 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraQ: Spatiotemporal Question-Answering on Satellite Image Archives
Feb 06, 2025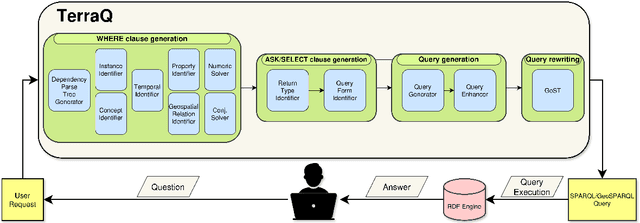
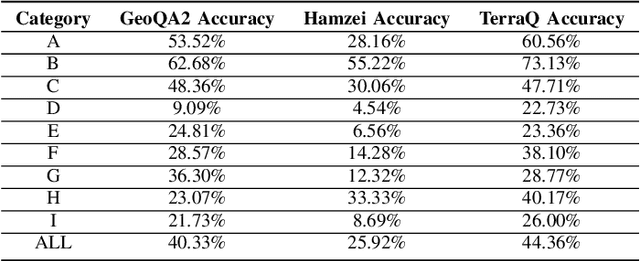
TerraQ is a spatiotemporal question-answering engine for satellite image archives. It is a natural language processing system that is built to process requests for satellite images satisfying certain criteria. The requests can refer to image metadata and entities from a specialized knowledge base (e.g., the Emilia-Romagna region). With it, users can make requests like "Give me a hundred images of rivers near ports in France, with less than 20% snow coverage and more than 10% cloud coverage", thus making Earth Observation data more easily accessible, in-line with the current landscape of digital assistants.
The Large Language Model GreekLegalRoBERTa
Oct 10, 2024



We develop four versions of GreekLegalRoBERTa, which are four large language models trained on Greek legal and nonlegal text. We show that our models surpass the performance of GreekLegalBERT, Greek- LegalBERT-v2, and GreekBERT in two tasks involving Greek legal documents: named entity recognition and multi-class legal topic classification. We view our work as a contribution to the study of domain-specific NLP tasks in low-resource languages, like Greek, using modern NLP techniques and methodologies.
Reasoning over Description Logic-based Contexts with Transformers
Nov 15, 2023



One way that the current state of the art measures the reasoning ability of transformer-based models is by evaluating accuracy in downstream tasks like logical question answering or proof generation over synthetic contexts expressed in natural language. However, most of the contexts used are in practice very simple; in most cases, they are generated from short first-order logic sentences with only a few logical operators and quantifiers. In this work, we seek to answer the question how well a transformer-based model will perform reasoning over expressive contexts. For this purpose, we construct a synthetic natural language question-answering dataset, generated by description logic knowledge bases. For the generation of the knowledge bases, we use the expressive language $\mathcal{ALCQ}$. The resulting dataset contains 384K examples, and increases in two dimensions: i) reasoning depth, and ii) length of sentences. We show that the performance of our DeBERTa-based model, DELTA$_M$, is marginally affected when the reasoning depth is increased and it is not affected at all when the length of the sentences is increasing. We also evaluate the generalization ability of the model on reasoning depths unseen at training, both increasing and decreasing, revealing interesting insights into the model's adaptive generalization abilities.
Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]
Apr 24, 2023![Figure 1 for Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F91317e9bf86ea710fcdbfb3dbb8d1c19c5602182%2F3-Table1-1.png&w=640&q=75)
![Figure 2 for Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F91317e9bf86ea710fcdbfb3dbb8d1c19c5602182%2F6-Figure1-1.png&w=640&q=75)
![Figure 3 for Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F91317e9bf86ea710fcdbfb3dbb8d1c19c5602182%2F4-Table2-1.png&w=640&q=75)
![Figure 4 for Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F91317e9bf86ea710fcdbfb3dbb8d1c19c5602182%2F7-Figure2-1.png&w=640&q=75)
Many recent works on Entity Resolution (ER) leverage Deep Learning techniques involving language models to improve effectiveness. This is applied to both main steps of ER, i.e., blocking and matching. Several pre-trained embeddings have been tested, with the most popular ones being fastText and variants of the BERT model. However, there is no detailed analysis of their pros and cons. To cover this gap, we perform a thorough experimental analysis of 12 popular language models over 17 established benchmark datasets. First, we assess their vectorization overhead for converting all input entities into dense embeddings vectors. Second, we investigate their blocking performance, performing a detailed scalability analysis, and comparing them with the state-of-the-art deep learning-based blocking method. Third, we conclude with their relative performance for both supervised and unsupervised matching. Our experimental results provide novel insights into the strengths and weaknesses of the main language models, facilitating researchers and practitioners to select the most suitable ones in practice.
A Review of the Role of Causality in Developing Trustworthy AI Systems
Feb 14, 2023
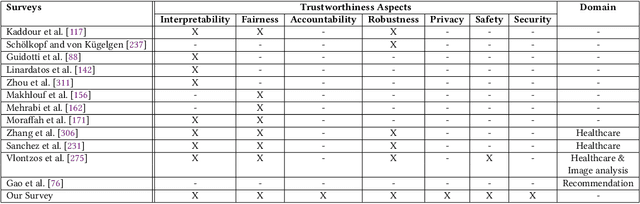
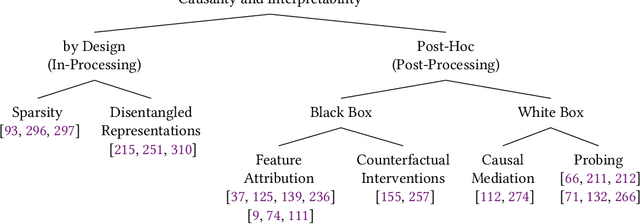
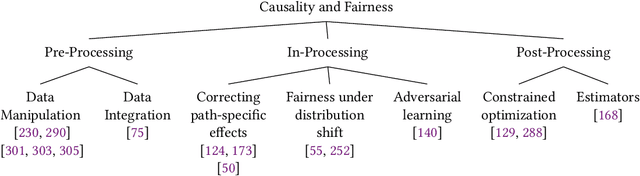
State-of-the-art AI models largely lack an understanding of the cause-effect relationship that governs human understanding of the real world. Consequently, these models do not generalize to unseen data, often produce unfair results, and are difficult to interpret. This has led to efforts to improve the trustworthiness aspects of AI models. Recently, causal modeling and inference methods have emerged as powerful tools. This review aims to provide the reader with an overview of causal methods that have been developed to improve the trustworthiness of AI models. We hope that our contribution will motivate future research on causality-based solutions for trustworthy AI.
Multi-granular Legal Topic Classification on Greek Legislation
Sep 30, 2021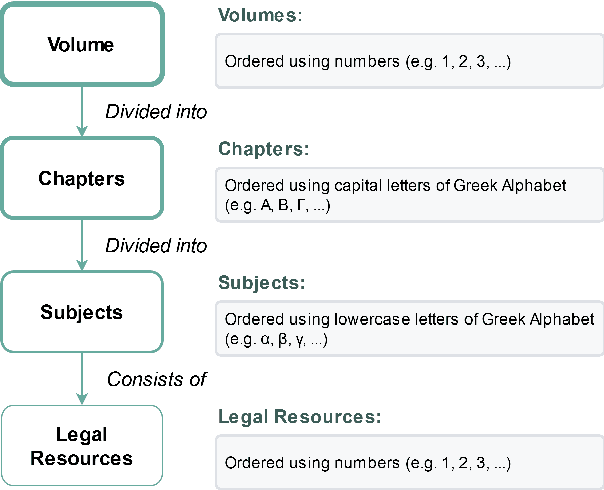
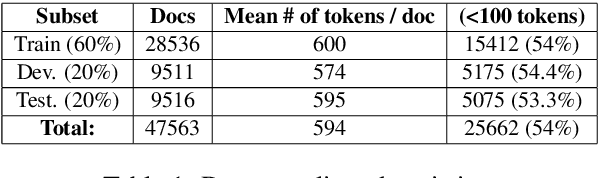
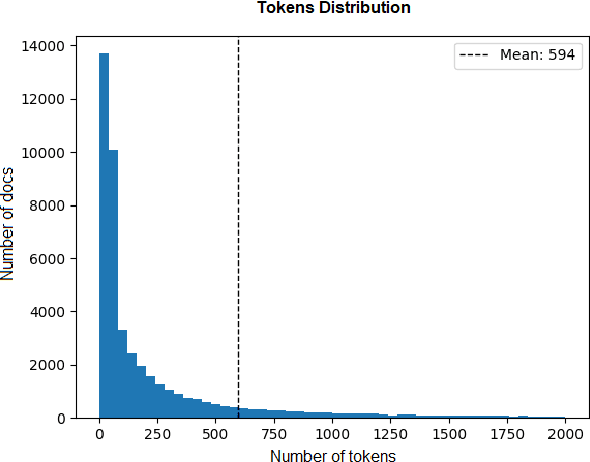
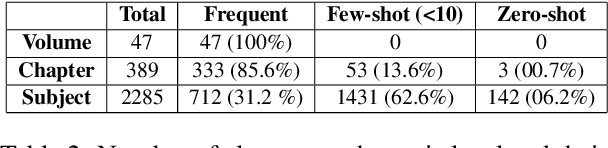
In this work, we study the task of classifying legal texts written in the Greek language. We introduce and make publicly available a novel dataset based on Greek legislation, consisting of more than 47 thousand official, categorized Greek legislation resources. We experiment with this dataset and evaluate a battery of advanced methods and classifiers, ranging from traditional machine learning and RNN-based methods to state-of-the-art Transformer-based methods. We show that recurrent architectures with domain-specific word embeddings offer improved overall performance while being competitive even to transformer-based models. Finally, we show that cutting-edge multilingual and monolingual transformer-based models brawl on the top of the classifiers' ranking, making us question the necessity of training monolingual transfer learning models as a rule of thumb. To the best of our knowledge, this is the first time the task of Greek legal text classification is considered in an open research project, while also Greek is a language with very limited NLP resources in general.