim to degrade fairness. These attacks can disadvantage a particular subgroup of nodes in GNN-based node classification, where nodes of the underlying network have sensitive attributes, such as race or gender. We conduct qualitative and experimental analyses explaining how adversarial link injection impairs the fairness of GNN predictions. For example, an attacker can compromise the fairness of GNN-based node classification by injecting adversarial links between nodes belonging to opposite subgroups and opposite class labels. Our experiments on empirical datasets demonstrate that adversarial fairness attacks can significantly degrade the fairness of GNN predictions (attacks are effective) with a low perturbation rate (attacks are efficient) and without a significant drop in accuracy (attacks are deceptive). This work demonstrates the vulnerability of GNN models to adversarial fairness attacks. We hope our findings raise awareness about this issue in our community and lay a foundation for the future development of GNN models that are more robust to such attacks.
The POLAR Framework: Polar Opposites Enable Interpretability of Pre-Trained Word Embeddings
Jan 28, 2020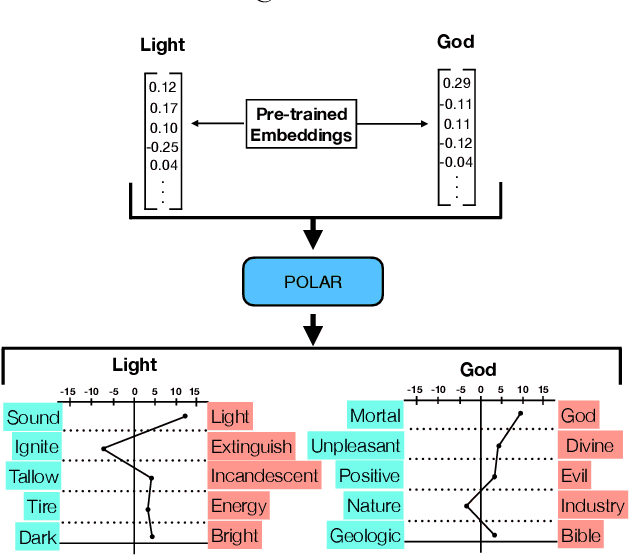



We introduce POLAR - a framework that adds interpretability to pre-trained word embeddings via the adoption of semantic differentials. Semantic differentials are a psychometric construct for measuring the semantics of a word by analysing its position on a scale between two polar opposites (e.g., cold -- hot, soft -- hard). The core idea of our approach is to transform existing, pre-trained word embeddings via semantic differentials to a new "polar" space with interpretable dimensions defined by such polar opposites. Our framework also allows for selecting the most discriminative dimensions from a set of polar dimensions provided by an oracle, i.e., an external source. We demonstrate the effectiveness of our framework by deploying it to various downstream tasks, in which our interpretable word embeddings achieve a performance that is comparable to the original word embeddings. We also show that the interpretable dimensions selected by our framework align with human judgement. Together, these results demonstrate that interpretability can be added to word embeddings without compromising performance. Our work is relevant for researchers and engineers interested in interpreting pre-trained word embeddings.
StRE: Self Attentive Edit Quality Prediction in Wikipedia
Jun 11, 2019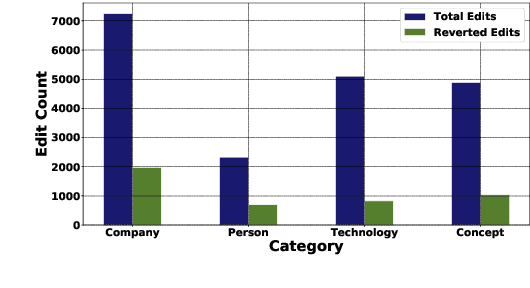

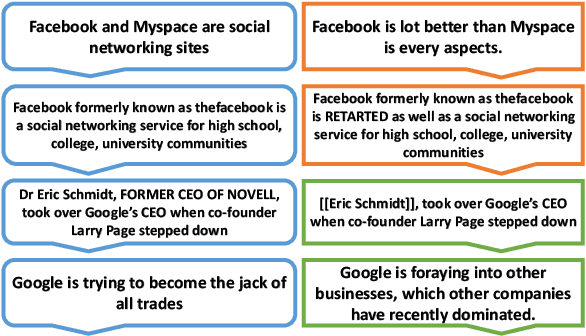
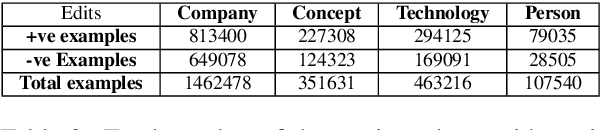
Wikipedia can easily be justified as a behemoth, considering the sheer volume of content that is added or removed every minute to its several projects. This creates an immense scope, in the field of natural language processing towards developing automated tools for content moderation and review. In this paper we propose Self Attentive Revision Encoder (StRE) which leverages orthographic similarity of lexical units toward predicting the quality of new edits. In contrast to existing propositions which primarily employ features like page reputation, editor activity or rule based heuristics, we utilize the textual content of the edits which, we believe contains superior signatures of their quality. More specifically, we deploy deep encoders to generate representations of the edits from its text content, which we then leverage to infer quality. We further contribute a novel dataset containing 21M revisions across 32K Wikipedia pages and demonstrate that StRE outperforms existing methods by a significant margin at least 17% and at most 103%. Our pretrained model achieves such result after retraining on a set as small as 20% of the edits in a wikipage. This, to the best of our knowledge, is also the first attempt towards employing deep language models to the enormous domain of automated content moderation and review in Wikipedia.