 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Personalization to Prejudice: Bias and Discrimination in Memory-Enhanced AI Agents for Recruitment
Dec 18, 2025Large Language Models (LLMs) have empowered AI agents with advanced capabilities for understanding, reasoning, and interacting across diverse tasks. The addition of memory further enhances them by enabling continuity across interactions, learning from past experiences, and improving the relevance of actions and responses over time; termed as memory-enhanced personalization. Although such personalization through memory offers clear benefits, it also introduces risks of bias. While several previous studies have highlighted bias in ML and LLMs, bias due to memory-enhanced personalized agents is largely unexplored. Using recruitment as an example use case, we simulate the behavior of a memory-enhanced personalized agent, and study whether and how bias is introduced and amplified in and across various stages of operation. Our experiments on agents using safety-trained LLMs reveal that bias is systematically introduced and reinforced through personalization, emphasizing the need for additional protective measures or agent guardrails in memory-enhanced LLM-based AI agents.
* In Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining (WSDM '26)
TIGQA:An Expert Annotated Question Answering Dataset in Tigrinya
Apr 26, 2024



The absence of explicitly tailored, accessible annotated datasets for educational purposes presents a notable obstacle for NLP tasks in languages with limited resources.This study initially explores the feasibility of using machine translation (MT) to convert an existing dataset into a Tigrinya dataset in SQuAD format. As a result, we present TIGQA, an expert annotated educational dataset consisting of 2.68K question-answer pairs covering 122 diverse topics such as climate, water, and traffic. These pairs are from 537 context paragraphs in publicly accessible Tigrinya and Biology books. Through comprehensive analyses, we demonstrate that the TIGQA dataset requires skills beyond simple word matching, requiring both single-sentence and multiple-sentence inference abilities. We conduct experiments using state-of-the art MRC methods, marking the first exploration of such models on TIGQA. Additionally, we estimate human performance on the dataset and juxtapose it with the results obtained from pretrained models.The notable disparities between human performance and best model performance underscore the potential for further enhancements to TIGQA through continued research. Our dataset is freely accessible via the provided link to encourage the research community to address the challenges in the Tigrinya MRC.
* 9 pages,3 figures, 7 tables,2 listings
A Review of the Role of Causality in Developing Trustworthy AI Systems
Feb 14, 2023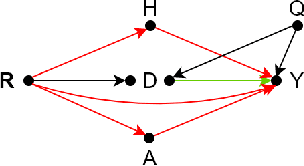
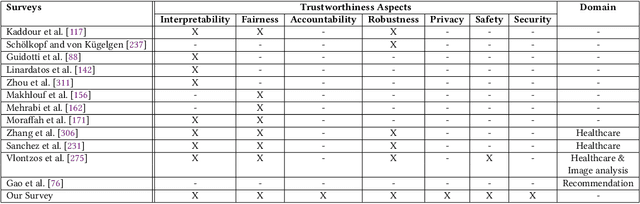
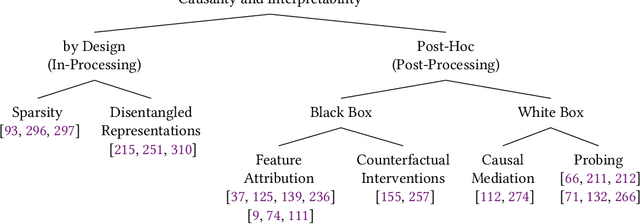
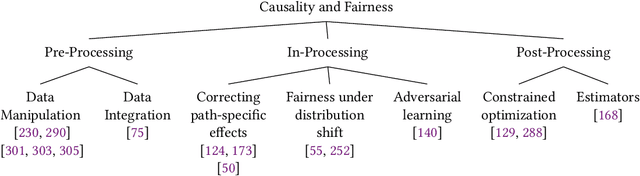
State-of-the-art AI models largely lack an understanding of the cause-effect relationship that governs human understanding of the real world. Consequently, these models do not generalize to unseen data, often produce unfair results, and are difficult to interpret. This has led to efforts to improve the trustworthiness aspects of AI models. Recently, causal modeling and inference methods have emerged as powerful tools. This review aims to provide the reader with an overview of causal methods that have been developed to improve the trustworthiness of AI models. We hope that our contribution will motivate future research on causality-based solutions for trustworthy AI.
Scheduling Virtual Conferences Fairly: Achieving Equitable Participant and Speaker Satisfaction
Apr 26, 2022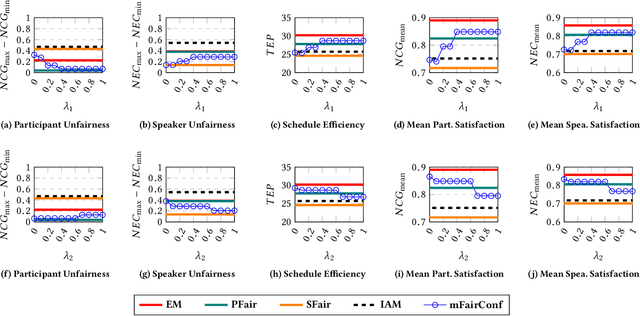
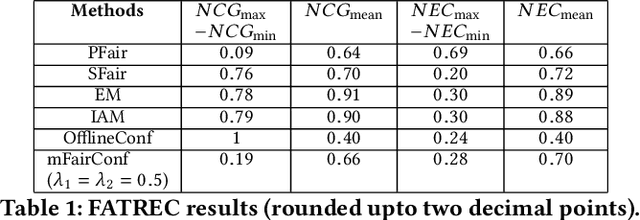
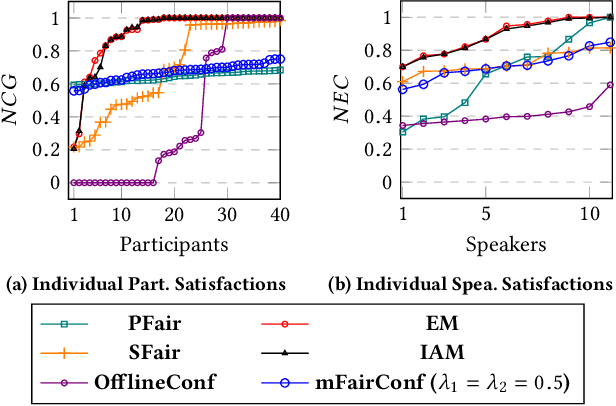
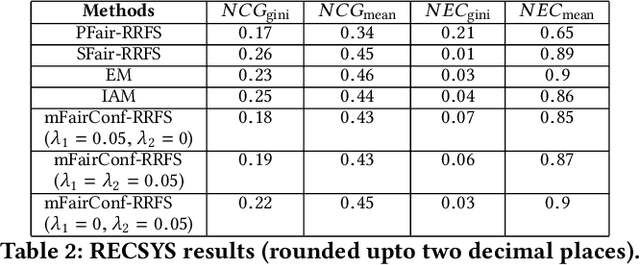
Recently, almost all conferences have moved to virtual mode due to the pandemic-induced restrictions on travel and social gathering. Contrary to in-person conferences, virtual conferences face the challenge of efficiently scheduling talks, accounting for the availability of participants from different timezones and their interests in attending different talks. A natural objective for conference organizers is to maximize efficiency, e.g., total expected audience participation across all talks. However, we show that optimizing for efficiency alone can result in an unfair virtual conference schedule, where individual utilities for participants and speakers can be highly unequal. To address this, we formally define fairness notions for participants and speakers, and derive suitable objectives to account for them. As the efficiency and fairness objectives can be in conflict with each other, we propose a joint optimization framework that allows conference organizers to design schedules that balance (i.e., allow trade-offs) among efficiency, participant fairness and speaker fairness objectives. While the optimization problem can be solved using integer programming to schedule smaller conferences, we provide two scalable techniques to cater to bigger conferences. Extensive evaluations over multiple real-world datasets show the efficacy and flexibility of our proposed approaches.
FairRec: Two-Sided Fairness for Personalized Recommendations in Two-Sided Platforms
Feb 25, 2020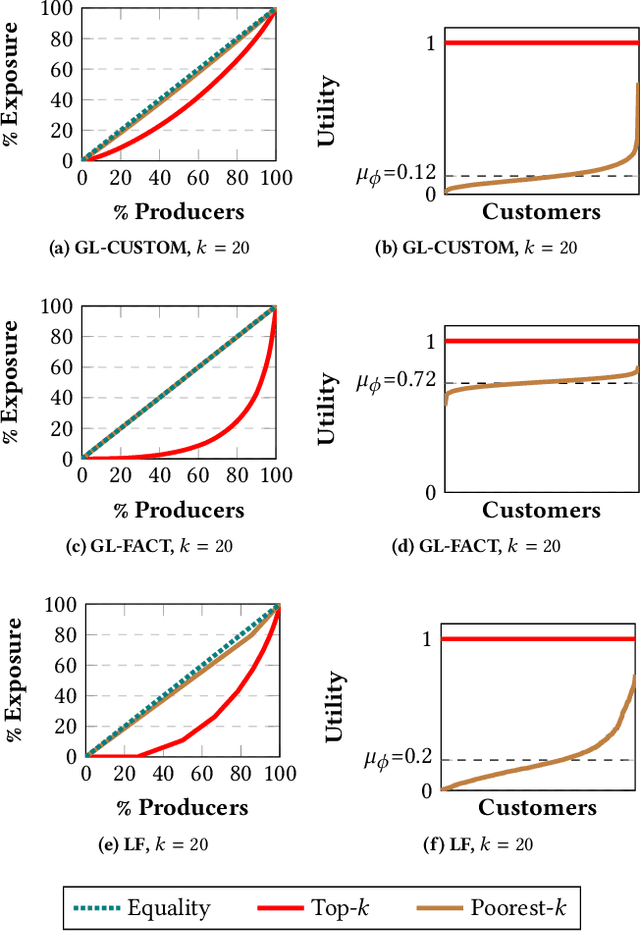
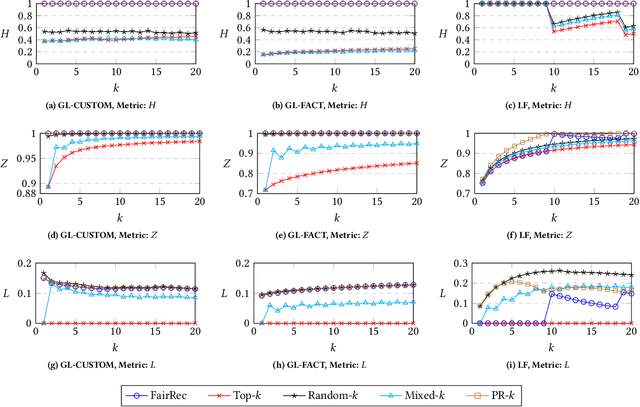
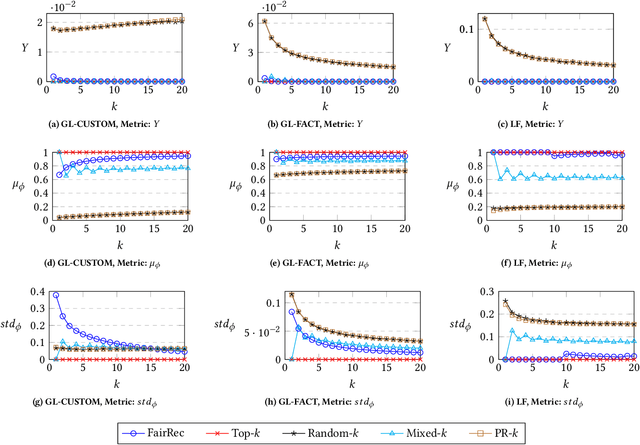
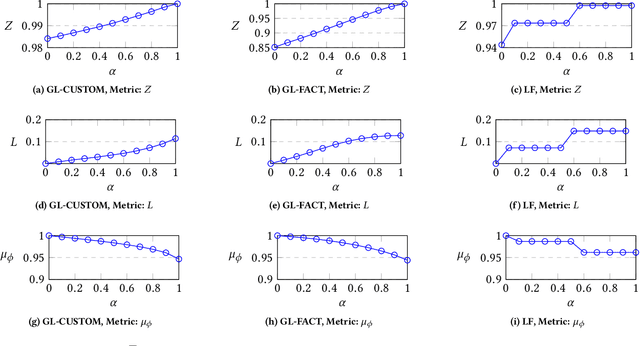
We investigate the problem of fair recommendation in the context of two-sided online platforms, comprising customers on one side and producers on the other. Traditionally, recommendation services in these platforms have focused on maximizing customer satisfaction by tailoring the results according to the personalized preferences of individual customers. However, our investigation reveals that such customer-centric design may lead to unfair distribution of exposure among the producers, which may adversely impact their well-being. On the other hand, a producer-centric design might become unfair to the customers. Thus, we consider fairness issues that span both customers and producers. Our approach involves a novel mapping of the fair recommendation problem to a constrained version of the problem of fairly allocating indivisible goods. Our proposed FairRec algorithm guarantees at least Maximin Share (MMS) of exposure for most of the producers and Envy-Free up to One item (EF1) fairness for every customer. Extensive evaluations over multiple real-world datasets show the effectiveness of FairRec in ensuring two-sided fairness while incurring a marginal loss in the overall recommendation quality.