 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraFormer: Automated Infrastructure-as-Code with LLMs Fine-Tuned via Policy-Guided Verifier Feedback
Jan 13, 2026Automating Infrastructure-as-Code (IaC) is challenging, and large language models (LLMs) often produce incorrect configurations from natural language (NL). We present TerraFormer, a neuro-symbolic framework for IaC generation and mutation that combines supervised fine-tuning with verifier-guided reinforcement learning, using formal verification tools to provide feedback on syntax, deployability, and policy compliance. We curate two large, high-quality NL-to-IaC datasets, TF-Gen (152k instances) and TF-Mutn (52k instances), via multi-stage verification and iterative LLM self-correction. Evaluations against 17 state-of-the-art LLMs, including ~50x larger models like Sonnet 3.7, DeepSeek-R1, and GPT-4.1, show that TerraFormer improves correctness over its base LLM by 15.94% on IaC-Eval, 11.65% on TF-Gen (Test), and 19.60% on TF-Mutn (Test). It outperforms larger models on both TF-Gen (Test) and TF-Mutn (Test), ranks third on IaC-Eval, and achieves top best-practices and security compliance.
RLSF: Reinforcement Learning via Symbolic Feedback
May 26, 2024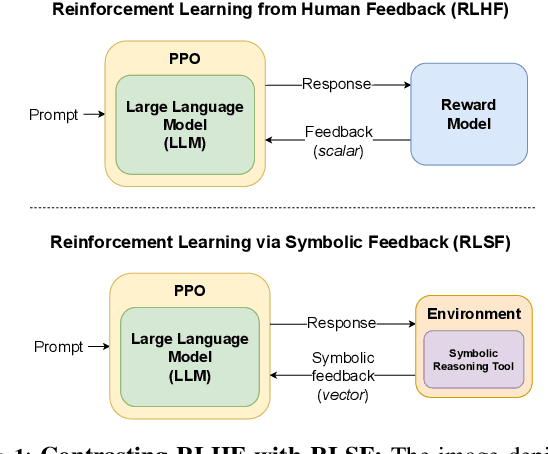
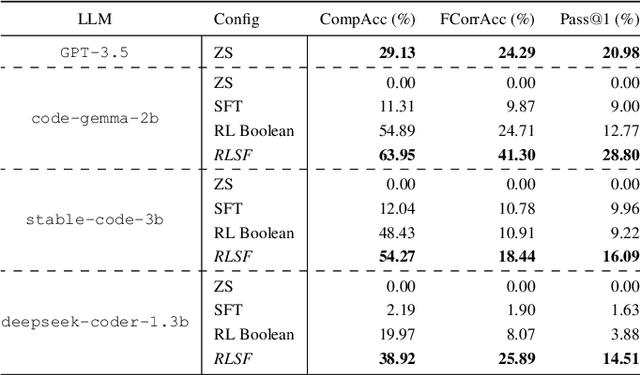


In recent years, large language models (LLMs) have had a dramatic impact on various sub-fields of AI, most notably on natural language understanding tasks. However, there is widespread agreement that the logical reasoning capabilities of contemporary LLMs are, at best, fragmentary (i.e., may work well on some problem instances but fail dramatically on others). While traditional LLM fine-tuning approaches (e.g., those that use human feedback) do address this problem to some degree, they suffer from many issues, including unsound black-box reward models, difficulties in collecting preference data, and sparse scalar reward values. To address these challenges, we propose a new training/fine-tuning paradigm we refer to as Reinforcement Learning via Symbolic Feedback (RLSF), which is aimed at enhancing the reasoning capabilities of LLMs. In the RLSF setting, the LLM that is being trained/fine-tuned is considered as the RL agent, while the environment is allowed access to reasoning or domain knowledge tools (e.g., solvers, algebra systems). Crucially, in RLSF, these reasoning tools can provide feedback to the LLMs via poly-sized certificates (e.g., proofs), that characterize errors in the LLM-generated object with respect to some correctness specification. The ability of RLSF-based training/fine-tuning to leverage certificate-generating symbolic tools enables sound fine-grained (token-level) reward signals to LLMs, and thus addresses the limitations of traditional reward models mentioned above. Via extensive evaluations, we show that our RLSF-based fine-tuning of LLMs outperforms traditional approaches on two different applications, namely, program synthesis from natural language pseudo-code to programming language (C++) and solving the Game of 24.
Attention, Compilation, and Solver-based Symbolic Analysis are All You Need
Jun 11, 2023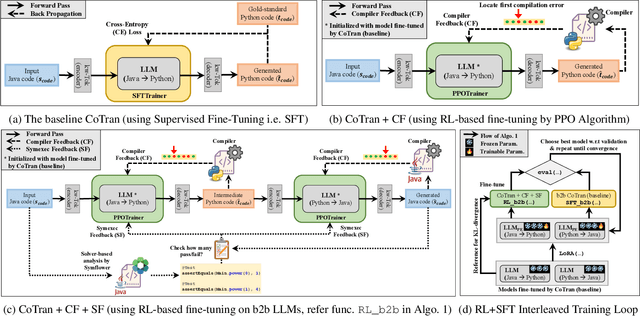
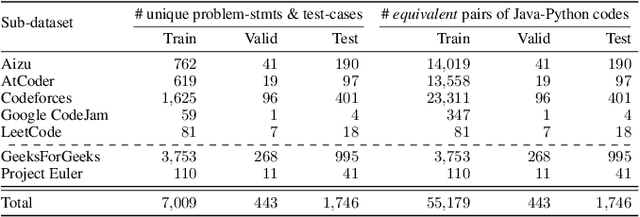
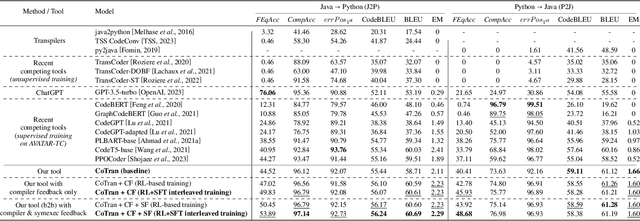
In this paper we present a Java-to-Python (J2P) and Python-to-Java (P2J) back-to-back code translation method, and associated tool called CoTran, based on large language models (LLMs). Our method leverages the attention mechanism of LLMs, compilation, and symbolic execution-based test generation for equivalence testing between the input and output programs. More precisely, we modify the typical LLM training loop to incorporate compiler and symbolic execution loss. Via extensive experiments comparing CoTran with 10 other transpilers and LLM-based translation tools over a benchmark of more than 57,000 Java-Python equivalent pairs, we show that CoTran outperforms them on relevant metrics such as compilation and runtime equivalence accuracy. For example, our tool gets 97.43% compilation accuracy and 49.66% runtime equivalence accuracy for J2P translation, whereas the nearest competing tool only gets 96.44% and 6.8% respectively.
Scheduling Virtual Conferences Fairly: Achieving Equitable Participant and Speaker Satisfaction
Apr 26, 2022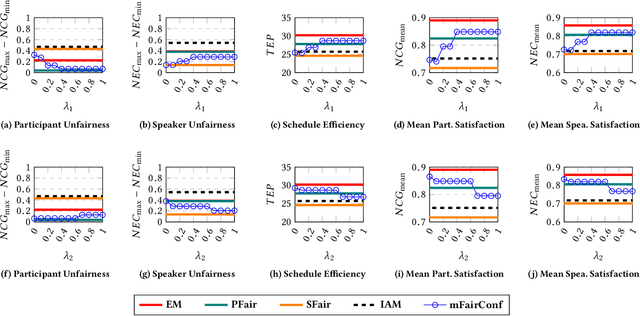
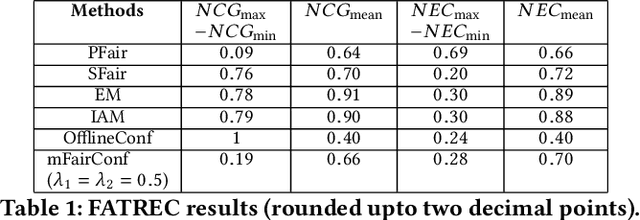
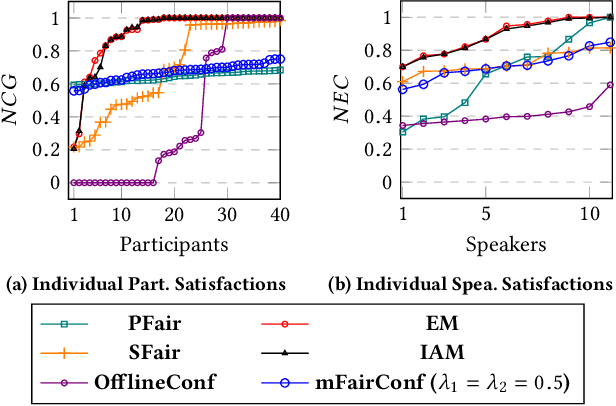
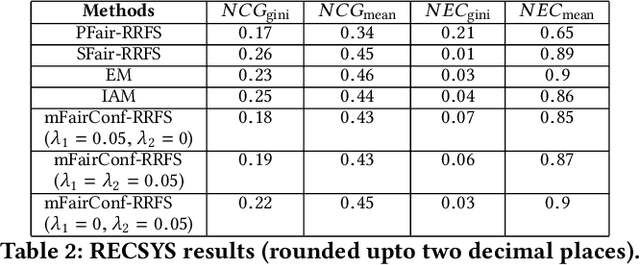
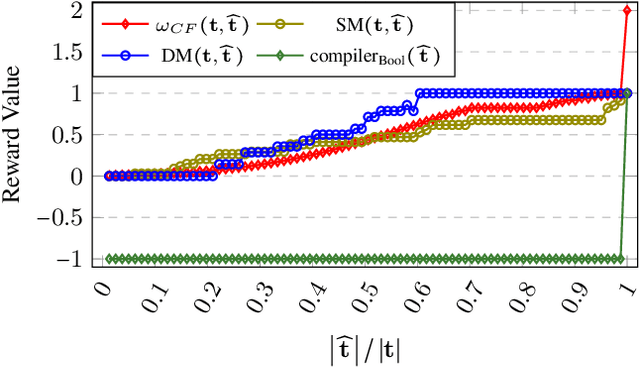
Recently, almost all conferences have moved to virtual mode due to the pandemic-induced restrictions on travel and social gathering. Contrary to in-person conferences, virtual conferences face the challenge of efficiently scheduling talks, accounting for the availability of participants from different timezones and their interests in attending different talks. A natural objective for conference organizers is to maximize efficiency, e.g., total expected audience participation across all talks. However, we show that optimizing for efficiency alone can result in an unfair virtual conference schedule, where individual utilities for participants and speakers can be highly unequal. To address this, we formally define fairness notions for participants and speakers, and derive suitable objectives to account for them. As the efficiency and fairness objectives can be in conflict with each other, we propose a joint optimization framework that allows conference organizers to design schedules that balance (i.e., allow trade-offs) among efficiency, participant fairness and speaker fairness objectives. While the optimization problem can be solved using integer programming to schedule smaller conferences, we provide two scalable techniques to cater to bigger conferences. Extensive evaluations over multiple real-world datasets show the efficacy and flexibility of our proposed approaches.
Recent Trends in 2D Object Detection and Applications in Video Event Recognition
Feb 07, 2022Object detection serves as a significant step in improving performance of complex downstream computer vision tasks. It has been extensively studied for many years now and current state-of-the-art 2D object detection techniques proffer superlative results even in complex images. In this chapter, we discuss the geometry-based pioneering works in object detection, followed by the recent breakthroughs that employ deep learning. Some of these use a monolithic architecture that takes a RGB image as input and passes it to a feed-forward ConvNet or vision Transformer. These methods, thereby predict class-probability and bounding-box coordinates, all in a single unified pipeline. Two-stage architectures on the other hand, first generate region proposals and then feed it to a CNN to extract features and predict object category and bounding-box. We also elaborate upon the applications of object detection in video event recognition, to achieve better fine-grained video classification performance. Further, we highlight recent datasets for 2D object detection both in images and videos, and present a comparative performance summary of various state-of-the-art object detection techniques.
Unsupervised Action Localization Crop in Video Retargeting for 3D ConvNets
Nov 22, 2021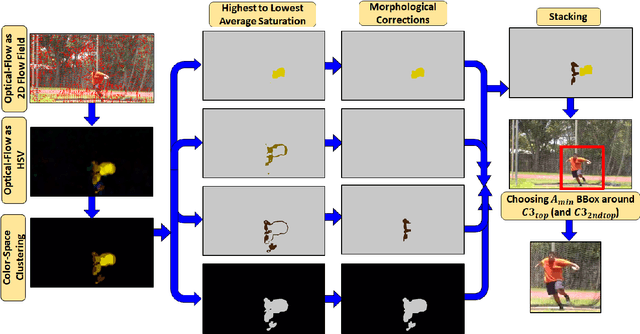
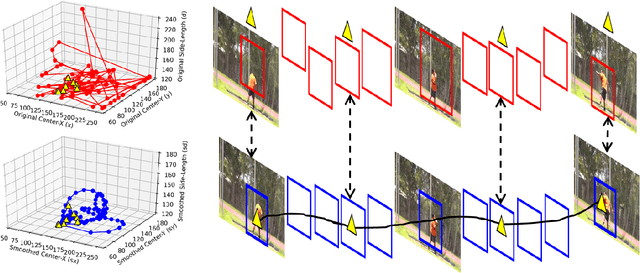

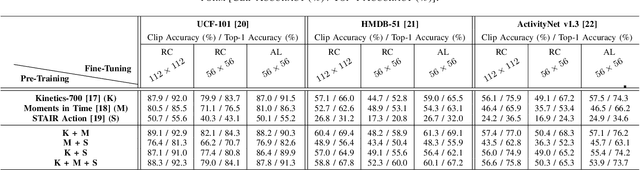
Untrimmed videos on social media or those captured by robots and surveillance cameras are of varied aspect ratios. However, 3D CNNs usually require as input a square-shaped video, whose spatial dimension is smaller than the original. Random- or center-cropping may leave out the video's subject altogether. To address this, we propose an unsupervised video cropping approach by shaping this as a retargeting and video-to-video synthesis problem. The synthesized video maintains a 1:1 aspect ratio, is smaller in size and is targeted at video-subject(s) throughout the entire duration. First, action localization is performed on each frame by identifying patches with homogeneous motion patterns. Thus, a single salient patch is pinpointed per frame. But to avoid viewpoint jitters and flickering, any inter-frame scale or position changes among the patches should be performed gradually over time. This issue is addressed with a polyBezier fitting in 3D space that passes through some chosen pivot timestamps and whose shape is influenced by the in-between control timestamps. To corroborate the effectiveness of the proposed method, we evaluate the video classification task by comparing our dynamic cropping technique with random cropping on three benchmark datasets, viz. UCF-101, HMDB-51 and ActivityNet v1.3. The clip and top-1 accuracy for video classification after our cropping, outperform 3D CNN performances for same-sized random-crop inputs, also surpassing some larger random-crop sizes.
Event and Activity Recognition in Video Surveillance for Cyber-Physical Systems
Nov 03, 2021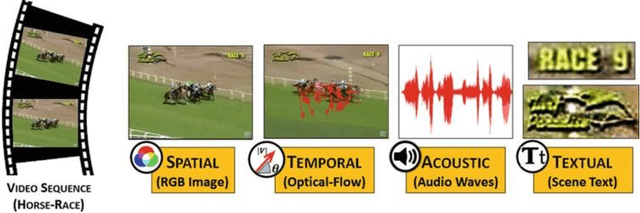
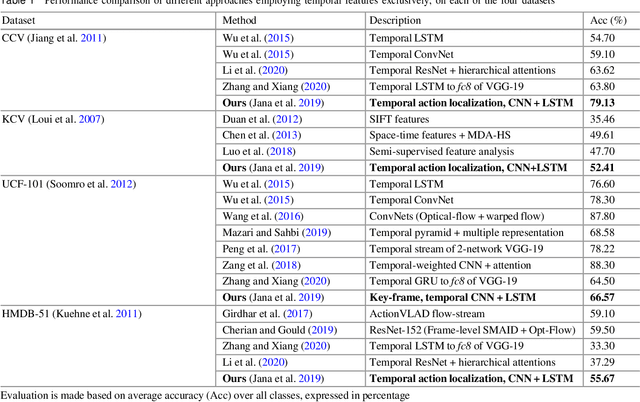

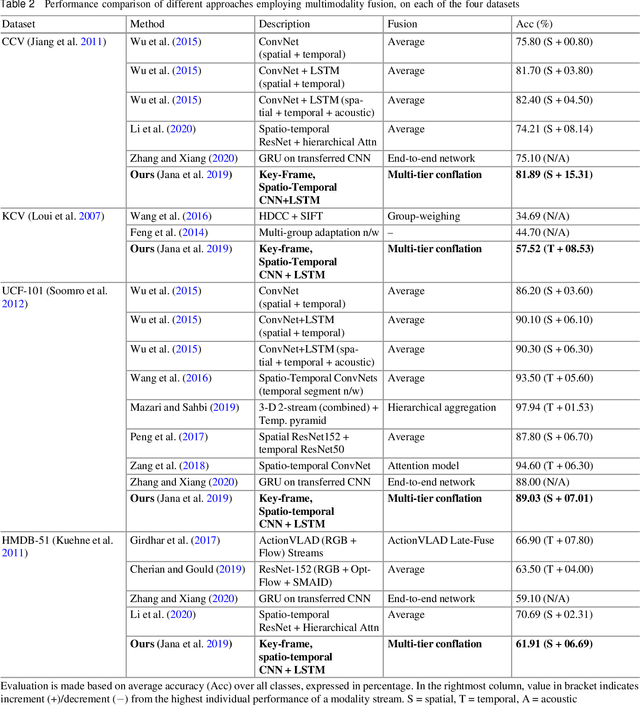
This chapter aims to aid the development of Cyber-Physical Systems (CPS) in automated understanding of events and activities in various applications of video-surveillance. These events are mostly captured by drones, CCTVs or novice and unskilled individuals on low-end devices. Being unconstrained, these videos are immensely challenging due to a number of quality factors. We present an extensive account of the various approaches taken to solve the problem over the years. This ranges from methods as early as Structure from Motion (SFM) based approaches to recent solution frameworks involving deep neural networks. We show that the long-term motion patterns alone play a pivotal role in the task of recognizing an event. Consequently each video is significantly represented by a fixed number of key-frames using a graph-based approach. Only the temporal features are exploited using a hybrid Convolutional Neural Network (CNN) + Recurrent Neural Network (RNN) architecture. The results we obtain are encouraging as they outperform standard temporal CNNs and are at par with those using spatial information along with motion cues. Further exploring multistream models, we conceive a multi-tier fusion strategy for the spatial and temporal wings of a network. A consolidated representation of the respective individual prediction vectors on video and frame levels is obtained using a biased conflation technique. The fusion strategy endows us with greater rise in precision on each stage as compared to the state-of-the-art methods, and thus a powerful consensus is achieved in classification. Results are recorded on four benchmark datasets widely used in the domain of action recognition, namely CCV, HMDB, UCF-101 and KCV. It is inferable that focusing on better classification of the video sequences certainly leads to robust actuation of a system designed for event surveillance and object cum activity tracking.
* This is a preprint of the chapter:S Bhaumik, P Jana, PP Mohanta, Event and Activity Recognition in Video Surveillance for Cyber-Physical Systems, published in Emergence of Cyber Physical System.., edited by KK Singh et al, 2021, Springer reproduced with permission of Springer Nature Switzerland AG. The final authenticated version is available online at http://dx.doi.org/10.1007/978-3-030-66222-6_4
AutoDrone: Shortest Optimized Obstacle-Free Path Planning for Autonomous Drones
Oct 30, 2021
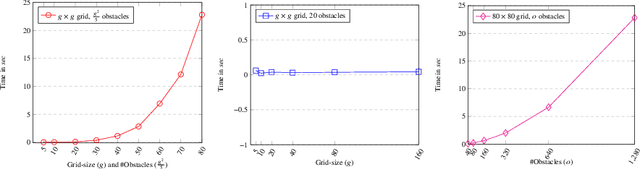
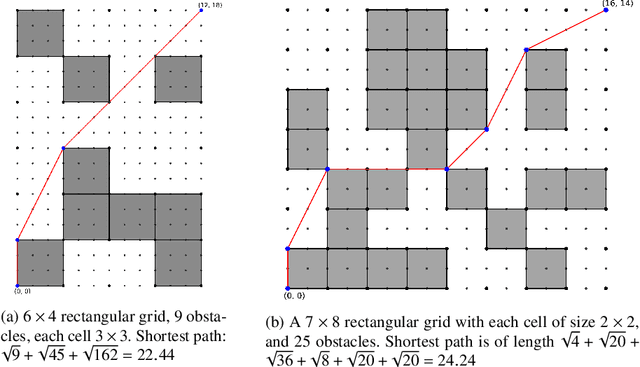
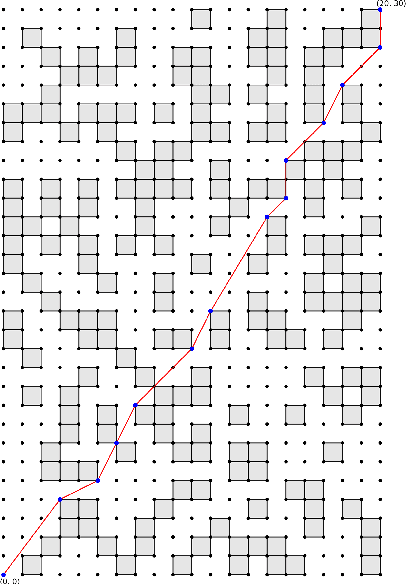
With technological advancement, drone has emerged as unmanned aerial vehicle that can be controlled by humans to fly or reach a destination. This may be autonomous as well, where the drone itself is intelligent enough to find a shortest obstacle-free path to reach the destination from a designated source. Be it a planned smart city or even a wreckage site affected by natural calamity, we may imagine the buildings, any surface-erected structure or other blockage as obstacles for the drone to fly in a direct line-of-sight path. So, the whole bird's eye-view of the landscape can be transformed to a graph of grid-cells, where some are occupied to indicate the obstacles and some are free to indicate the free path. The autonomous drone (AutoDrone) will be able to find out the shortest hindrance-free path while travelling in two-dimensional space and move from one place to another. In this paper, we propose a method to find out an obstacle-free shortest path in the coordinate system guided by GPS. This can be especially beneficial in rescue operations and fast delivery or pick-up in an energy-efficient way, where our algorithm will help in finding out the shortest path and angle along which it should fly. Our work shows different scenarios to path-tracing, through the shortest feasible path computed by the autonomous drone.